













盤點三種Python網絡爬蟲過程中的中文亂碼的處理方法
大家好,我是Python進階者。前幾天給大家分享了一些亂碼問題的文章,感興趣的小伙伴可以前往:UnicodeEncodeError: 'gbk' codec can't encode character解決方法,這里再次給大家祭出網絡爬蟲過程中三種中文亂碼的處理方案,希望對大家的學習有所幫助。
前言
前幾天有個粉絲在Python交流群里問了一道關于使用Python網絡爬蟲過程中中文亂碼的問題,如下圖所示。
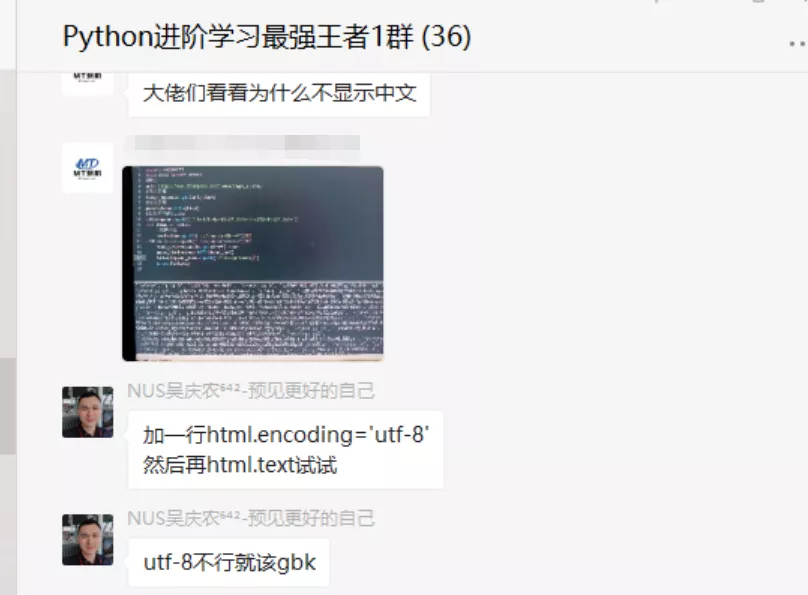
看上去確實頭大,對于爬蟲初學者來說,這個亂碼擺在自己面前,猶如攔路虎一般難頂。不過別慌,小編在這里給大家整理了三種方法,專門用于針對中文亂碼的,希望大家在后面再次遇到中文亂碼的問題,在此處可以得到靈感!
一、思路
其實解決問題的關鍵點就是在于一點,就是將亂碼的部分進行處理,而處理的方案主要可以從兩個方面進行出發。其一是針對整體網頁進行提前編碼,其二是針對局部具體中文亂碼的部分進行編碼處理。這里例舉3種方法,肯定還有其他的方法的,也歡迎大家在評論區諫言。
二、分析
其實關于中文亂碼的表現形式有很多,但是常見的兩種如下:
1、當出現網頁編碼為gbk,獲取到的內容在控制臺打印類似如下情況的時候:
- ÃÀÅ® µçÄÔ×À ¼üÅÌ »ú·¿ ¿É°® С½ã½ã4k±ÚÖ½
2、當出現網頁編碼為gbk,獲取到的內容在控制臺打印類似如下情況的時候:
- �װŮ�� ��Ů ˮ СϪ Ψ��
雖然看上去控制臺輸出正常,沒有報錯:
- Process finished with exit code 0
但是輸出的中文內容,卻不是普通人能看得懂的。
這種情況下的話,就可以通過使用本文給出的三種方法進行解決,屢試不爽!
三、具體實現
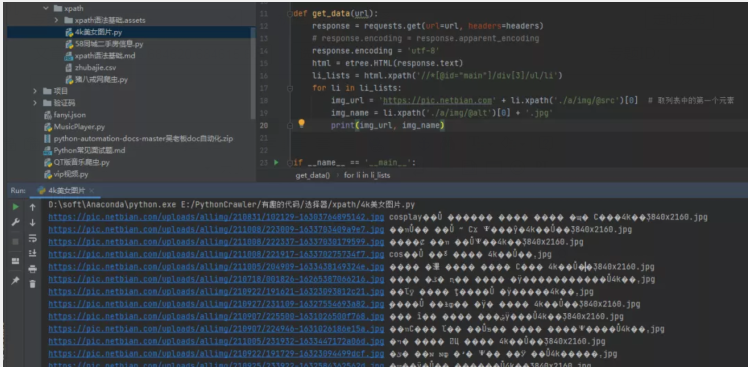
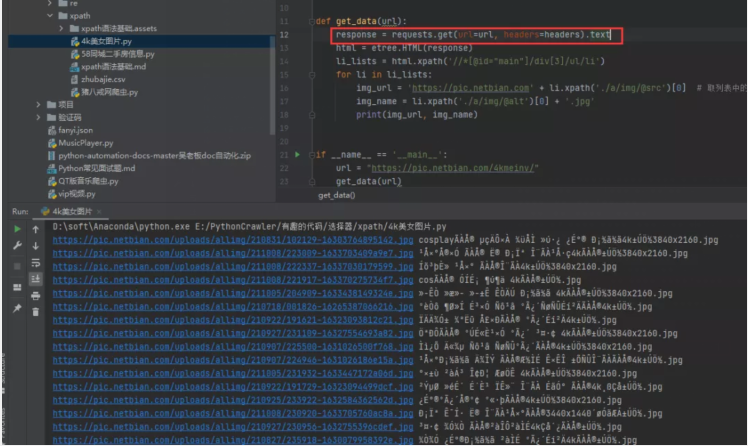
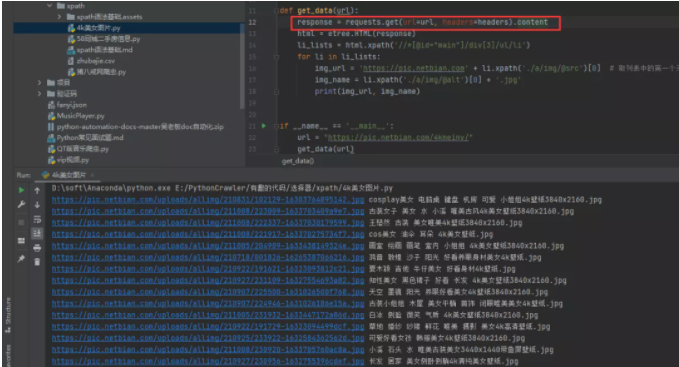
1)方法一:將requests.get().text改為requests.get().content 我們可以看到通過text()方法獲取到的源碼,之后進行打印輸出的話,確實是會存在亂碼的,如下圖所示。
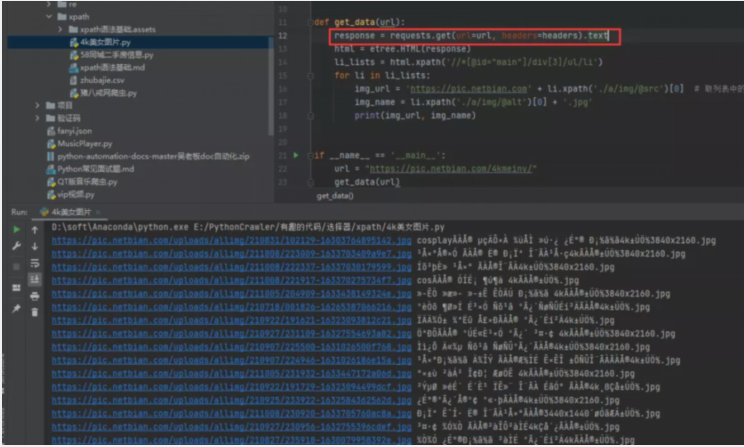
此時可以考慮將請求變為.content,得到的內容就是正常的了。
2)方法二:手動指定網頁編碼
- # 手動設定響應數據的編碼格式
- response.encoding = response.apparent_encoding
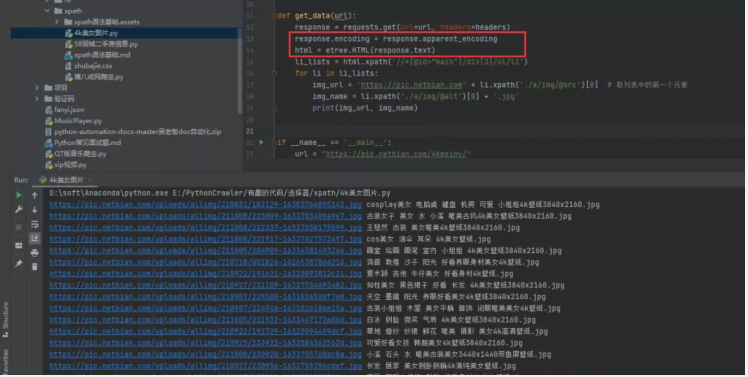
這個方法稍微復雜一些,但是比較好理解,對于初學者來說,還是比較好接受的。
如果覺得上面的方法很難記住,或者你可以嘗試直接指定gbk編碼也可以進行處理,如下圖所示:
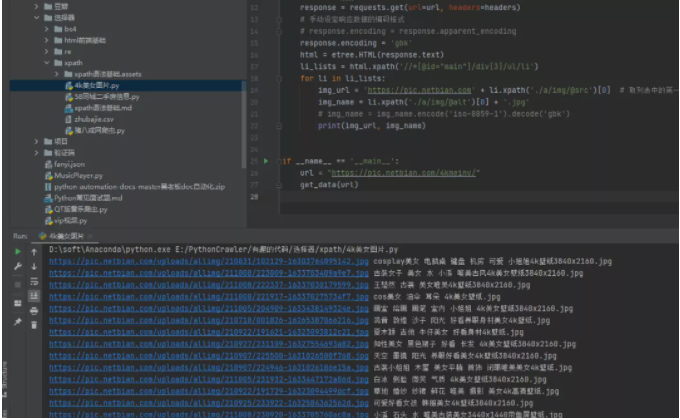
上面介紹的兩種方法都是針對網頁進行整體編碼,效果顯著,接下來的第三種方法就是針對中文局部亂碼部分使用通用編碼方法進行處理。
3)方法三:使用通用的編碼方法
- img_name.encode('iso-8859-1').decode('gbk')
使用通用的編碼方法,對中文出現亂碼的地方進行編碼設定即可。還是當前的這個例子,針對img_name進行編碼設定,指定編碼并進行解碼,如下圖所示。
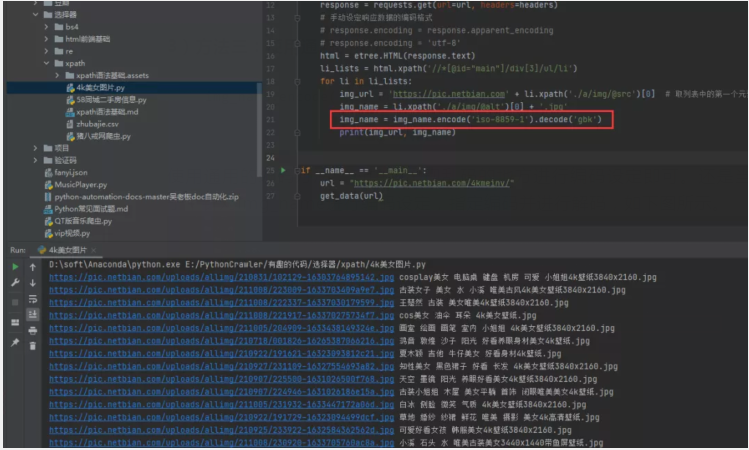
如此一來,中文亂碼的問題就迎刃而解了。
四、總結
我是Python進階者。本文基于粉絲提問,針對Python網絡爬蟲過程中的中文亂碼問題,給出了3種亂碼解決方法,順利幫助粉絲解決了問題。


















