LongAdder ,這哥們勁兒大
我們?cè)谥暗奈恼轮薪榻B到了 AtomicLong ,如果你還不了解,我建議你閱讀一下這篇文章
一場(chǎng) Atomic XXX 的魔幻之旅
為什么我要先說(shuō) AtomicLong 呢?因?yàn)?LongAdder 的設(shè)計(jì)是根據(jù) AtomicLong 的缺陷來(lái)設(shè)計(jì)的。
為什么引入 LongAdder
我們知道,AtomicLong 是利用底層的 CAS 操作來(lái)提供并發(fā)性的,比如 addAndGet 方法
- public final long addAndGet(long delta) {
- return unsafe.getAndAddLong(this, valueOffset, delta) + delta;
- }
我們還知道,CAS 是一種輕量級(jí)的自旋方法,它的邏輯是采用自旋的方式不斷更新目標(biāo)值,直到更新成功。(也即樂(lè)觀鎖的實(shí)現(xiàn)模式)
在并發(fā)數(shù)量比較低的場(chǎng)景中,線(xiàn)程沖突的概率比較小,自旋的次數(shù)不會(huì)很多。但是,在并發(fā)數(shù)量激增的情況下,會(huì)出現(xiàn)大量失敗并不斷自旋的場(chǎng)景,此時(shí) AtomicLong 的自旋次數(shù)很容易會(huì)成為瓶頸。
為了解決這種缺陷,引入了本篇文章的主角 --- LongAdder,它主要解決高并發(fā)環(huán)境下 AtomictLong 的自旋瓶頸問(wèn)題。
認(rèn)識(shí) LongAdder
我們先看一下 JDK 源碼中關(guān)于 LongAdder 的討論

這段話(huà)很清晰的表明,在多線(xiàn)程環(huán)境下,如果業(yè)務(wù)場(chǎng)景更側(cè)重于統(tǒng)計(jì)數(shù)據(jù)或者收集信息的話(huà),LongAdder 要比 AtomicLong 有更好的性能,吞吐量更高,但是會(huì)占用更多的內(nèi)存。在并發(fā)數(shù)量較低或者單線(xiàn)程場(chǎng)景中,AtomicLong 和 LongAdder 具有相同的特征,也就是說(shuō),在上述場(chǎng)景中,AtomicLong 和 LongAdder 可以互換。
首先我們先來(lái)看一下 LongAdder類(lèi)的定義:
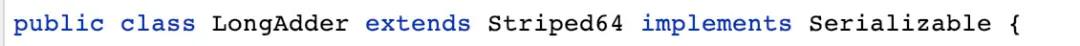
可以看到,LongAdder 繼承于 Striped64類(lèi),并實(shí)現(xiàn)了 Serializable 接口。
Striped64 又是繼承于 Number 類(lèi),現(xiàn)在你可能不太清楚 Striped64 是做什么的,但是你別急。
我們知道,Number 類(lèi)是基本數(shù)據(jù)類(lèi)型的包裝類(lèi)以及原子性包裝類(lèi)的父類(lèi),繼承 Number 類(lèi)表示它可以當(dāng)作數(shù)值進(jìn)行處理,然而這樣并不能說(shuō)明什么,它對(duì)我們來(lái)說(shuō)還是一頭霧水,隨后我翻了翻 Striped64 的繼承體系,發(fā)現(xiàn)這個(gè)類(lèi)有幾個(gè)實(shí)現(xiàn),而這幾個(gè)實(shí)現(xiàn)能夠很好的幫助我們理解什么是 Striped64。
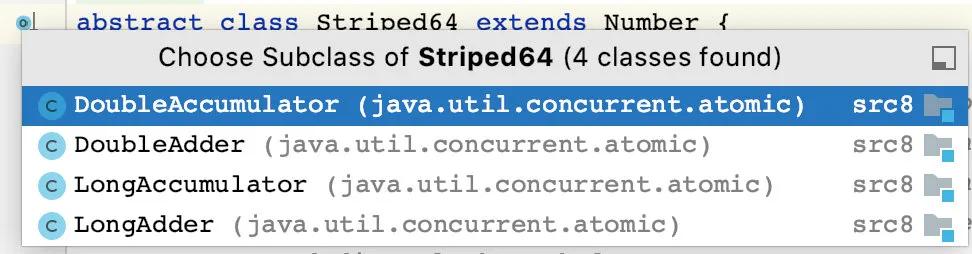
在其中我們看到了 Accumulator,它的中文概念就是累加器,所以我們猜測(cè) Striped64 也能實(shí)現(xiàn)累加的功能。果不其然,在我求助了部分帖子之后,我們可以得出來(lái)一個(gè)結(jié)論:Striped64 就是一個(gè)支持 64 位的累加器。
但是那兩個(gè) Accumulator 的實(shí)現(xiàn)可以實(shí)現(xiàn)累加,這個(gè)好理解,但是這兩個(gè) Adder 呢?它們也能實(shí)現(xiàn)累加的功能嗎?
我們?cè)俅渭?xì)致的查看一下 LongAdder 和 DoubleAdder 的源碼(因?yàn)檫@兩個(gè)類(lèi)非常相似)。
(下面的敘事風(fēng)格主要以 LongAdder 為準(zhǔn),DoubleAdder 會(huì)兼帶著聊一下,但不是主要敘事對(duì)象,畢竟這兩個(gè)類(lèi)的基類(lèi)非常相似。)
在翻閱一波源碼過(guò)后,我們發(fā)現(xiàn)了一些方法,比如 increment、decrement、add、reset、sum等,這些方法看起來(lái)好像是一個(gè)累加器所擁有的功能。
在詳細(xì)翻閱源碼后,我認(rèn)證了我的想法,因?yàn)?increment 、decrement 都是調(diào)用的 add 方法,而 add 方法底層則使用了 longAccmulate,我給你畫(huà)個(gè)圖你就知道了。
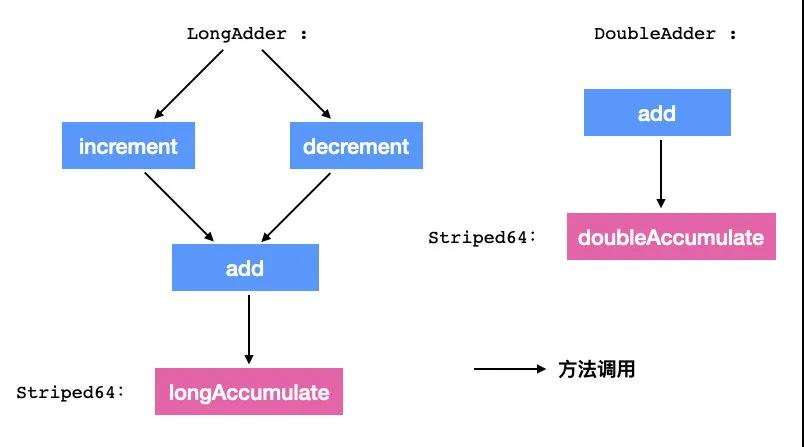
所以,LongAdder 的第一個(gè)特性就是可以處理數(shù)值,而實(shí)現(xiàn)了 Serializable 這個(gè)接口表示 LongAdder 可以序列化,以便存儲(chǔ)在文件中或在網(wǎng)絡(luò)上傳輸。
然后我們繼續(xù)往下走,現(xiàn)在時(shí)間的羅盤(pán)指向了 LongAdder 的 add 方法,我們腦子里面已經(jīng)有印象,這個(gè) LongAdder 方法是來(lái)做并發(fā)累加的,所以這個(gè) add 方法如果不出意外就是并發(fā)的累加方法,那么很奇怪了,這個(gè)方法為什么沒(méi)有使用 synchronized 呢?
我們繼續(xù)觀察 add 方法都做了哪些操作。
開(kāi)始時(shí)就是分配了一些變量而已啊,這也沒(méi)什么特殊的,繼續(xù)看到第二行的時(shí)候,我們發(fā)現(xiàn)有一個(gè) cells 對(duì)象,這個(gè) cells 對(duì)象是個(gè)數(shù)組,好像是個(gè)全局的。。。。。。那么在哪里定義的呢?
一想到還有個(gè) Striped64 這個(gè)類(lèi),果斷點(diǎn)進(jìn)去看到了這個(gè)全局變量,另外,Striped64 這個(gè)類(lèi)很重要,我們可不能把它忘了。
在 Striped64 類(lèi)中,赫然出現(xiàn)了下面這三個(gè)重要的全局變量。

由 transient 修飾的這三個(gè)全局變量,會(huì)保證不會(huì)被序列化。
我們先不解釋這三個(gè)變量是什么,有什么用,因?yàn)槲覀儎倓倲]到了 add 方法,所以還是回到 add 方法上來(lái):
繼續(xù)向下走,我們看到了 caseBase 方法,這個(gè)方法又是干什么的?點(diǎn)進(jìn)去,發(fā)現(xiàn)還是 Striped64 中的方法,現(xiàn)在,我們陷入了沉思。
我們上面只是知道了 Striped64 是一個(gè)累加器,但是我現(xiàn)在要不要擼一遍 Striped64 的源碼??????
認(rèn)識(shí) Striped64
果然出來(lái)混都是要還的,上面沒(méi)有介紹的 Striped64 的三個(gè)變量,現(xiàn)在就要好好介紹一波了。
- cells 它是一個(gè)數(shù)組,如果不是 null ,它的大小就是 2 的次方。
- base 是 Striped64 的基本數(shù)值,主要在沒(méi)有爭(zhēng)用時(shí)使用,同時(shí)也作為 cells 初始化時(shí)使用,使用 CAS 進(jìn)行更新。
- cellsBusy 它是一個(gè) SpinLock(自旋鎖),在初始化 cells 時(shí)使用。
除了這三個(gè)變量之外,還有一個(gè)變量,我竟然把它忽視了,罪過(guò)罪過(guò)。

它表示的是 CPU 的核數(shù)。
好像并沒(méi)有看出來(lái)什么玄機(jī),接著往下走
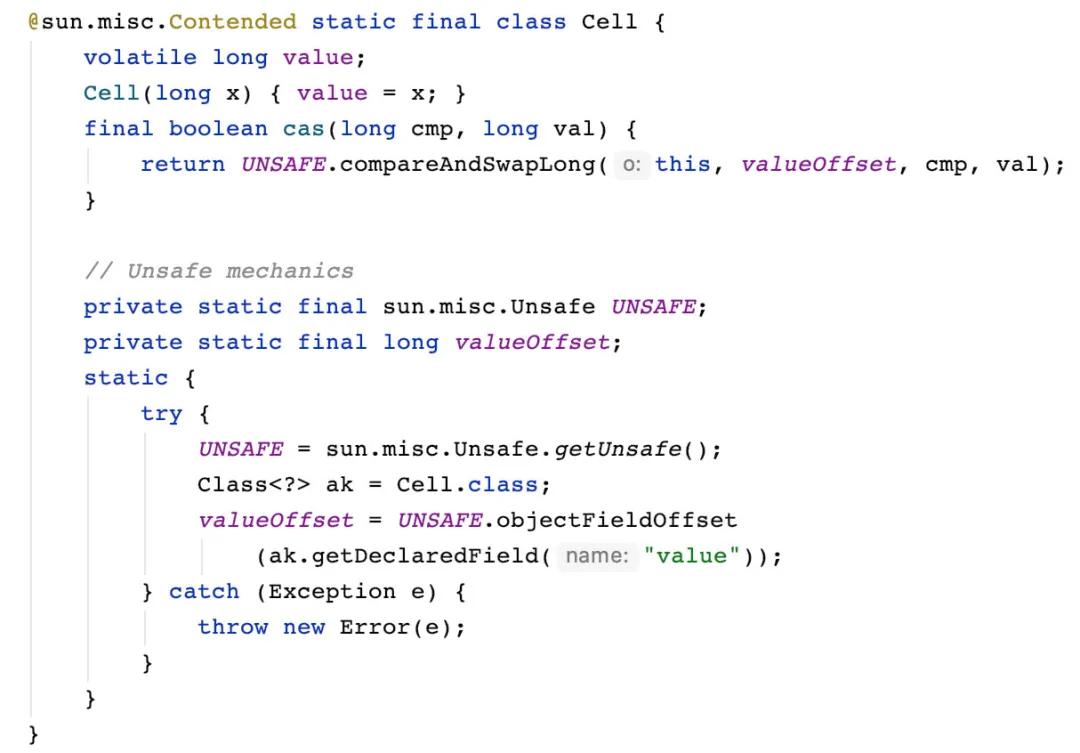
這里出現(xiàn)了一個(gè) Cell 元素的內(nèi)部類(lèi),里面出現(xiàn)了 long 型的 value 值,cas 方法,UNSAFE,valueOffSet 元素,如果你看過(guò)我的這篇文章 Atomic 原子工具類(lèi)詳解 或者你了解 AtomicLong 的設(shè)計(jì)的話(huà),你就知道,Cell 的設(shè)計(jì)是和 AtomicLong 完全一樣的,都是使用了 volatile 變量、Unsafe 加上字段的偏移量,再用 CAS 進(jìn)行修改。
而這個(gè) Cell 元素,就是 cells 數(shù)組中的每個(gè)對(duì)象。
這里比較特殊的是 @sun.misc.Contended 注解,它是 Java 8 中新增的注解,用來(lái)避免緩存的偽共享,減少 CPU 緩存級(jí)別的競(jìng)爭(zhēng)。
害,就這?
先不要著急,Striped64 最核心的功能是分別為 LongAdder 和 DoubleAdder 提供并發(fā)累加的功能,所以 Striped64 中的 longAccumulate 和 doubleAccumulate 才是關(guān)鍵,我們主要介紹 longAccumulate 方法,方法比較長(zhǎng),我們慢慢進(jìn)入節(jié)奏。
最關(guān)鍵的 longAccumulate
先貼出來(lái) longAccumulate 的完整代碼,然后我們?cè)龠M(jìn)行分析:
- final void longAccumulate(long x, LongBinaryOperator fn,
- boolean wasUncontended) {
- // 獲取線(xiàn)程的哈希值
- int h;
- if ((h = getProbe()) == 0) {
- ThreadLocalRandom.current(); // force initialization
- h = getProbe();
- wasUncontended = true;
- }
- boolean collide = false; // True if last slot nonempty
- for (;;) {
- Cell[] as; Cell a; int n; long v;
- if ((as = cells) != null && (n = as.length) > 0) { // cells 已經(jīng)初始化了
- if ((a = as[(n - 1) & h]) == null) { // 對(duì)應(yīng)的 cell 不存在,需要新建
- if (cellsBusy == 0) { // 只有在 cells 沒(méi)上鎖時(shí)才嘗試新建
- Cell r = new Cell(x);
- if (cellsBusy == 0 && casCellsBusy()) { // 上鎖
- boolean created = false;
- try { // 上鎖后判斷 cells 對(duì)應(yīng)元素是否被占用
- Cell[] rs; int m, j;
- if ((rs = cells) != null &&
- (m = rs.length) > 0 &&
- rs[j = (m - 1) & h] == null) {
- rs[j] = r;
- created = true;
- }
- } finally {
- cellsBusy = 0;
- }
- if (created) // cell 創(chuàng)建完畢,可以退出
- break;
- continue; // 加鎖后發(fā)現(xiàn) cell 元素已經(jīng)不再為空,輪詢(xún)重試
- }
- }
- collide = false;
- }
- // 下面這些 else 在嘗試檢測(cè)當(dāng)前競(jìng)爭(zhēng)度大不大,如果大則嘗試擴(kuò)容,如
- // 果擴(kuò)容已經(jīng)沒(méi)用了,則嘗試 rehash 來(lái)分散并發(fā)到不同的 cell 中
- else if (!wasUncontended) // 已知 CAS 失敗,說(shuō)明并發(fā)度大
- wasUncontended = true; // rehash 后重試
- else if (a.cas(v = a.value, ((fn == null) ? v + x : // 嘗試 CAS 將值更新到 cell 中
- fn.applyAsLong(v, x))))
- break;
- else if (n >= NCPU || cells != as) // cells 數(shù)組已經(jīng)夠大,rehash
- collide = false; // At max size or stale
- else if (!collide) // 到此說(shuō)明其它競(jìng)爭(zhēng)已經(jīng)很大,rehash
- collide = true;
- else if (cellsBusy == 0 && casCellsBusy()) { // rehash 都沒(méi)用,嘗試擴(kuò)容
- try {
- if (cells == as) { // 加鎖過(guò)程中可能有其它線(xiàn)程在擴(kuò)容,需要排除該情形
- Cell[] rs = new Cell[n << 1];
- for (int i = 0; i < n; ++i)
- rs[i] = as[i];
- cells = rs;
- }
- } finally {
- cellsBusy = 0;
- }
- collide = false;
- continue; // Retry with expanded table
- }
- h = advanceProbe(h); // rehash
- }
- else if (cellsBusy == 0 && cells == as && casCellsBusy()) { // cells 未初始化
- boolean init = false;
- try { // Initialize table
- if (cells == as) {
- Cell[] rs = new Cell[2];
- rs[h & 1] = new Cell(x);
- cells = rs;
- init = true;
- }
- } finally {
- cellsBusy = 0;
- }
- if (init)
- break;
- }
- else if (casBase(v = base, ((fn == null) ? v + x :
- fn.applyAsLong(v, x))))
- break; // 其它線(xiàn)程在初始化 cells 或在擴(kuò)容,嘗試更新 base
- }
- }
先別忙著驚訝,整理好心情慢慢看。
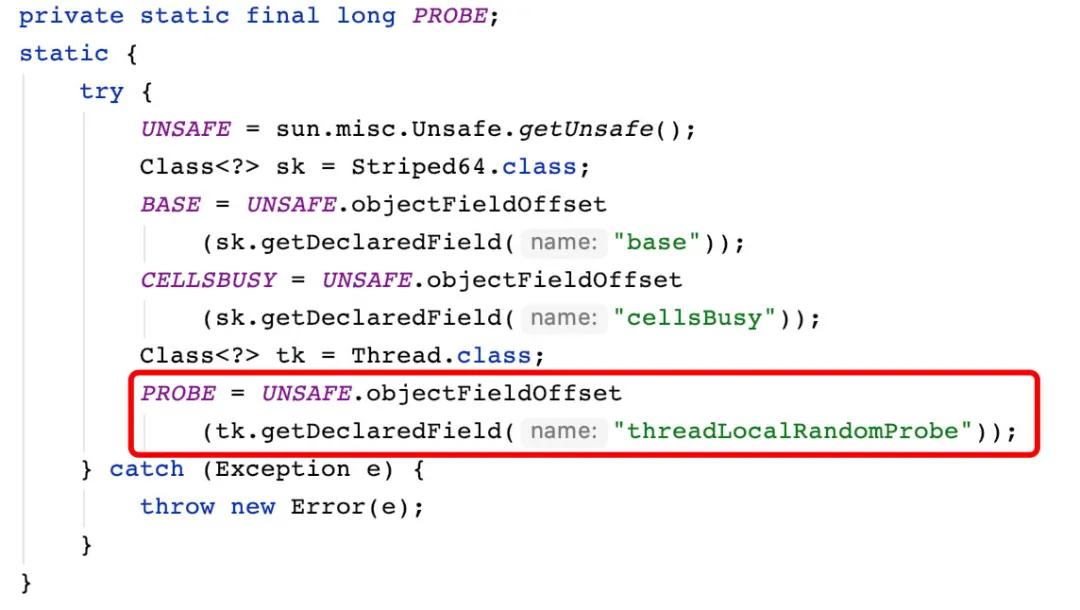
首先,在 Striped64 中,會(huì)先計(jì)算哈希,哈希值用于分發(fā)線(xiàn)程到 cells 數(shù)組。Striped64 中利用了 Thread 類(lèi)中用來(lái)做偽隨機(jī)數(shù)的 threadLocalRandomProbe:
- public class Thread implements Runnable {
- @sun.misc.Contended("tlr")
- int threadLocalRandomProbe;
- }
Striped64 中復(fù)制(直接拿來(lái)用)了 ThreadLocalRandom 中的一些方法,使用 unsafe 來(lái)獲取和修改字段值。
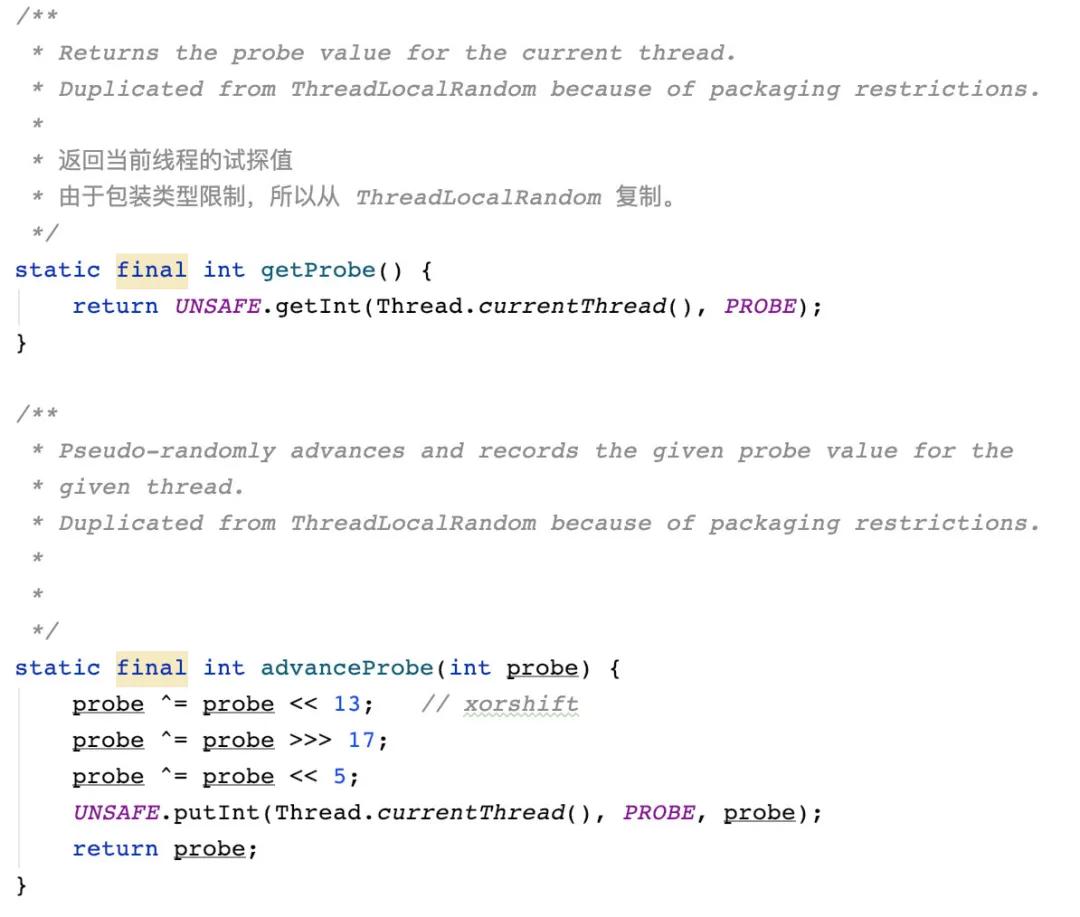
可以理解為 getProbe 用來(lái)獲取哈希值,advanceProbe 用來(lái)更新哈希值。
而其中的 PROBE 常量是在類(lèi)加載的時(shí)候從類(lèi)加載器提取的 threadLocalRandomProbe 的常量值。
然后是一系列的循環(huán)判斷向 cell 數(shù)組映射的操作,因?yàn)?Cells 類(lèi)占用比較多的空間,所以它的初始化按需進(jìn)行的,開(kāi)始時(shí)為空,需要時(shí)先創(chuàng)建兩個(gè)元素,不夠用時(shí)再擴(kuò)展成兩倍大小。在修改 cells 數(shù)組(如擴(kuò)展)時(shí)需要加鎖,這也就是 cellsBusy 的作用。

釋放鎖只需要將 cellsBusy 從 0 -> 1 即可。
- cellsBusy = 0;
另外,這個(gè)方法雖然代碼行很多,使用了很多 if else ,但其實(shí)代碼設(shè)計(jì)使用了雙重檢查鎖,也就是下面這種模式
- if (condition_met) { // 只在必要時(shí)進(jìn)入
- lock(); // 加鎖
- done = false; // 因?yàn)橥鈱佑休喸?xún),需要記錄任務(wù)是否需要繼續(xù)
- try {
- if (condition_met) { // 前面的 if 到加鎖間狀態(tài)可能變化,需要重新判斷
- // ...
- done = true; // 任務(wù)完成
- }
- } finally {
- unlock(); // 確保鎖釋放
- }
- if (done) // 任務(wù)完成,可以退出輪詢(xún)
- break;
- }
而 doubleAccumulate 的整體邏輯與 longAccumulate 幾乎一樣,區(qū)別在于將 double 存儲(chǔ)成 long 時(shí)需要轉(zhuǎn)換。例如在創(chuàng)建 cell 時(shí),需要
- Cell r = new Cell(Double.doubleToRawLongBits(x));
doubleToRawLongBits 是一個(gè) native 方法,將 double 轉(zhuǎn)成 long。在累加時(shí)需要再轉(zhuǎn)來(lái)回:
- else if (a.cas(v = a.value,
- ((fn == null) ?
- Double.doubleToRawLongBits
- (Double.longBitsToDouble(v) + x) : // 轉(zhuǎn)回 double 做累加
- Double.doubleToRawLongBits
- (fn.applyAsDouble
- (Double.longBitsToDouble(v), x)))))
上面的流程我們只是高度概括了下,實(shí)際的分支要遠(yuǎn)比我們概括的更多,longAccumulate 會(huì)根據(jù)不同的狀態(tài)來(lái)執(zhí)行不同的分支,比如在線(xiàn)程競(jìng)爭(zhēng)非常激烈的情況下,還會(huì)通過(guò)對(duì) cells 進(jìn)行擴(kuò)容或者重新計(jì)算哈希值來(lái)重新分散線(xiàn)程,這些做法的目的是將多個(gè)線(xiàn)程的計(jì)數(shù)請(qǐng)求分散到不同的 cell 中的 index 上,這其實(shí)和 ConcurrentHashMap 的設(shè)計(jì)思路一樣,只不過(guò) Java7 中的 ConcurrentHashMap 實(shí)現(xiàn) segment 加鎖使用了比較重的 synchronized 鎖,而 Striped64 使用了輕量級(jí)的 unsafe CAS 來(lái)進(jìn)行并發(fā)操作。
一口氣終于講完一個(gè)段落了,累屁我了,歇會(huì)繼續(xù)肝下面。
下面再說(shuō)回 LongAdder 這個(gè)類(lèi)。
LongAdder 的再認(rèn)識(shí)
所以,LongAdder 的原理就是,在最初無(wú)競(jìng)爭(zhēng)時(shí),只更新 base 值,當(dāng)有多線(xiàn)程競(jìng)爭(zhēng)時(shí)通過(guò)分段的思想,讓不同的線(xiàn)程更新不同的段,最后把這些段相加就得到了完整的 LongAdder 存儲(chǔ)的值,下面我畫(huà)個(gè)圖幫助你理解一下。
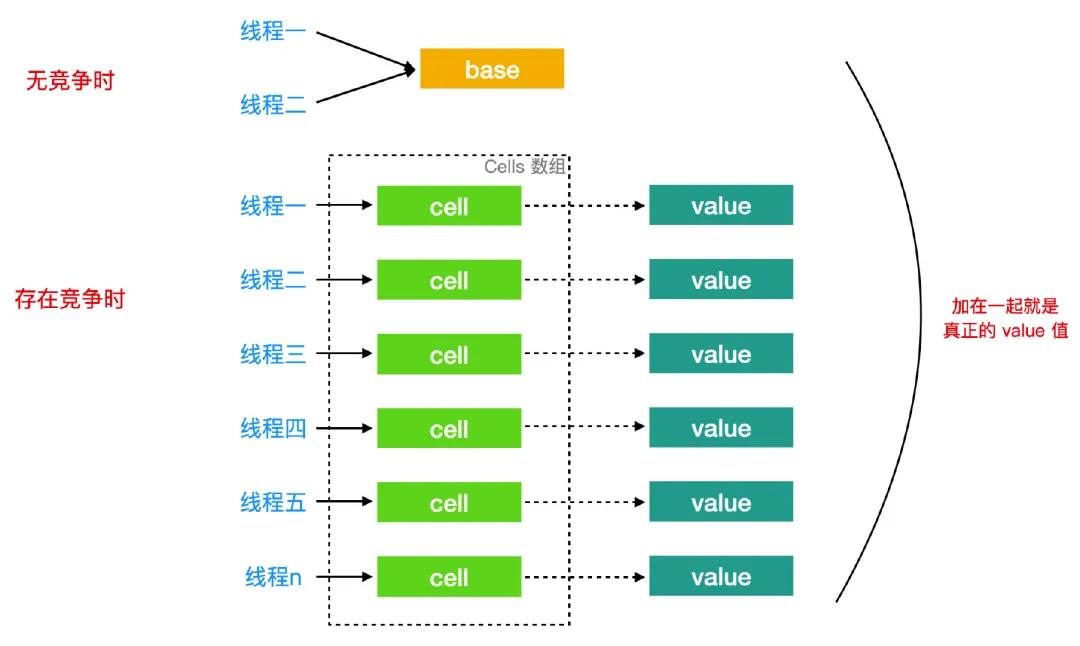
如果你理解了上面 Striped64 的描述和上面這幅圖之后,LongAdder 你就理解的差不多了,最后還有一個(gè) LongAdder 中的 sum 方法需要強(qiáng)調(diào)下:

sum 方法會(huì)返回當(dāng)前總和,在沒(méi)有并發(fā)的情況下會(huì)返回一個(gè)準(zhǔn)確的結(jié)果,也就是把所有的 base 值相加求和之后的結(jié)果,那么,現(xiàn)在有一個(gè)問(wèn)題,如果前面已經(jīng)累加到 sum 上的 Cell 的 value 值有修改,不就沒(méi)法計(jì)算了嗎?
這里的結(jié)論就是,LongAdder 不是強(qiáng)一致性的,它是最終一致性。
后記
這篇我和你聊了一下為什么引入 LongAdder 以及 AtomicLong 有哪些缺陷,然后帶你了解了一下 LongAdder 的源碼和它的底層實(shí)現(xiàn),如果這篇文章對(duì)你有幫助的話(huà),可以給我個(gè)三連,你的支持是我更新最大的動(dòng)力!