手把手帶你學C++,Set是個啥,有什么用?
大家好,我是梁唐。
今天我們繼續(xù)來聊C++的STL,今天來聊聊set。為了寫這篇文章,老梁花了一早上的時間把網(wǎng)上大部分關(guān)于set的博文都看了一遍。
看完之后發(fā)現(xiàn)不出所料的千篇一律,上來就是說怎么創(chuàng)建set,set里有哪些函數(shù),標準的技術(shù)文檔。
這些東西對于老鳥來說當然沒問題,瞬間掃一眼就能找到自己想要的,但是對于新手來說估計看起來有些吃力。肯定一腦袋包,所以老梁另辟蹊徑,咱們先不羅列術(shù)語和api文檔,以記敘文的形式來說說它的前因后果、前世今生。
如果喜歡這種形式的文章,不妨給老梁點個贊,給老梁一點正反饋。
set是個啥?
如果大家學過幾門編程語言,會發(fā)現(xiàn)各大語言的特性雖然迥異,但是總有幾個東西反復(fù)出現(xiàn)刷存在感。它們在各個語言當中的名字雖然不太一樣,底層實現(xiàn)也不同,但是做的事情差不多。
在C++當中,這幾個東西的名字叫做vector、set和map,它們有一個共同的名字叫做STL(標準模板庫)容器。
估計不少同學看到容器這兩個字腦袋有點發(fā)蒙,會有一種我當然知道容器是什么意思,但是我不知道你這里說容器是什么意思的感覺。現(xiàn)實中的容器是用來存儲東西的器皿,在編程語言當中,也是一樣,只不過存儲的不再是實際的物品而是抽象的變量。
那么問題來了,同樣是容器,vector、set、map這些又有什么區(qū)別呢?前面的文章里說過,vector類似于數(shù)組,可以以線性的形式存儲元素。而set、map和vector不同,它們不是線性的容器,而是關(guān)聯(lián)式的容器。
看到新的術(shù)語,估計又有同學要發(fā)蒙了,先別著急發(fā)蒙。其實我們可以大膽猜測一下,從字面理解,所謂關(guān)聯(lián)式說白了也就是把兩個事物關(guān)聯(lián)起來。那么新的問題又來了,這個關(guān)聯(lián)是什么?我們怎么做的關(guān)聯(lián),又為什么要做關(guān)聯(lián)?
這幾個問題估計連很多老鳥都能唬住。
要解釋清楚這個,就需要先來說說set的功能。我們從現(xiàn)象入手去逐漸理解本質(zhì)。
我們有了vector,可以順序地存儲數(shù)據(jù),還可以隨心所欲地插入數(shù)據(jù)非常的方便,那么除了這些之外我們還需要什么呢?
當擁有的數(shù)據(jù)多了之后,就會產(chǎn)生一個很自然的需求,就是查找數(shù)據(jù)。數(shù)據(jù)搜集存儲起來之后總是要拿來用的,既然要拿出來用,自然就需要查找。在查找這個需求面前,vector很不夠看,因為它當中的數(shù)據(jù)都是線性排列的,排成一排,需要一個一個查找。數(shù)據(jù)少還行,如果數(shù)據(jù)多了,顯然忙不過來。
那怎樣查找才快呢?
得讓數(shù)據(jù)有順序,有了順序查找就快了。比如同樣是一行數(shù),如果它們都是有序的,我們就可以通過二分法來查找了,那么復(fù)雜度就陡然地從提升到了。看起來好像只是數(shù)學公式上的一點微小變化,實際上這兩者之間的差距大的離譜,尤其是在海量數(shù)據(jù)的情況下。
18,446,744,073,709,551,615這個數(shù)據(jù)夠大嗎?表示成科學記數(shù)法是,比地球上的沙子都多。這么龐大的數(shù)據(jù)要是一個一個遍歷過來真得天荒地老,即使計算機運行速度超快也不行。如果用二分法呢,只需要查找64次。64和一個比地球上沙子數(shù)量都大的數(shù)相比,這中間的差距可想而知。
所以我們想要快速查找,就必須要讓數(shù)據(jù)有順序,有了順序就可以用二分法快速查找。如果我們要存的數(shù)是數(shù)字,當然很好辦,天然有序。如果不是數(shù)字其實也很簡單,我們可以給它賦上一個id,給它們一個編號,用這個編號來排序,或者是根據(jù)我們的需要自己實現(xiàn)排序的邏輯,這都不是問題。
真正的問題在于數(shù)據(jù)結(jié)構(gòu),雖然二分法很快,但我們并不能直接使用它。因為我們不能以線性的形式來存儲數(shù)據(jù),如果我們這樣做,當我們要插入元素的時候,就會涉及數(shù)組中元素的移動。這一移動,那么插入的復(fù)雜度又蛻化成了。
所以我們需要使用二分查找的方法,但又不能使用數(shù)組,這就需要我們使用一個新的數(shù)據(jù)結(jié)構(gòu)。估計學過算法或者是看過老梁之前文章的同學應(yīng)該已經(jīng)猜到了,這樣的數(shù)據(jù)結(jié)構(gòu)就是樹,準確得說是二叉搜索樹。
老梁從網(wǎng)上找來一張圖,二叉搜索樹長這樣:
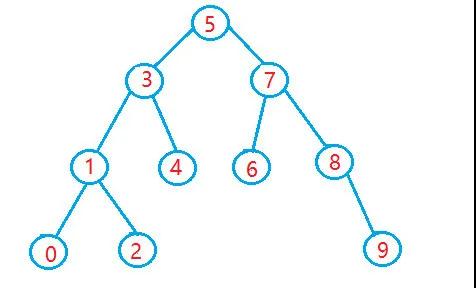
它看起來很普通,但有一個很牛的性質(zhì),就是對于任意一個節(jié)點,它都滿足它左子樹的所有元素都比它小,右子樹的所有元素都比它大。當我們想要查找某一個元素的時候就很強大了,我們只需要利用這個性質(zhì)從根節(jié)點開始往左往右遍歷,就能找到目標了。
在理想情況下,我們每次進行分支選擇的時候,都等價于舍棄掉了一半的元素,也就是將搜索空間縮小了一半。所以它其實也是一個二分查找算法,復(fù)雜度同樣是。
有了這樣的樹結(jié)構(gòu),插入元素的問題就解決了,因為樹上的元素都是離散的,我們插入節(jié)點并不會影響其他節(jié)點。但這又會產(chǎn)生另外一個問題,就是插入元素會破壞樹上元素的分布。比如我們一直插入一個比樹上所有元素都要小的數(shù),那么這個數(shù)會一直被添加在搜索樹的最左側(cè),長此以往就會導致這棵樹的左側(cè)元素特別多,這樣就會影響元素查找的性能。
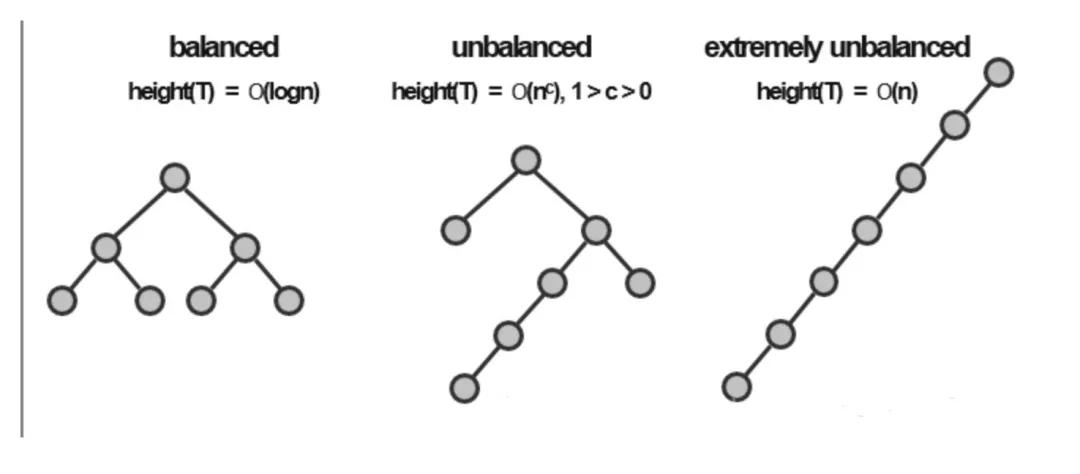
好在這個問題并不是無解的,我們可以設(shè)計一些算法讓樹在元素添加或者刪除的時候能夠自我修復(fù)平衡性,一直保持樹上元素的平衡。
從這個出發(fā)點設(shè)計出來的算法有很多,所以自平衡二叉搜索樹有很多種。比如常見的AVL、紅黑樹、SBT等等。在這許多算法當中,公認紅黑樹的統(tǒng)計性能最好,所以往往set、map這些關(guān)聯(lián)式容器的底層都是用紅黑樹寫的。
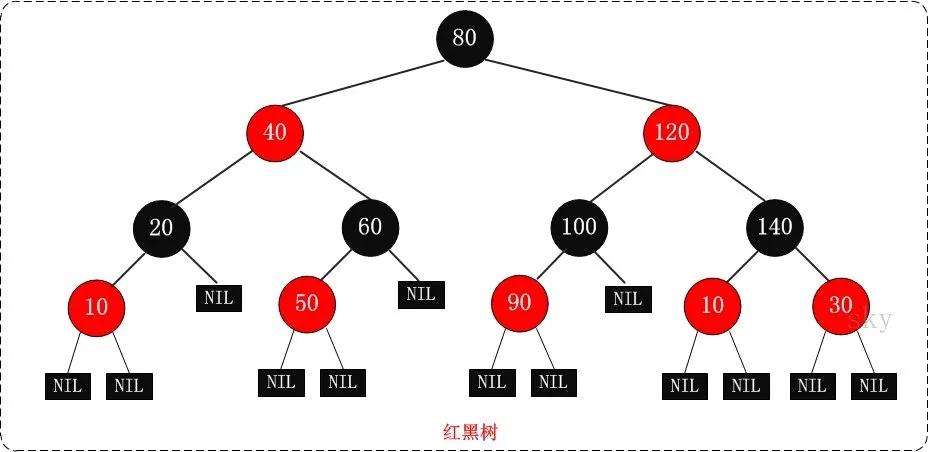
所以到這里,整個邏輯就閉合上了,我們也終于可以回答那個一開始的問題。set是個啥?
set是一個用紅黑樹實現(xiàn)的關(guān)聯(lián)式容器,它可以有序地存儲數(shù)據(jù),提供快速的查找、添加刪除的功能。
set有什么用?
搞明白了set是個啥,接下來的問題就是它有什么用。
其實某種程度上來說這兩個問題是一個問題,理解了它的設(shè)計原理和設(shè)計思路,自然也就明白了它能干什么。
最大的功能就是數(shù)據(jù)的查找,由于set底層是通過紅黑樹實現(xiàn)的,紅黑樹的本質(zhì)是二叉搜索樹。既然是二叉搜索樹就需要保證key唯一,所以set中的元素也必須是唯一的。那么我們就可以利用這個性質(zhì)來構(gòu)建一個容器,保證容器內(nèi)的元素是唯一的,并提供查詢功能。
舉個簡單的例子,比如說開發(fā)了一個新功能要上線測試。為了防止除測試人員之外的其他用戶遇到bug影響用戶體驗,所以一般常規(guī)措施都是維護一個白名單。也就是在名單中的人才能看到這個特性,其他用戶還是走老的邏輯。這樣的一個白名單用set就非常合適。
set的常規(guī)使用代碼也非常簡單,也就只有幾行:
- #include <set>
- // 創(chuàng)建set
- std::set<T> st;
- // 插入元素
- T t = T();
- st.insert(t);
- // 查找元素
- if (st.count(t)) {
- }
當然這個只是最常規(guī)最常規(guī)的用法,除了這些之外,set還有很多進階用法,以及不少注意事項。由于篇幅原因,我們下一篇文章再和大家詳細聊聊。
本文轉(zhuǎn)載自微信公眾號「Coder梁」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系Coder梁公眾號。