













十張圖帶你徹底搞懂限流、熔斷、服務降級
在分布式系統中,如果某個服務節點發生故障或者網絡發生異常,都有可能導致調用方被阻塞等待,如果超時時間設置很長,調用方資源很可能被耗盡。這又導致了調用方的上游系統發生資源耗盡的情況,最終導致系統雪崩。
如下圖:
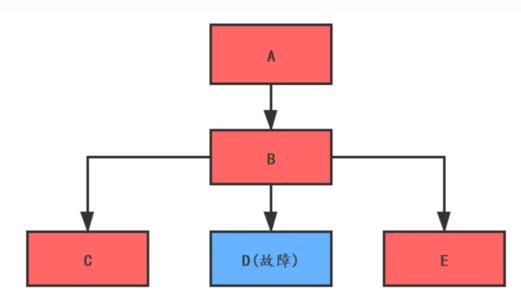
如果 D 服務發生了故障不能響應, B 服務調用 D 時只能阻塞等待。假如 B 服務調用 D 服務設置超時時間是 10 秒,請求速率是每秒 100 個,那 10 秒內就會有 1000 個請求線程被阻塞等待,如果 B 的線程池大小設置 1000 ,那 B 系統因為線程資源耗盡已經不能對外提供服務了。而這又影響了入口系統 A 的服務,最終導致系統全面崩潰。
提高系統的整體容錯能力是防止系統雪崩的有效手段。
在 Martin Fowler 和 James Lewis 的文章 《Microservices: a definition of this new architectural term》 [1] 中,提出了微服務的 9 個特征,其中一個是容錯設計。
要防止系統發生雪崩,就必須要有容錯設計。如果遇到突增流量,一般的做法是對非核心業務功能采用熔斷和服務降級的措施來保護核心業務功能正常服務,而對于核心功能服務,則需要采用限流的措施。
今天我們來聊一聊系統容錯中的限流、熔斷和服務降級。
當系統的處理能力不能應對外部請求的突增流量時,為了不讓系統奔潰,必須采取限流的措施。
1.1 限流指標
1.1.1 TPS
系統吞吐量是衡量系統性能的關鍵指標,按照事務的完成數量來限流是最合理的。
但是對實操性來說,按照事務來限流并不現實。在分布式系統中完成一筆事務需要多個系統的配合。比如我們在電商系統購物,需要訂單、庫存、賬戶、支付等多個服務配合完成,有的服務需要異步返回,這樣完成一筆事務花費的時間可能會很長。如果按照 TPS 來進行限流,時間粒度可能會很大大,很難準確評估系統的響應性能。
1.1.2 HPS
每秒請求數,指每秒鐘服務端收到客戶端的請求數量。
如果一個請求完成一筆事務,那 TPS 和 HPS 是等同的。但在分布式場景下,完成一筆事務可能需要多次請求,所以 TPS 和 HPS 指標不能等同看待。
1.1.3 QPS
服務端每秒能夠響應的客戶端查詢請求數量。
如果后臺只有一臺服務器,那 HPS 和 QPS 是等同的。但是在分布式場景下,每個請求需要多個服務器配合完成響應。
目前主流的限流方法多采用 HPS 作為限流指標。
1.2 限流方法
1.2.1 流量計數器
這是最簡單直接的方法,比如限制每秒請求數量 100 ,超過 100 的請求就拒絕掉。
但是這個方法存在 2 個明顯的問題:
-
單位時間(比如
1s)很難把控,如下圖:
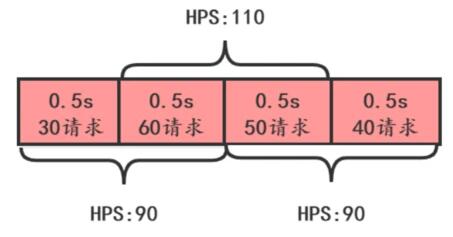
這張圖上,從下面時間看, HPS 沒有超過 100 ,但是從上面看 HPS 超過 100 了。
-
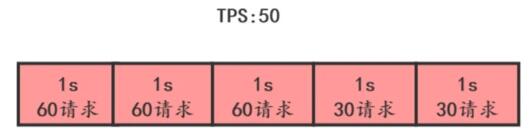
有一段時間流量超了,也不一定真的需要限流,如下圖,系統
HPS限制50,雖然前3s流量超了,但是如果讀超時時間設置為5s,并不需要限流。
1.2.2 滑動時間窗口
滑動時間窗口算法是目前比較流行的限流算法,主要思想是把時間看做是一個向前滾動的窗口,如下圖:
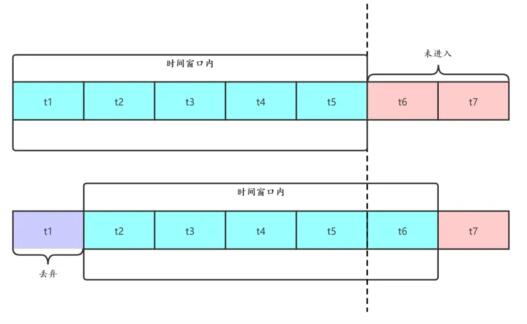
開始的時候,我們把 t1~t5 看做一個時間窗口,每個窗口 1s ,如果我們定的限流目標是每秒 50 個請求,那 t1~t5 這個窗口的請求總和不能超過 250 個。
這個窗口是滑動的,下一秒的窗口成了 t2~t6 ,這時把 t1 時間片的統計拋棄,加入 t6 時間片進行統計。這段時間內的請求數量也不能超過 250 個。
滑動時間窗口的優點是解決了流量計數器算法的缺陷,但是也有 2 個問題:
-
流量超過就必須拋棄或者走降級邏輯
-
對流量控制不夠精細,不能限制集中在短時間內的流量,也不能削峰填谷
1.2.3 漏桶算法
漏桶算法的思想如下圖:

在客戶端的請求發送到服務器之前,先用漏桶緩存起來,這個漏桶可以是一個長度固定的隊列,這個隊列中的請求均勻的發送到服務端。
如果客戶端的請求速率太快,漏桶的隊列滿了,就會被拒絕掉,或者走降級處理邏輯。這樣服務端就不會受到突發流量的沖擊。
漏桶算法的優點是實現簡單,可以使用消息隊列來削峰填谷。
但是也有 3 個問題需要考慮:
-
漏桶的大小,如果太大,可能給服務端帶來較大處理壓力,太小可能會有大量請求被丟棄。
-
漏桶給服務端的請求發送速率。
-
使用緩存請求的方式,會使請求響應時間變長。
漏桶大小和發送速率這 2 個值在項目上線初期都會根據測試結果選擇一個值,但是隨著架構的改進和集群的伸縮,這 2 個值也會隨之發生改變。
1.2.4 令牌桶算法
令牌桶算法就跟病人去醫院看病一樣,找醫生之前需要先掛號,而醫院每天放的號是有限的。當天的號用完了,第二天又會放一批號。
算法的基本思想就是周期性的執行下面的流程:
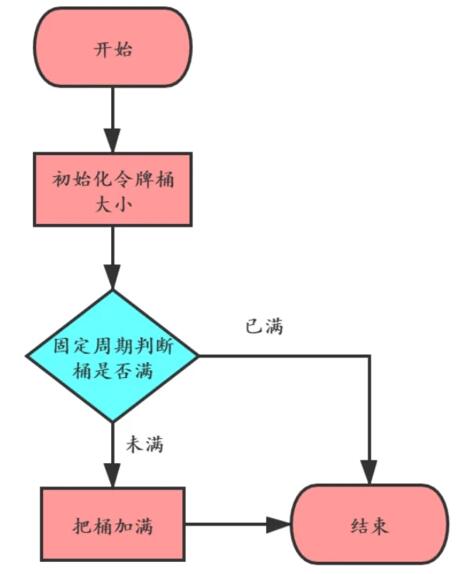
客戶端在發送請求時,都需要先從令牌桶中獲取令牌,如果取到了,就可以把請求發送給服務端,取不到令牌,就只能被拒絕或者走服務降級的邏輯。如下圖:
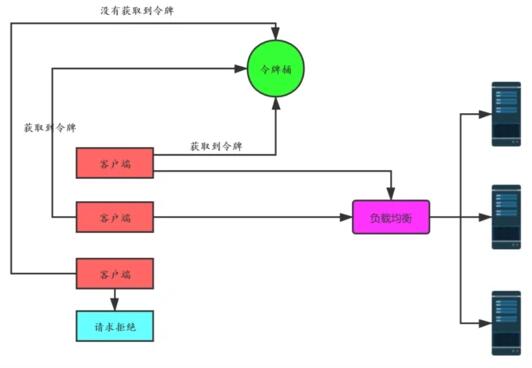
令牌桶算法解決了漏桶算法的問題,而且實現并不復雜,使用信號量就可以實現。在實際限流場景中使用最多,比如 google 的 guava 中就實現了令牌桶算法限流,感興趣可以研究一下。
1.2.5 分布式限流
如果在分布式系統場景下,上面介紹的 4 種限流算法是否還適用呢?
以令牌桶算法為例,假如在電商系統中客戶下了一筆訂單,如下圖:
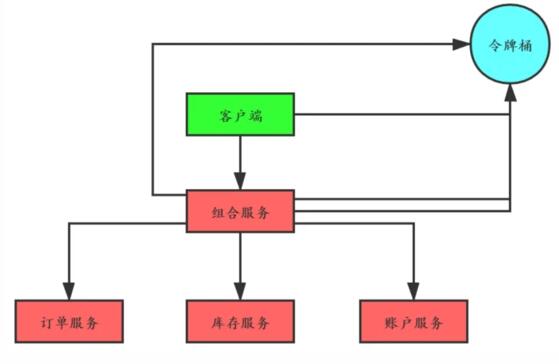
如果我們把令牌桶單獨保存在一個地方(比如 redis 中)供整個分布式系統用,那客戶端在調用組合服務,組合服務調用訂單、庫存和賬戶服務都需要跟令牌桶交互,交互次數明顯增加了很多。
有一種改進就是客戶端調用組合服務之前首先獲取四個令牌,調用組合服務時減去一個令牌并且傳遞給組合服務三個令牌,組合服務調用下面三個服務時依次消耗一個令牌。
1.2.6 hystrix限流
hystrix可以使用信號量和線程池來進行限流。
1.2.6.1 信號量限流
hystrix 可以使用信號量進行限流,比如在提供服務的方法上加下面的注解。這樣只能有20個并發線程來訪問這個方法,超過的就被轉到了errMethod這個降級方法。
- @HystrixCommand(
- commandProperties= {
- @HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE"),
- @HystrixProperty(name="execution.isolation.semaphore.maxConcurrentRequests", value="20")
- },
- fallbackMethod = "errMethod"
- )
1.2.6.2 線程池限流
hystrix 也可以使用線程池進行限流,在提供服務的方法上加下面的注解,當線程數量
- @HystrixCommand(
- commandProperties = {
- @HystrixProperty(name = "execution.isolation.strategy", value = "THREAD")
- },
- threadPoolKey = "createOrderThreadPool",
- threadPoolProperties = {
- @HystrixProperty(name = "coreSize", value = "20"),
- @HystrixProperty(name = "maxQueueSize", value = "100"),
- @HystrixProperty(name = "maximumSize", value = "30"),
- @HystrixProperty(name = "queueSizeRejectionThreshold", value = "120")
- },
- fallbackMethod = "errMethod"
- )
這里要注意:在 java 的線程池中,如果線程數量超過 coreSize ,創建線程請求會優先進入隊列,如果隊列滿了,就會繼續創建線程直到線程數量達到 maximumSize ,之后走拒絕策略。但在hystrix配置的線程池中多了一個參數 queueSizeRejectionThreshold ,如果 queueSizeRejectionThreshold < maxQueueSize ,隊列數量達到 queueSizeRejectionThreshold 就會走拒絕策略了,因此 maximumSize 失效了。如果 queueSizeRejectionThreshold > maxQueueSize ,隊列數量達到 maxQueueSize 時, maximumSize 是有效的,系統會繼續創建線程直到數量達到 maximumSize 。Hytrix線程池設置坑 [2]
相信大家對斷路器并不陌生,它就相當于一個開關,打開后可以阻止流量通過。比如保險絲,當電流過大時,就會熔斷,從而避免元器件損壞。
服務熔斷是指調用方訪問服務時通過斷路器做代理進行訪問,斷路器會持續觀察服務返回的成功、失敗的狀態,當失敗超過設置的閾值時斷路器打開,請求就不能真正地訪問到服務了。
為了更好地理解,我畫了下面的時序圖:
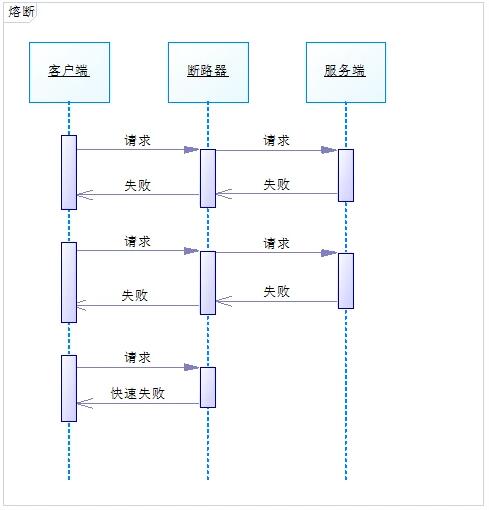
可以參考 Martin Fowler 的論文《CircuitBreaker》 [3] 。
2.1 斷路器的狀態
斷路器有 3 種狀態:
-
CLOSED:默認狀態。斷路器觀察到請求失敗比例沒有達到閾值,斷路器認為被代理服務狀態良好。 -
OPEN:斷路器觀察到請求失敗比例已經達到閾值,斷路器認為被代理服務故障,打開開關,請求不再到達被代理的服務,而是快速失敗。
- HALF OPEN
- CLOSED
- OPEN
斷路器的狀態切換圖如下:

2.2 需要考慮的問題
使用斷路器需要考慮一些問題:
-
針對不同的異常,定義不同的熔斷后處理邏輯。
-
設置熔斷的時長,超過這個時長后切換到
HALF OPEN進行重試。 -
記錄請求失敗日志,供監控使用。
- connection timeout
- telenet
- HALF OPEN
補償接口,斷路器可以提供補償接口讓運維人員手工關閉。
重試時,可以使用之前失敗的請求進行重試,但一定要注意業務上是否允許這樣做。
2.3 使用場景
-
服務故障或者升級時,讓客戶端快速失敗
-
失敗處理邏輯容易定義
-
響應耗時較長,客戶端設置的
read timeout會比較長,防止客戶端大量重試請求導致的連接、線程資源不能釋放
3 服務降級
前面講了限流和熔斷,相比來說,服務降級是站在系統全局的視角來考慮的。
在服務發生熔斷后,一般會讓請求走事先配置的處理方法,這個處理方法就是一個降級邏輯。
服務降級是對非核心、非關鍵的服務進行降級。
3.1 使用場景
-
服務處理異常,把異常信息直接反饋給客戶端,不再走其他邏輯
-
服務處理異常,把請求緩存下來,給客戶端返回一個中間態,事后再重試緩存的請求
-
監控系統檢測到突增流量,為了避免非核心業務功能耗費系統資源,關閉這些非核心功能
-
數據庫請求壓力大,可以考慮返回緩存中的數據
-
對于耗時的寫操作,可以改為異步寫
-
暫時關閉跑批任務,以節省系統資源
3.2 使用hystrix降級
3.2.1 異常降級
hystrix降級時可以忽略某個異常,在方法上加上 @HystrixCommand 注解:
下面的代碼定義降級方法是 errMethod ,對 ParamErrorException 和 BusinessTypeException 這兩個異常不做降級處理。
- @HystrixCommand(
- fallbackMethod = "errMethod",
- ignoreExceptions = {ParamErrorException.class, BusinessTypeException.class}
- )
3.2.2 調用超時降級
專門針對調用第三方接口超時降級。
下面的方法是調用第三方接口3秒未收到響應就降級到errMethod方法。
- @HystrixCommand(
- commandProperties = {
- @HystrixProperty(name="execution.timeout.enabled", value="true"),
- @HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds", value="3000"),
- },
- fallbackMethod = "errMethod"
- )
限流、熔斷和服務降級是系統容錯的重要設計模式,從一定意義上講限流和熔斷也是一種服務降級的手段。
熔斷和服務降級主要是針對非核心業務功能,而核心業務如果流程超過預估的峰值,就需要進行限流。
對于限流,選擇合理的限流算法很重要,令牌桶算法優勢很明顯,也是使用最多的限流算法。
在系統設計的時候,這些模式需要配合業務量的預估、性能測試的數據進行相應閾值的配置,而這些閾值最好保存在配置中心,方便實時修改。






















