談談Redis的持久化—AOF日志與RDB快照
一、前言
對于Mysql,數據是持久化在磁盤上的。如果誤刪數據,可以使用binlog進行恢復;突然宕機時,其本身可以借助redo log進行崩潰恢復。
更多關于Mysql日志的內容,可以參考我的另外一篇文章數據庫日志——binlog、redo log、undo log掃盲
而對于Redis,一般是把數據直接存儲在內存中。如果不做任何持久化工作,在出現宕機后,內存中的全部數據就會丟失。
顯然,業務方是不能容忍這樣的情況發生的。好在Redis提供了一系列的持久化機制,分別是AOF日志與RDB快照。
二、AOF
AOF全稱是Append Only File,Redis每次執行完一個寫類型的語句后,會將該語句以某種格式使用追加的方式順序寫入AOF日志中。
值得注意的是,AOF是默認不開啟的。
AOF日志的格式
以winows為例,進入到redis安裝目錄中的redis.windows.conf中,將appendonly的值修改為yes,即可開啟AOF
- # 默認關閉
- appendonly yes
- # AOF的默認文件名稱
- appendfilename "appendonly.aof"
當執行以下命令后
- set java helloworld
在appendonly.aof文件中,可以看到以下內容
- *3 代表當前命令有3個部分
- $3 第1部分命令的長度,3個字符
- set 第1部分命令
- $4 第2部分命令的長度,4個字符
- java 第2部分命令
- $10 第3部分命令的長度,10個字符
- helloworld 第3部分命令
當我們首次使用某個客戶端執行命令時,客戶端會自動幫我們補充select 0(即選擇編號0的數據庫),這個命令也會被保存在AOF日志中。
寫AOF日志的流程
大致的流程如圖所示
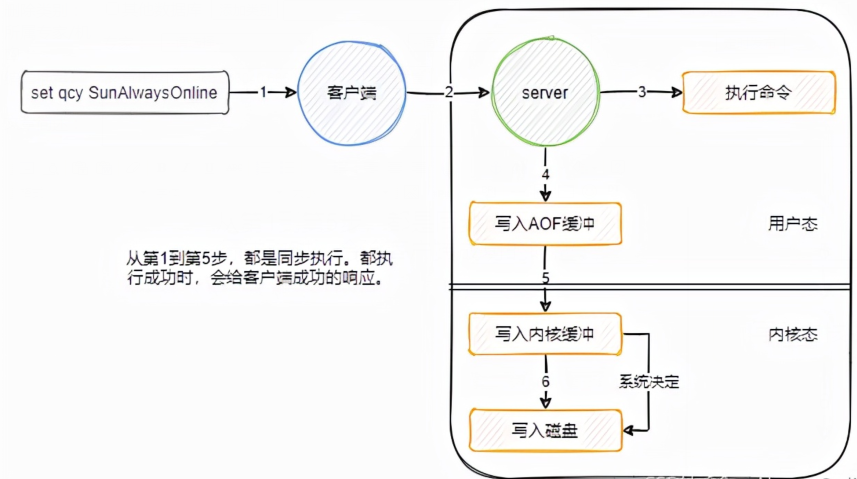
在server中,主線程執行完命令之后,會立即將命令寫入AOF緩沖中。之后會調用系統函數write(),將命令寫入內核緩沖區,并返回給客戶端成功的響應。
內核會在合適的時機將內核緩沖區的中的數據寫入到磁盤中。
我們設想其中某個階段宕機時,會不會產生不一致的情況:
1、如果命令執行成功,但寫入AOF緩存前崩潰重啟,客戶端會收到執行失敗或超時的響應。重啟之后AOF文件中沒有該條數據,這個時候,數據是一致的。
2、如果命令執行成功,寫入AOF緩存成功,但調用write時崩潰重啟。其實這種情況和第一條一樣,恢復后數據還是一致的。
3、如果命令執行、寫入AOF緩存與內核緩存都成功,客戶端會收到成功的響應。如果這個時候機器宕機,內核緩沖區中的數據將會丟失,也就是最后的AOF文件缺少該條命令,恢復后,就會產生數據不一致的情況。
第3種情況發生時,就會出現數據不一致的后果。怎么處理呢,很簡單啊,變異步為同步不就行了嗎。
調用write寫入內核緩沖區后,再調用fsync強制讓內核緩沖區中的數據刷到磁盤上,刷盤成功后,再返回給客戶端響應。
這樣的解決方式看似可以,但是刷盤的操作非常耗時。在Redis執行大量命令的時候,會一直進行不斷的刷盤,當磁盤壓力過大時,會阻塞下一個命令的執行,大大降低性能。
看來得把握刷盤的時機,刷得慢了,機器崩潰恢復后就會丟失大量數據。刷得快了,就會嚴重降低性能。
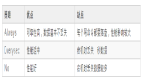
不過,Redis本身也提供了3種寫回策略。
寫回策略
- always 同步寫回。每執行一條命令,寫完AOF日志后,再返回。
- everysec 每秒寫回。執行命令后,將數據寫入到內核緩沖區就返回。只有會有一個線程,執行每秒刷盤的定時任務。
- no 由內核自行控制的寫回。每執行一條命令,將數據寫入到內核緩沖區就返回。內核會在合適的時機刷盤。
這3種策略體現了不同的刷盤頻率,因此擁有不同級別的一致性與性能。
always策略最大程度上保證數據不丟失,但性能最差。
no策略性能最好,但在機器崩潰重啟后會丟失比較多的數據。
everysec是一種折中的策略,較always有不錯的性能。在極端的情況下,只會丟失1秒內的數據,是比較推薦的方式。
redis.windows.conf中有appendfsync配置項,用來配置寫回策略,默認的策略是everysec 。
隨著Redis不斷記錄AOF日志,AOF日志文件將變得越來越大,用作恢復的時間也將越長。因此需要一種方式減少文件的大小,這時候AOF重寫就派上用場了。
AOF重寫
在出現觸發重寫的條件時(例如AOF文件達到某個閾值),Redis掃描整個庫的所有數據,將數據以命令的方式記錄在新的AOF日志中,待記錄完成后,使用新的AOF日志替換舊的即可。
舊日志中,可能存有對同一個key的多次操作命令,重寫的目的就是取最后一次有效的命令,刪除那些歷史命令,從而達到瘦身、壓縮的效果。
剛才提到,AOF重寫會掃描整個庫的數據,因此注定就是一個非常耗時的操作,那么就不會在主線程中做,而是通過主線程fork出一個子進程進行重寫的。
重寫的流程圖如下:
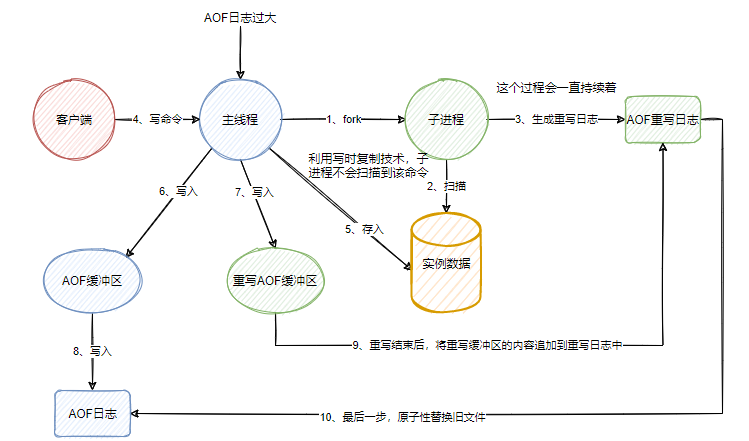
1、當AOF日志文件的大小超過執行的閾值后,就會觸發AOF重寫
2、主線程fork出一個子進程,fork的過程仍然是阻塞的。fork完之后,主線程依然可以接受命令并處理
3、子進程與主線程共享一個實例的所有數據,子進程會對整個實例進行掃描,將其中的數據以命令的格式寫入到重寫日志中。
4、在子進程重寫的過程中,主線程可以接受命令,假設這個時候執行了一條寫命令。
5、主線程會將數據存入到庫中,利用寫時復制技術,子進程不會感知到數據有任何變化。
6、主線程將日志先寫入AOF緩沖區,再寫入重寫緩沖區。
7、由特定寫回策略,將緩沖區中的數據寫入到舊的AOF日志中。
8、當子進程結束掃描,并且將所有命令寫入重寫日志后,再將重寫緩沖區中的數據追加到重寫日志中。
9、最后一步,主線程感知到子進程重寫日志完成,于是使用新的日志文件替換舊的文件。
也許有人會發出以下的疑問
為什么是fork出子進程,直接使用子線程不是也可以嗎?
如果是創建出來一個子線程,那么主線程在寫入,子線程在讀取,是需要通過加鎖的方式來保證線程安全的,加鎖就意味著降低性能。
而如果是fork出來子進程,主線程和子進程同樣需要共享數據,當主線程寫入數據的時候,會利用寫時復制技術,避免加鎖。
什么是寫時復制?
大家應該都知道三角函數吧,嗯,這和寫時復制沒什么關系。
CopyOnWriteArrayList就利用到了寫時復制,讀不加鎖,寫則是復制一份數組出來,在新的數組上進行修改,最后替換引用。非常適合應用于讀多寫少的場景,缺點是在替換引用前,線程讀到的是舊數據。
主線程在fork出一個子進程的時候,會將自己的頁表(虛擬地址與物理地址的映射表)復制一份出來給子進程,而不是直接復制內存。否則在重寫的時候,Redis占用內存會立即翻倍。
這樣的話,子進程就可以隨意訪問主線程中的數據。而當主線程修改一些實例數據時,就會復制一份物理內存出來,并變動主線程的頁表,在新的內存地址上存儲寫之后的數據。因為沒有變動子進程的頁表,因此主線程寫入的數據對子進程不可見。
重寫AOF緩沖區的作用是什么?
CopyOnWriteArrayList的缺點在于讀到的可能是舊數據,子進程在掃描的時候,其實掃描到的也是舊數據,因此需要在重寫結束后做補償。
子進程在重寫的過程中,掃描的數據是fork動作結束的那一刻的快照。而在重寫的過程中,主線程依然可以執行命令,那么這些多出來的寫命令就可以放在一個獨立的重寫緩沖區中。在重寫完成后,再將重寫緩沖區中的內容追加到重寫日志中,這就保證了數據的一致。
盡管存在AOF重寫機制,但重寫后的日志文件還是大,恢復速度較慢。
有沒有一種直接存儲數據,而不是存儲命令(命令的大小顯然大于數據本身)的方式呢?RDB就閃亮登場了!
三、RDB
RDB的全稱是Redis Database Backup,即數據備份。
會將某一時刻內的所有數據生成一個快照文件。該文件是一種經過壓縮的二進制文件,默認名稱為dump.rdb,可通過修改dbfilename參數來改變RDB文件名。
快照文件僅保存數據,不保存額外的操作命令,且經過壓縮,因此在恢復速度上快于AOF。但RDB沒法做到實時的持久化,而AOF可以基本做到。
如何讓Redis生成RDB文件
通過save命令手動觸發
直接在主線程中執行,會阻塞其他命令
通過bgsave命令手動觸發
主線程fork出來一個子進程,由子進程去執行備份。
整個fork的過程,是會阻塞主線程的。由于不會復制物理內存,因此fork是快速的。
fork結束后,主線程依然可以執行其他的命令。
通過配置自動觸發
redis.windows.conf中有如下的幾個配置可用于觸發生成RDB文件
- # 900秒內至少出現1條寫命令就觸發
- save 900 1
- # 300秒內至少出現10條寫命令就觸發
- save 300 10
- # 60秒內至少出現10000條寫命令就觸發
- save 60 10000
這種方式,也是通過fork出一個子進程來做的。
三種方式的觸發流程
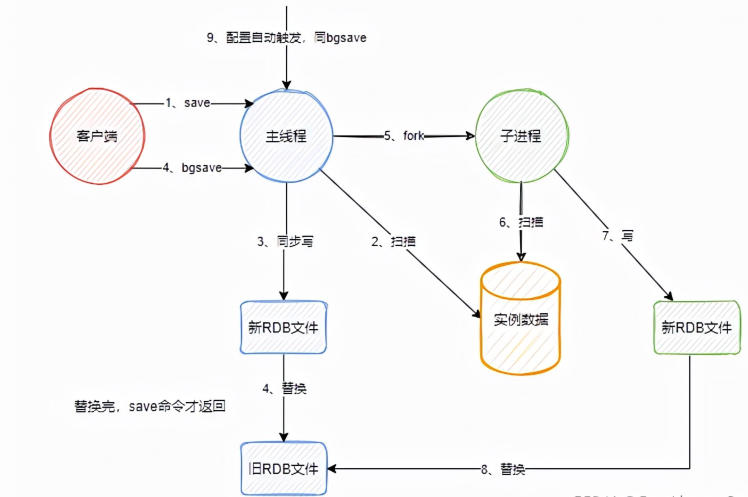
客戶端使用bgsave命令時,主線程fork出來子進程,由子進程完成備份。
在子進程備份期間,主線程依然可以執行命令。但該條數據并不會被子進程掃描到,和AOF重寫一樣,都利用到了寫時復制。
既然RDB文件占用小,恢復速度快,那可以大幅增加RDB生成的頻率嗎?
那顯然是不可以的,有可能上一輪RDB還未生成,下一輪又開始了。而且也存在性能問題,save全程都會阻塞主線程,bgsave的fork操作同樣也會阻塞主線程。
當然,RDB這種方式,如果在持久化的過程中發生宕機,會丟失在上次備份之后產生的所有數據。
四、AOF與RDB的特點總結
下面使用一張表格來直觀地展示兩者之間的優缺點
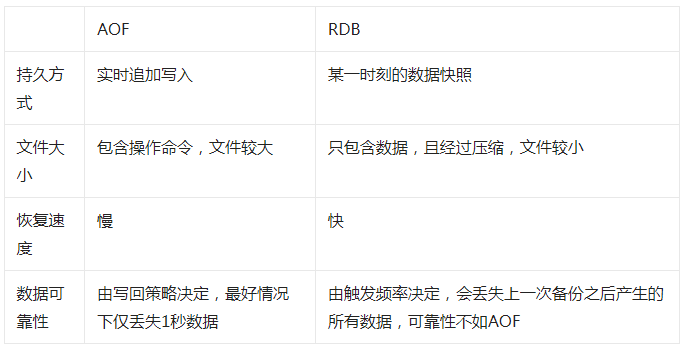
另外值得注意的是,當同時開啟AOF與RDB時,Redis會優先使用AOF日志來恢復數據。
RDB相比而言,會丟失較多的數據。AOF只有在實例數據比較大的時候,恢復速度才慢。
五、Redis4.0混合持久化模式
既然AOF與RDB獨有各自的優勢,能否結合二者的特點呢?
在Redis4.0中,出現了一個新的模式——混合持久化。具體來講,就是全量RDB+增量AOF,將兩種類型的日志文件存放在一起。
RDB可以以較低的頻率執行,兩次RDB之間的產生的增量數據記錄在AOF日志中,因此增量AOF日志的文件很小。
因此Redis在恢復時,先加載RDB數據,再重放增量的AOF日志。不需要像之前重放全量AOF日志,因此恢復效率大大提升。