社交網絡場景下大規模圖存儲實踐之Facebook TAO

概述
Facebook TAO[1] ,即 The Associations and Objects 的縮寫,點(對象,Object)和邊(聯結,Associations)是”圖“中最基本的抽象,用來做 Facebook 圖存儲名字倒是恰如其分。
概括來說,TAO 是 Facebook 為了解決社交場景下,超大數據的更新與關聯讀取問題,其核心特點如下:
- 提供面向 Facebook 社交信息流場景特化的圖 API ,比如點查、一度關聯查詢、按時間的范圍查詢。
- 兩層架構,MySQL 做存儲層,MemeCache 做緩存層;緩存層又可細分為主從兩層。
- 可多機房擴展,高度面向讀性能優化,只提供最終一致性保證。
歷史沿革
Facebook 早期沉淀的數據就在 MySQL 上[2],MySQL 扛不住后,在 2005 年時,扎克伯格便引入了 MemCache 做緩存層,應對更高頻的讀請求。自此之后,MySQL 和 MemCache 便成為了 Facebook 存儲層技術棧的一部分。
Facebook 數據請求負載通常符合時間局部性(即最近更新的數據最容易被訪問),而非空間局部性。但 MySQL 中的數據通常不是按照時間有序存儲的,因此 MySQL InnoDB 引擎自帶的 block cache 并不匹配這一特點。另外,MemCache 本身只提供基于內存的 KV 訪問模型,為了更高效的利用這些內存,Facebook 需要針對社交場景自己定制緩存策略,以盡可能多的讓讀請求命中。
將這些工程細節,包括兩層存儲集群,包括自行組織緩存,都暴露給應用層工程師,帶來了很大的工程復雜度,引發了更多的 bug,降低了產品迭代速率。為了解決這個問題,Facebook 在 2007 年使用 PHP 在服務端做了一個抽象層,基于圖存儲模型,圍繞點(對象)和邊(聯結)提供 API。由于社交場景中的喜歡、事件、頁面等都可以通過圖模型來方便表達,這一抽象層極大的降低了應用層工程師的心智負擔。
但隨著所需 API 越來越多,將圖模型層(在 webserver 上)和數據層(在 MySQL和MemCache 集群)分離實現的缺點逐漸暴露了出來:
從邊集合的微小更新,會導致整個邊集合失效,從而降低緩存命中率。
請求邊列表的一個微小子集也需要將整個邊列表從存儲端拉到服務端。
緩存一致性很難維持。
當時的 MemCache 集群很難協同支持實現一個純客戶端側的驚群避免策略。
所有這些問題,都可以通過重新設計統一的、基于圖模型的存儲層來實現。從 2009 年開始,TAO 便在 Facebook 內部的一個團隊開始醞釀。再之后,TAO 逐漸發展成了支撐每秒數十億次讀取、數百萬次寫入,部署于跨地區海量機器上的分布式服務。
圖模型 & API
圖的最基本組成就是點和邊,對應到 TAO 里就是,對象(Objects)和聯結(Associations)。對象和聯結都可以包含一系列由鍵值對表示的屬性。
- Object: (id) → (otype, (key value)*)
- Assoc.: (id1, atype, id2) → (time, (key value)*)
注:TAO 中的邊都是有向邊。
以社交網絡為例,對象可以是用戶、打卡、地點、評論,聯結可以是朋友關系、發表評論、進行打卡、打卡于某地等等。
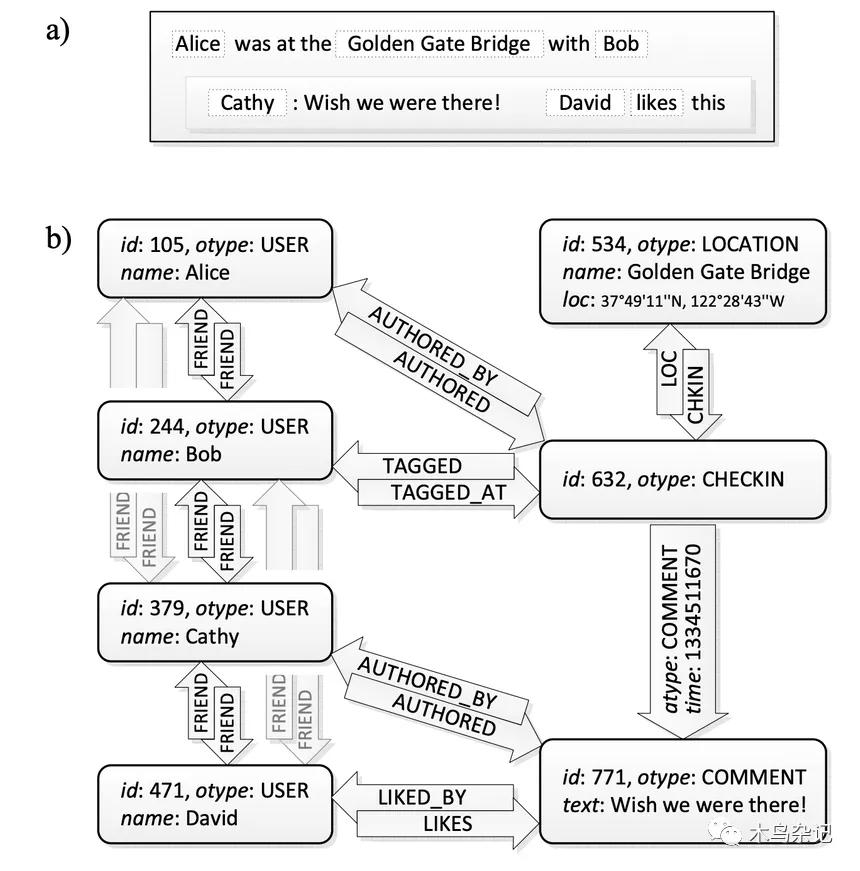
如下圖 a),假設在 Facebook 上有這么一事件:Alice 和 Bob 在金門大橋打了個卡,Cathy 評論:真希望我也在那。David 喜歡了這條評論。
用圖模型表示后,如下圖 b):
一個栗子
可以看到,所有的數據條目如用戶、地點、打卡、評論都被表示成了帶類型的對象(typed objec),而對象間的關系如被誰喜歡(LIKED_BY)、是誰的朋友(FRIEND)、被誰評論(COMMENT),則被表示成了帶類型的聯結(typed associations)。
另外,盡管 TAO 中聯結都是單向的,但實際中大部分關系是雙向的。這時,可以增加一個反向邊(inverse edges)來表示此種雙向關系。
最后,由于聯結是三元組,因此兩個對象間可以有多條不同類型的邊,但是同一類型的邊,只能有一條。但在有些非社交場景中,可能需要相同類型的邊也有多條。
Object API
圍繞 Object 的操作,是常見的增刪改查(create / delete / set-fields / get )。
同一對象類型(object type)的對象具有同樣的屬性集(fields,即上面提到的 (key value)*),也就是說,一個對象類型對應固定的屬性集。可以通過修改對象類型的 Schema 來對其所含屬性進行增刪。
Association API
圍繞 Association 的基本操作,也是增刪改查。其中增刪改如下:
- assoc_add(id1, atype, id2, time, (k→v)*) – 新增或者覆蓋
- assoc_delete(id1, atype, id2) – 刪除
- assoc_change_type(id1, atype, id2, newtype) - 修改
值得一說的是,如果其反向邊((id1, inv(atype), id2))存在,則上述 API 會同時作用于其反向邊。由于多數場景下的聯結是雙向的,因此 Facebook 將其邊的 API 默認行為同時作用于兩條邊。
另外,每個 Association 都會自動打上一個重要的特殊屬性:聯結時間(association time)。由于 Facebook 負載具有時間局部性,利用此時間戳可以對緩存數據集進行優化,以提高緩存命中率。
Association Query API
圍繞 Association 的查詢 API,是 TAO 的核心 API,流量最大。這負載類型包括:
- 指定 (id1, type, id2) 的點查,通常用來確定兩個對象間是否存在對應聯結,或者獲取對應聯結的屬性。
- 指定 (id1, type) 的范圍查詢,要求結果集按時間降序排列。比如一個常見場景:該條內容最新的 50 條評論是什么?。此外,最好能提供迭代器形式的訪問。
- 指定 (id1, type) 出邊數查詢。比如查詢*某條評論的喜歡數是多少?*此種查詢很常見,因此最好將其直接存下來,以能夠在常數時間內返回結果。
盡管聯結千千萬,但最近的范圍是重點查詢對象(時間局部性),因此聯結的查詢 API 主要圍繞時間的范圍查詢展開。
為此,TAO 將最基本的聯結集定義為 Association List。一個 Association List 是以 id1 為起點,出邊類型為 atype 的所有聯結的集合,按時間降序排列。
- Association List: (id1, atyle) -> [a_new, ..., a_old]
基于此,定義更細粒度的幾個接口:
- // 返回以 id1 為起點,以 id2set 集合所包含點為終點
- // 創建時間 time 滿足 low <= time <= high
- // 的聯結集合。
- assoc_get(id1, atype, id2set, high?, low?)
- // 返回聯結集合的數量
- assoc_count(id1, atype)
- // 返回下標滿足 [pos, pos+limit) 的聯結集合子集
- // pos 即 Association List 中的下標
- assoc_range(id1, atype, pos, limit)
- // 返回創建時間 time 滿足,從 time <= high **倒序**起始,
- // 到 time >= low 終止,不超過 limit 條聯結
- assoc_time_range(id1, atype, high, low, limit)
為什么結果集按時間降序排列呢?因為在 Facebook 頁面信息流展示時,總是先展示最新的,然后隨著不斷下拉,依次加載較舊的數據。
舉個栗子:
- • “50 most recent comments on Alice’s checkin” ⇒ assoc_range(632, COMMENT, 0, 50)
- • “How many checkins at the GG Bridge?” ⇒ assoc_count(534, CHECKIN)
架構
TAO 架構
TAO 架構整體分兩層,緩存層(caching layer)和存儲層(storage layer)。
存儲層
由于前面所說的歷史原因,TAO 使用 MySQL 作為存儲層。
因此,TAO 對外的 API 最終會被轉化成 MySQL 語句作用于存儲層,但對 MySQL 的查詢語句都相對簡單。當然,存儲層也可以使用 LevelDB 這種 NoSQL 存儲引擎,這樣查詢語句就會對應翻譯為前綴遍歷。當然,選擇存儲引擎不止要看 API 翻譯方便與否,還要看數據備份、批量導入導出、多副本同步等非 API 因素。
單個 MySQL 服務肯定存不下所有 TAO 數據,因此 TAO 使用了 MySQL 集群支撐存儲層。為了將數據均勻的分到多個 MySQL 機器上,TAO 使用一致性哈希算法將數據在邏輯上進行了切片(shard)。每個切片存到一個 MySQL db 中。每個 Object 在創建時會關聯一個 shard,并將 shard_id 做到 object_id 中,因此在 Object 整個生命周期中其 shard 都不會再改變。
具體來說,MySQL 中所存數據主要包括兩張表,一個點表,一個是邊表。其中,點和其出邊會存在同一個 MySQL db 中,以最小化關聯查詢代價。所有的點屬性在保存時,會被序列化到一個叫做 data 的列。如此,可以將具有不同類型的 Object 保存到一張表中。邊和點保存時類似,但是會額外在 id1,atype,andtime 字段上做索引,以方便基于某個點的出邊的范圍查詢。此外,為了避免對邊的數量的查詢所帶來的高昂開銷,會額外用一張表來保存 associations 的數量。
緩存層
讀寫穿透。TAO 的存儲層實現了所有對外 API,對客戶端( Client )完全屏蔽了存儲層。即,Clients 只和緩存層進行交互,緩存層負責將數據同步到存儲層。緩存層也是由多個緩存服務器構成,能夠 Serve 任意 TAO 請求的一組緩存服務器稱為一個 Tier。單個請求會路由到單個緩存服務器,不會跨多個服務器。
緩存策略使用經典的 LRU。值得一提的是,由于 TAO 的邊默認是雙向的,在 Client 寫入邊時,由緩存層變成負責將其變為寫去邊和回邊的兩個有向邊,但 TAO 并不保證其原子性。失敗了會通過垃圾回收來刪除中間結果。
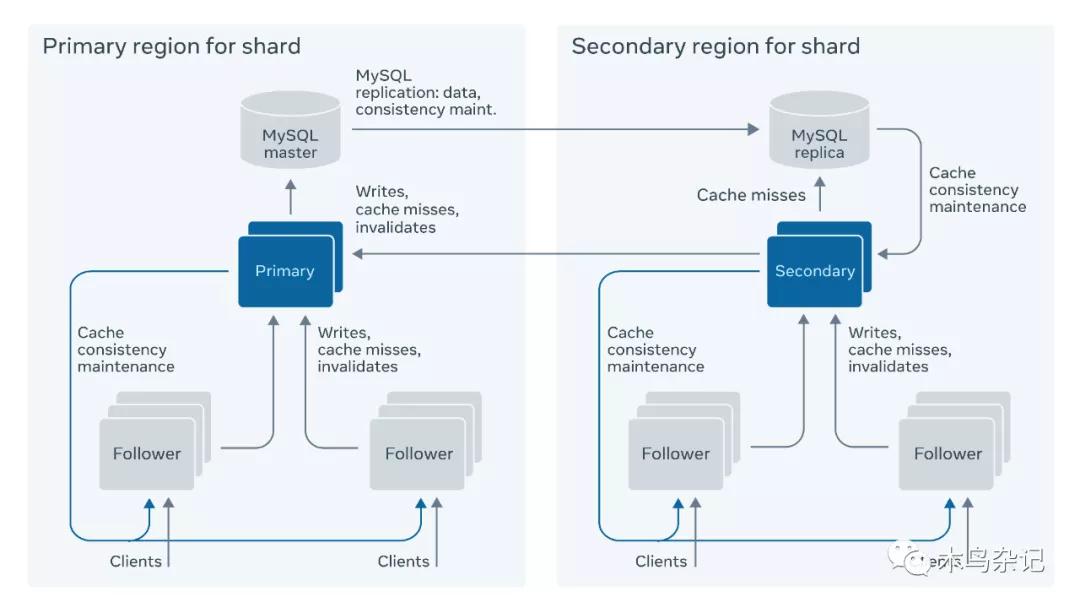
兩層架構。TAO 中的每個邏輯分片(Shard)基本是同構的。每個邏輯分片的緩存層包括一組緩存服務器,由單個 Leader 緩存服務器和一組 Follower 緩存服務器構成。
其中,Followers 緩存服務器是外層,Leader 服務器是內層。所有客戶端只和 Followers 打交道,Followers 緩存服務器本身只負責讀請求,如果發現讀未命中或者有寫請求,就將其轉發給所對應 Leader 緩存服務器。
如果讀請求負載持續增加,對 Follower 緩存服務器擴容即可。
如果對某些 object 訪問顯著高于其他,TAO 會通過記錄訪問頻次對其識別,然后進行客戶端側的緩存,并通過版本號來維持一致性。
一致性。Leader 收到多個 Follower 的并行寫請求后會將其進行定序,序列化后到存儲層進行同步讀寫后返回;對于寫請求來說,還會異步的通知其他 Follower 服務進行對應數據的更新,因此 TAO 最終只能提供最終一致性保證。這樣做的好處是換來了讀請求的高吞吐。
多地擴展。由于 TAO 的讀請求頻次約為寫頻次的 25 倍,而單地數據中心(datacenter)又不能滿足 Facebook 全球場景。因此 TAO 整體上使用了主從架構,兩個 datacenter 都部署一套存儲層+緩存層作為主從(Primary-Secondary),所有寫請求都要由從數據中心的 Leader Cache 路由到主數據中心(見上圖),然后由主數據中心存儲層異步傳回從數據中心。但從數據中心的 Leader Cache 并不等本地存儲層同步回數據,即進行更新,并通知 Followers 到自己這 Refill。TAO 的這種設計,能夠最大化的保證一個讀取請求在一個 DataCenter 內被滿足,代價是客戶端可能會讀到過時數據。即犧牲一致性,來降請求低延遲,提高吞吐。
一致性
TAO 在一致性和可用性取舍方面時,選擇了后者。為了高可用性和極致的性能,選擇了弱化的一致性模型——最終一致性。因為在 Facebook 的大部分場景下,不可用要比不正確更加糟糕。在大部分常見場景下,TAO 能做到更強的寫后讀一致性(read after write consistency)。
TAO 中同一份數據,首先,會進行 Master-Slave Region 進行主從備份;其次,在同一 Region 中,會使用 Leader-Follower Cache 做兩層緩存。更新時,不同位置的數據不同步,便會造成數據的不一致。在 TAO 中,在更新后給足夠時間間隔,所有的數據副本都會趨向一致,并且體現最新更新。而通常,這個時間間隔不會超過 1s 。這在 Facebook 中大多數場景是沒有問題的。
對于那些對一致性有特殊要求的場景,應用層可以將請求標記為 critical。TAO 在接到有此標記的請求時,會將其轉發到 Master Region 進行處理,進而獲取強一致性。
參考
[1] TAO 論文:https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
[2] Facebook 技術博客,TAO——圖的威力:https://engineering.fb.com/2013/06/25/core-data/tao-the-power-of-the-graph/
[3] meetup TAO:https://www.notion.so/Meetup-1-Facebook-TAO-28e88836a3f649ba9b3e3ea83858c593
[4] stanford 6.S897 課件:https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf