













面試官:說說常見的排序算法有哪些?區別?
本文轉載自微信公眾號「JS每日一題」,作者灰灰 。轉載本文請聯系JS每日一題公眾號。
一、是什么
排序是程序開發中非常常見的操作,對一組任意的數據元素經過排序操作后,就可以把他們變成一組一定規則排序的有序序列
排序算法屬于算法中的一種,而且是覆蓋范圍極小的一種,徹底掌握排序算法對程序開發是有很大的幫助的
對于排序算法的好壞衡量,主要是從時間復雜度、空間復雜度、穩定性
時間復雜度、空間復雜度前面已經講過,這里主要看看穩定性的定義
穩定性指的是假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變
即在原序列中,r[i] = r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中,r[i] 仍在 r[j] 之前,則稱這種排序算法是穩定的;否則稱為不穩定的
二、有哪些
常見的算法排序算法有:
- 冒泡排序
- 選擇排序
- 插入排序
- 歸并排序
- 快速排序
冒泡排序
一種簡單直觀的排序算法。它重復地走訪過要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來
思路如下:
- 比較相鄰的元素,如果第一個比第二個大,就交換它們兩個
- 對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最后一對,這樣在最后的元素應該會是最大的數
- 針對所有的元素重復以上的步驟,除了最后一個
- 重復上述步驟,直到沒有任何一堆數字需要比較
選擇排序
選擇排序是一種簡單直觀的排序算法,它也是一種交換排序算法
無論什么數據進去都是 O(n2)的時間復雜度。所以用到它的時候,數據規模越小越好
唯一的好處是不占用額外的內存存儲空間
思路如下:
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾。
重復第二步,直到所有元素均排序完畢
插入排序
插入排序是一種簡單直觀的排序算法
它的工作原理是通過構建有序序列,對于未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入
解決思路如下:
- 把待排序的數組分成已排序和未排序兩部分,初始的時候把第一個元素認為是已排好序的
- 從第二個元素開始,在已排好序的子數組中尋找到該元素合適的位置并插入該位置(如果待插入的元素與有序序列中的某個元素相等,則將待插入元素插入到相等元素的后面。)
- 重復上述過程直到最后一個元素被插入有序子數組中
歸并排序
歸并排序是建立在歸并操作上的一種有效的排序算法
該算法是采用分治法的一個非常典型的應用
將已有序的子序列合并,得到完全有序的序列,即先使每個子序列有序,再使子序列段間有序
解決思路如下:
- 申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合并后的序列
- 設定兩個指針,最初位置分別為兩個已經排序序列的起始位置
- 比較兩個指針所指向的元素,選擇相對小的元素放入到合并空間,并移動指針到下一位置
- 重復步驟3直到某一指針到達序列尾
- 將另一序列剩下的所有元素直接復制到合并序列尾
快速排序
快速排序是對冒泡排序算法的一種改進,基本思想是通過一趟排序將要排序的數據分割成獨立的兩部分,其中一部分的所有數據比另一部分的所有數據要小
再按這種方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,使整個數據變成有序序列
解決思路如下:
- 從數列中挑出一個元素,稱為"基準"(pivot)
- 重新排序數列,所有比基準值小的元素擺放在基準前面,所有比基準值大的元素擺在基準后面(相同的數可以到任何一邊)。在這個分區結束之后,該基準就處于數列的中間位置。這個稱為分區(partition)操作
- 遞歸地(recursively)把小于基準值元素的子數列和大于基準值元素的子數列排序
三、區別
除了上述的排序算法之外,還存在其他的排序算法,例如希爾排序、堆排序等等......
區別如下圖所示:
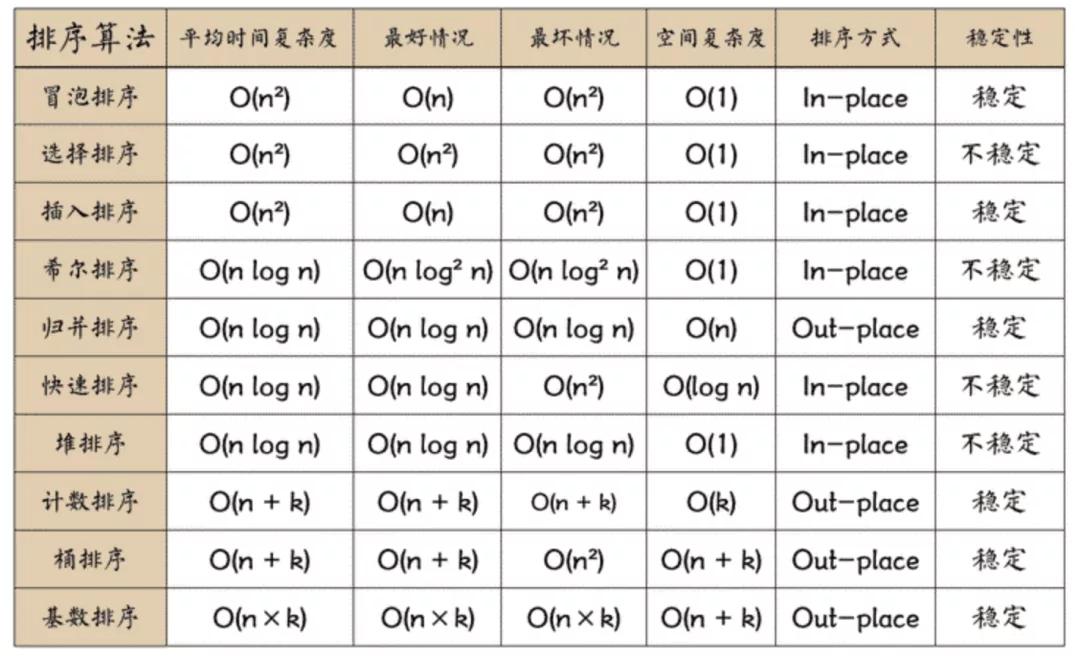
參考文獻
- https://www.runoob.com/w3cnote/bubble-sort.html
- http://www.x-lab.info/post/sort-algorithm/
- https://zhuanlan.zhihu.com/p/42586566


















