在 Apache Cassandra 中定義和優(yōu)化數據分區(qū)
速度和可擴展性是 Apache Cassandra 不變的追求;來學習一下如何充分發(fā)揮它的專長吧。
Apache Cassandra 是一個數據庫,但又不是一個簡單的數據庫;它是一個復制數據庫,專為可擴展性、高可用性、低延遲和良好性能而設計調整。Cassandra 可以幫你的數據在區(qū)域性中斷、硬件故障時,以及很多管理員認為數據量過多的情況下幸免于難。
全面掌握數據分區(qū)知識,你就能讓 Cassandra 集群實現良好的設計、極高的性能和可擴展性。在本文中,我將探究如何定義分區(qū),Cassandra 如何使用這些分區(qū),以及一些你應該了解的最佳實踐方案和已知問題。
基本概念是這樣的: 供數據庫關鍵函數(如數據分發(fā)、復制和索引化)使用的原子單元,單個這樣的數據塊就是一個分區(qū)。分布式數據系統(tǒng)通常會把傳入的數據分配到這些分區(qū)中,使用簡單的數學函數(例如 identity 或 hashing 函數)執(zhí)行分區(qū)過程,并用得到的 “分區(qū)鍵” 對數據分組,進一步再形成分區(qū)。例如,假設傳入數據是服務器日志,使用 “identity” 分區(qū)函數和每個日志的時間戳(四舍五入到小時值)作為分區(qū)鍵,我們可以對這些數據進行分區(qū),實現每個分區(qū)各保存一小時的日志的目的。
Cassandra 中的數據分區(qū)
Cassandra 作為分布式系統(tǒng)運行,并且符合前述數據分區(qū)原則。使用 Cassandra,數據分區(qū)依賴于在集群級別配置的算法和在表級別配置的分區(qū)鍵。
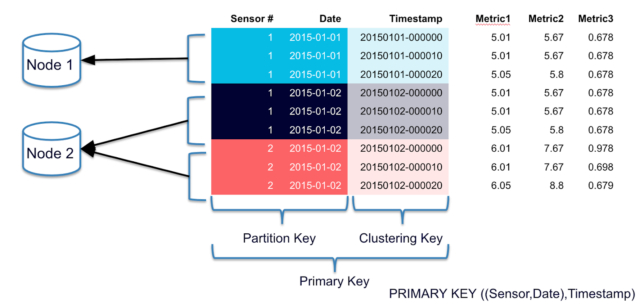
Cassandra data partition
Cassandra 查詢語言(CQL)使用大家很熟悉的 SQL 表、行、列等術語。在上面的示例圖中,表配置的主鍵中包含了分區(qū)鍵,具體格式為:主鍵 = 分區(qū)鍵 + [聚簇列] 。
Cassandra 中的主鍵既定義了唯一的數據分區(qū),也包含著分區(qū)內的數據排列依據信息。數據排列信息取決于聚簇列(非必需項)。每個唯一的分區(qū)鍵代表著服務器(包括其副本所在的服務器)中管理的若干行。
在 CQL 中定義主鍵
接下來的四個示例演示了如何使用 CQL 語法表示主鍵。定義主鍵會讓數據行分到不同的集合里,通常這些集合就是分區(qū)。
定義方式 1(分區(qū)鍵:log_hour,聚簇列:無)
CREATE TABLE server_logs(log_hour TIMESTAMP PRIMARYKEY,log_level text,message text,server text)
這里,有相同 log_hour 的所有行都會進入同一個分區(qū)。
定義方式 2(分區(qū)鍵:log_hour,聚簇列:log_level)
CREATE TABLE server_logs(log_hour TIMESTAMP,log_level text,message text,server text,PRIMARY KEY (log_hour, log_level))
此定義方式與方式 1 使用了相同的分區(qū)鍵,但此方式中,每個分區(qū)的所有行都會按 log_level 升序排列。
定義方式 3(分區(qū)鍵:log_hour,server,聚簇列:無)
CREATE TABLE server_logs(log_hour TIMESTAMP,log_level text,message text,server text,PRIMARY KEY ((log_hour, server)))
在此定義中,server 和 log_hour 字段都相同的行才會進入同一個分區(qū)。
定義方式 4(分區(qū)鍵:log_hour,server,聚簇列:log_level)
CREATE TABLE server_logs(log_hour TIMESTAMP,log_level text,message text,server text,PRIMARY KEY ((log_hour, server),log_level))WITH CLUSTERING ORDER BY (column3 DESC);
此定義方式與方式 3 分區(qū)相同,但分區(qū)內的行會依照 log_level 降序排列。
Cassandra 如何使用分區(qū)鍵
Cassandra 依靠分區(qū)鍵來確定在哪個節(jié)點上存儲數據,以及在需要時定位數據。Cassandra 通過查看表中的分區(qū)鍵來執(zhí)行這些讀取和寫入操作,并使用令牌(一個 -2^{63} 到 +2^{63}-1 范圍內的 long 類型值)來進行數據分布和索引。這些令牌通過分區(qū)器映射到分區(qū)鍵,分區(qū)器使用了將分區(qū)鍵轉換為令牌的分區(qū)函數。通過這種令牌機制,Cassandra 集群的每個節(jié)點都擁有一組數據分區(qū)。然后分區(qū)鍵在每個節(jié)點上啟用數據索引。
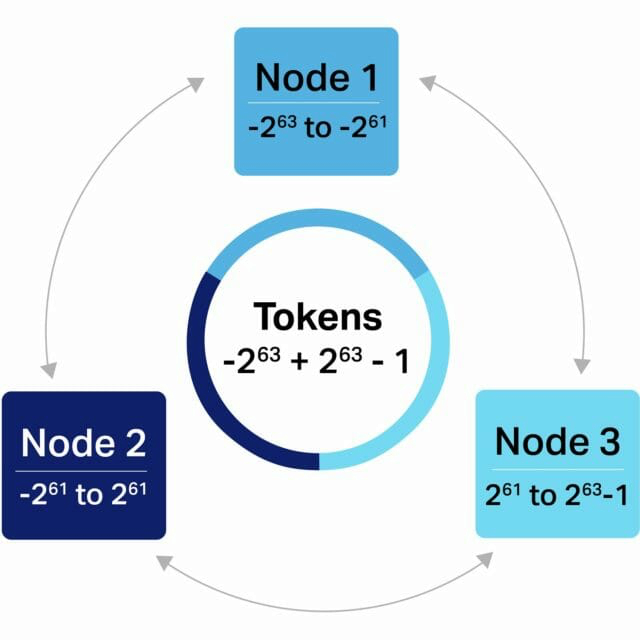
Cassandra cluster with 3 nodes and token-based ownership
圖中顯示了一個三節(jié)點的 Cassandra 集群以及相應的令牌范圍分配。這只是一個簡單的示意圖:具體實現過程使用了 Vnodes。
數據分區(qū)對 Cassandra 集群的影響
用心的分區(qū)鍵設計對于實現用例的理想分區(qū)大小至關重要。合理的分區(qū)可以實現均勻的數據分布和強大的 I/O 性能。分區(qū)大小對 Cassandra 集群有若干需要注意的影響:
- 讀取性能 —— 為了在磁盤上的 SSTables 文件中找到分區(qū),Cassandra 使用緩存、索引和索引摘要等數據結構。過大的分區(qū)會降低這些數據結構的維護效率,從而對性能產生負面影響。Cassandra 新版本在這方面取得了長足的進步:特別是 3.6 及其以上版本的 Cassandra 引擎引入了存儲改進,針對大型分區(qū),可以提供更好的性能,以及更強的應對內存問題和崩潰的彈性。
- 內存使用 —— 大分區(qū)會對 JVM 堆產生更大的壓力,同時分區(qū)的增大也降低了垃圾收集機制的效率。
- Cassandra 修復 —— 大分區(qū)使 Cassandra 執(zhí)行修復維護操作(通過跨副本比較數據來保持數據一致)時更加困難。
- “墓碑”刪除 —— 聽起來可能有點駭人,Cassandra 使用稱為“墓碑”的獨特標記來記錄要刪除的數據。如果沒有合適的數據刪除模式和壓縮策略,大分區(qū)會使刪除過程變得更加困難。
雖然這些影響可能會讓人更傾向于簡單地設計能產生小分區(qū)的分區(qū)鍵,但數據訪問模式對理想的分區(qū)大小也有很大影響(有關更多信息,請閱讀關于 Cassandra 數據建模 的深入講解)。數據訪問模式可以定義為表的查詢方式,包括表的所有 select 查詢。 理想情況下,CQL 選擇查詢應該在 where 子句中只使用一個分區(qū)鍵。也就是說,當查詢可以從單個分區(qū),而不是許多較小的分區(qū)獲取所需數據時,Cassandra 是最有效率的。
分區(qū)鍵設計的最佳實踐
遵循分區(qū)鍵設計的最佳實踐原則,這會幫你得到理想的分區(qū)大小。根據經驗,Cassandra 中的最大分區(qū)應保持在 100MB 以下。理想情況下,它應該小于 10MB。雖然 Cassandra 3.6 及其以上版本能更好地支持大分區(qū),但也必須對每個工作負載進行仔細的測試和基準測試,以確保分區(qū)鍵設計能夠支持所需的集群性能。
具體來說,這些最佳實踐原則適用于任何分區(qū)鍵設計:
- 分區(qū)鍵的目標必須是將理想數量的數據放入每個分區(qū),以支持其訪問模式的需求。
- 分區(qū)鍵應禁止無界分區(qū):那些大小可能隨著時間無限增長的分區(qū)。例如,在上面的
server_logs示例中,隨著服務器日志數量的不斷增加,使用服務器列作為分區(qū)鍵就會產生無界分區(qū)。相比之下,使用log_hour將每個分區(qū)限制為一個小時數據的方案會更好。 - 分區(qū)鍵還應避免產生分區(qū)傾斜,即分區(qū)增長不均勻,有些分區(qū)可能隨著時間的推移而不受限制地增長。在
server_logs示例中,在一臺服務器生成的日志遠多于其他服務器的情況下使用服務器列會產生分區(qū)傾斜。為了避免這種情況,可以從表中引入另一個屬性來強制均勻分布,即使要創(chuàng)建一個虛擬列來這樣做,也是值得的。 - 使用時間元素和其他屬性的組合分區(qū)鍵,這對時間序列數據分區(qū)很有幫助。這種方式可以防止無界分區(qū),使訪問模式能夠在查詢特定數據時使用時間屬性,而且能夠對特定時間段內的數據進行刪除。上面的每個示例都使用了
log_hour時間屬性來演示這一點。
還有一些工具可用于幫助測試、分析和監(jiān)控 Cassandra 分區(qū),以檢查所選模式是否高效。通過仔細設計分區(qū)鍵,使解決方案的數據和需求保持一致,并遵循最佳實踐原則來優(yōu)化分區(qū)大小,你就可以充分利用數據分區(qū),更好地發(fā)揮 Cassandra 的可擴展性和性能潛力。