數倉 | 幾種常見的數據同步方式
本文轉載自微信公眾號「大數據技術與數倉 」,作者西貝。轉載本文請聯系大數據技術與數倉公眾號。
寫在前面
數據倉庫的特性之一是集成,即首先把未經過加工處理的、不同來源的、不同形式的數據同步到ODS層,一般情況下,這些ODS層數據包括日志數據和業務DB數據。對于業務DB數據而言(比如存儲在MySQL中),將數據采集并導入到數倉中(通常是Hive或者MaxCompute)是非常重要的一個環節。
那么,該如何將業務DB數據高效準確地同步到數倉中呢?一般企業會使用兩種方案:直連同步與實時增量同步(數據庫日志解析)。其中直連同步的基本思路是直連數據庫進行SELECT,然后將查詢的數據存儲到本地文件作為中間存儲,最后把文件Load到數倉中。這種方式非常的簡單方便,但是隨著業務的發展,會遇到一些瓶頸,具體見下文分析。
為了解決這些問題,一般會使用實時增量的方式進行數據同步,其基本原理是CDC (Change Data Capture) + Merge,即實時Binlog采集 + 離線處理Binlog還原業務數據這樣一套解決方案。
本文主要包括以下內容,希望對你有所幫助
- 常見數據同步方式
- 流式數據集成
數據同步的方式
直連同步
直連同步是指通過定義好的規范接口API和基于動態鏈接庫的方式直接連接業務庫,比如ODBC/JDBC等規定了統一的標準接口,不同的數據庫基于這套標準提供規范的驅動,從而支持完全相同的函數調用和SQL實現。比如經常使用的Sqoop就是采取這種方式進行批量數據同步的。
直連同步的方式配置十分簡單,很容易上手操作,比較適合操作型業務系統的數據同步,但是會存在以下問題:
- 數據同步時間:隨著業務規模的增長,數據同步花費的時間會越來越長,無法滿足下游數倉生產的時間要求。
- 性能瓶頸:直連數據庫查詢數據,對數據庫影響非常大,容易造成慢查詢,如果業務庫沒有采取主備策略,則會影響業務線上的正常服務,如果采取了主備策略,雖然可以避免對業務系統的性能影響,但當數據量較大時,性能依然會很差。

日志解析
所謂日志解析,即解析數據庫的變更日志,比如MySQL的Binlog日志,Oracle的歸檔日志文件。通過讀取這些日志信息,收集變化的數據并將其解析到目標存儲中即可完成數據的實時同步。這種讀操作是在操作系統層面完成的,不需要通過數據庫,因此不會給源數據庫帶來性能上的瓶頸。
數據庫日志解析的同步方式可以實現實時與準實時的同步,延遲可以控制在毫秒級別的,其最大的優勢就是性能好、效率高,不會對源數據庫造成影響,目前,從業務系統到數據倉庫中的實時增量同步,廣泛采取這種方式。當然,這種方式也會存在一些問題,比如批量補數時造成大量數據更新,日志解析會處理較慢,造成數據延遲。除此之外,這種方式比較復雜,投入也較大,因為需要一個實時的抽取系統去抽取并解析日志,下文會對此進行詳細解釋。
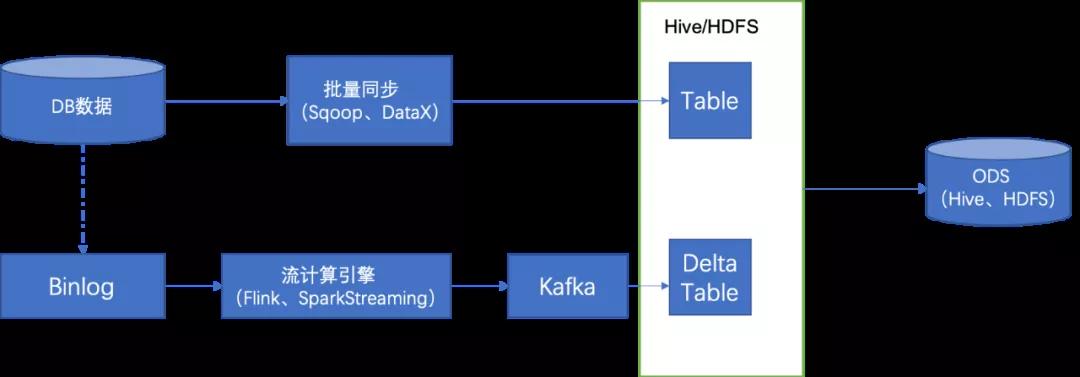
如上圖所示架構,在直連同步基礎之上增加了流式同步的鏈路,經過流式計算引擎把相應的 Binlog 采集到 Kafka,同時會經過一個 Kafka 2Hive 的程序把它導入到原始數據,再經過一層 Merge,產出下游需要的 ODS 數據。
上述的數據集成方式優勢是非常明顯的,把數據傳輸的時間放到了 T+0 這一天去做,在第二天的時候只需要去做一次 merge 就可以了。非常節省時間和計算資源。
流式數據集成實現
實現思路
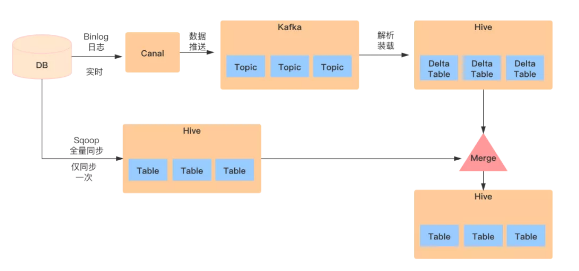
首先,采用Flink負責把Kafka上的Binlog數據拉取到HDFS上,生成增量表。
然后,對每張ODS表,首先需要一次性制作快照(Snapshot),把MySQL里的存量數據讀取到Hive上,這一過程底層采用直連MySQL去Select數據的方式,可以使用Sqoop進行一次性全量導入,生成一張全量表。
最后,對每張ODS表,每天基于存量數據和當天增量產生的Binlog做Merge,從而還原出業務數據。
Binlog是流式產生的,通過對Binlog的實時采集,把部分數據處理需求由每天一次的批處理分攤到實時流上。無論從性能上還是對MySQL的訪問壓力上,都會有明顯地改善。Binlog本身記錄了數據變更的類型(Insert/Update/Delete),通過一些語義方面的處理,完全能夠做到精準的數據還原。
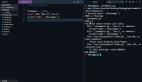
關于Binlog解析部分,可以使用canal工具,采集到Kafka之后,可以使用Flink解析kafka數據并寫入到HDFS上,解析kafka的數據可以使用Flink的DataStreamAPI,也可以使用FlinkSQL的canal-json數據源格式進行解析,使用FlinkSQL相對來說是比較簡單的。下面是canal-json格式的kafka數據源。
- CREATE TABLE region (
- id BIGINT,
- region_name STRING
- ) WITH (
- 'connector' = 'kafka',
- 'topic' = 'mydw.base_region',
- 'properties.bootstrap.servers' = 'kms-3:9092',
- 'properties.group.id' = 'testGroup',
- 'format' = 'canal-json' ,
- 'scan.startup.mode' = 'earliest-offset'
- );
數據解析完成之后,下面的就是合并還原完整數據的過程,關于合并還原數據,一種比較常見的方式就是全外連接(FULL OUTER JOIN)。具體如下:
生成增量表與全量表的Merge任務,當天的增量數據與昨天的全量數據進行全外連接,該Merge任務的基本邏輯是:
- INSERT OVERWRITE TABLE user_order PARTITION(ds='20211012')
- SELECT CASE WHEN n.id IS NULL THEN o.id
- ELSE n.id
- END
- ,CASE WHEN n.id IS NULL THEN o.create_time
- ELSE n.create_time
- END
- ,CASE WHEN n.id IS NULL THEN o.modified_time
- ELSE n.modified_time
- END
- ,CASE WHEN n.id IS NULL THEN o.user_id
- ELSE n.user_id
- END
- ,CASE WHEN n.id IS NULL THEN o.sku_code
- ELSE n.sku_code
- END
- ,CASE WHEN n.id IS NULL THEN o.pay_fee
- ELSE n.pay_fee
- END
- FROM (
- SELECT *
- FROM user_order_delta
- WHERE ds = '20211012'
- AND id IS NOT NULL
- AND user_id IS NOT NULL
- ) n
- FULL OUTER JOIN (-- 全外連接進行數據merge
- SELECT *
- FROM user_order
- WHERE ds = '20211011'
- AND id IS NOT NULL
- AND user_id IS NOT NULL
- ) o
- ON o.id = n.id
- AND o.user_id = n.user_id
- ;
經過上述步驟,即可將數據還原完整。
總結
本文首先介紹了數據倉庫構建ODS層常見的數據同步方式,并對每種方式進行了解釋,給出了相對應的示意圖。接著給出了CDC+Merge的數據同步方案。值得注意的是,Flink1.11引入了CDC的connector,比如MySQL CDC和Postgres CDC,同時對Kafka的Connector支持canal-json和debezium-json以及changelog-json的format,通過這種方式可以很方便地捕獲變化的數據,大大簡化了數據處理的流程和數據同步的復雜度。