













預訓練模型的過去、現在和將來之一
最近,隨著大數據和高性能硬件的發展,自回歸語言模型(GPT)和自編碼語言模型(BERT)等大規模預訓練模型(PTM)已經取得了巨大成功,不僅促進了自然語言處理(NLP)任務的性能提升,也有效地提升了圖像處理任務的表現。大規模預訓練模型的突出優勢在于,能夠從海量未標注的數據上學習語言本身的知識,而后在少量帶標簽的數據上微調,從而使下游任務能夠更好地學習到語言本身的特征和特定任務的知識。這種預訓練模型不僅能夠充分利用廣泛的網絡資源,而且還能完美地解決人工標記數據較為復雜的問題。因此,預訓練模型幾乎成了NLP任務的標配[1]。
本文將分為上下兩篇為讀者解讀預訓練模型的誕生、代表性工作和未來發展方向。上篇主要介紹預訓練的誕生和代表性工作,下篇主要介紹預訓練模型的未來發展方向。相關內容主要借鑒參考文獻[1]。
1、背景介紹
近些年,包括卷積神經網絡、循環神經網絡和Transformer等模型在內的深度神經網絡已經廣泛地應用于各類應用中。與依賴人工特征的傳統機器學習方法相比,深度神經網絡能夠通過網絡層自動學習數據特征,從而擺脫了人工設計特征的局限性,極大地提升了模型的性能。
盡管深度神經網絡促進各類任務取得了極大的突破,但深度學習模型對數據較高的依賴性也帶來了極大的挑戰。因為深度學習模型需要學習大量的參數,數據量少必定會造成模型過擬合和泛化能力差。為此,早期的AI研究者開始投身于為AI任務手工構造高質量數據集的研究中。最著名的是李飛飛團隊的ImageNet圖像處理數據集,該數據集極大地促進了圖像處理領域的快速發展。但是,自然語言處理領域處理的是離散的文本數據,人工標注工作較為復雜。因此,NLP領域開始關注海量未標注的數據。
預訓練模型的最初探索主要致力于淺層語義表示和上下文語義表示。最早關注的淺層語義表示是Word2Vec[2]等,為每個單詞學習一個固定的單詞編碼,而后在多個任務上都用相同的編碼,這樣表示方法必定帶來無法表示一詞多義的問題。為了解決上述挑戰,NLP 研究者開始探索具有上下文語義的單詞詞嵌入表示[3][4][5]。到目前為止,具有代表性的詞嵌入表示是BERT和GPT系列的預訓練模型,其中GPT-3的模型參數已經達到了千億級別。預訓練模型的發展歷程如圖1所示。
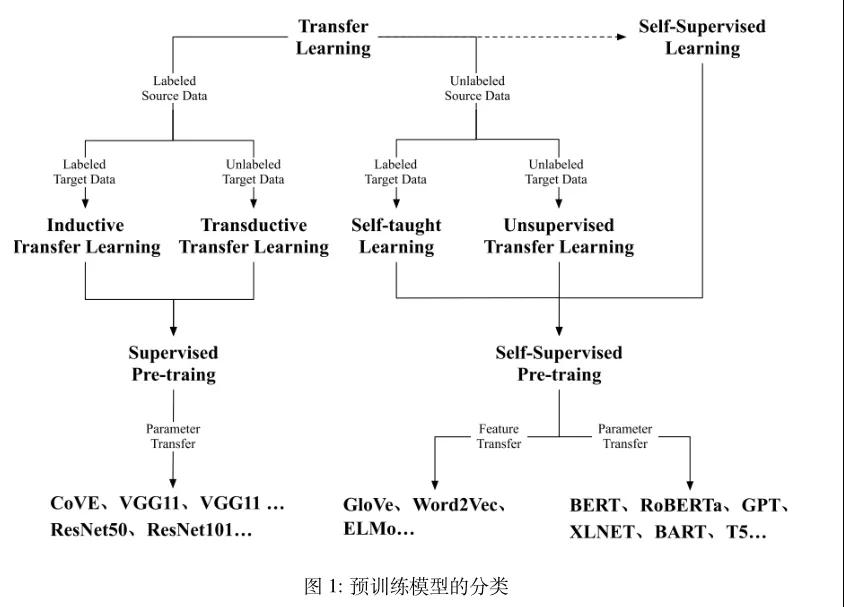
圖1 預訓練模型的分類
1.1 遷移學習與監督訓練
為了解決標注數據緊缺導致的過擬合和泛化能力差的問題,提出了遷移學習。遷移學習是受人類學習的啟發,面對新問題時使用以前學到的知識去解決問題。它能夠從多元任務中學到重要的知識,并將其應用到目標任務中。因此,遷移學習能很好地解決目標任務標注數據緊缺的問題。
預訓練早期的工作主要致力于遷移學習[6],依賴于先前的經驗來解決新問題。在遷移學習中,可能原任務和目標任務有不同的領域和任務設置,但是要求的知識是一致的[7]。所以,選擇一個靈活的方法將知識從原始任務遷移到目標任務是很重要的。預訓練模型的提出就是為了建立原任務和目標任務的橋梁,先在多元任務上預訓練獲得通用知識,然后使用少量目標任務上的標注數據進行微調,使得微調的模型能夠很好地處理目標任務。
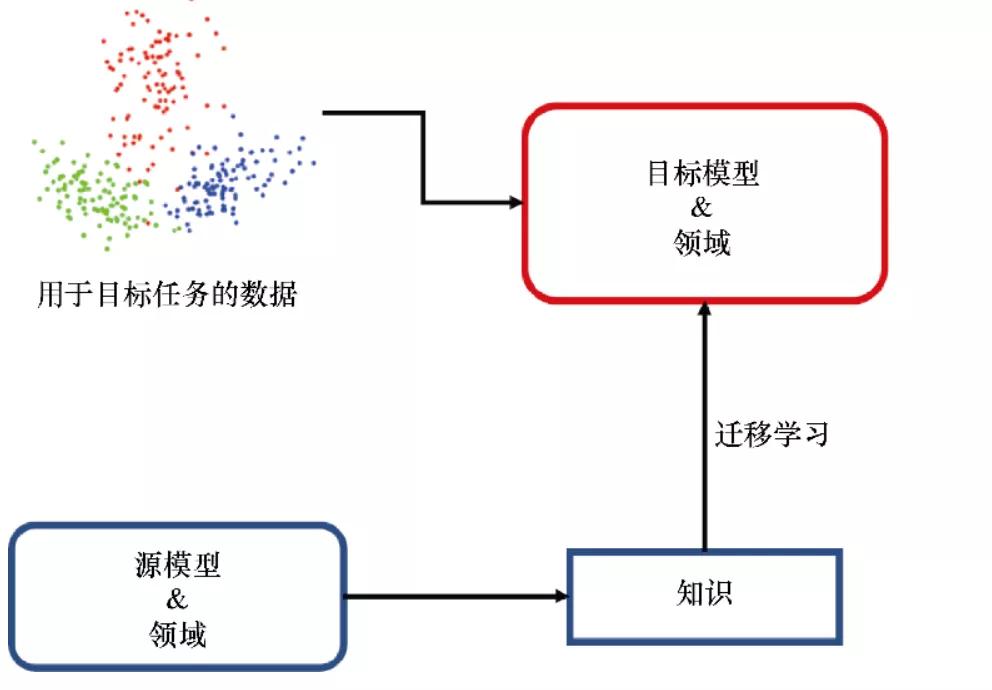
圖2 遷移學習將已有知識重用到目標任務的原理圖
一般來說,遷移學習中存在兩種預訓練方法:特征遷移和參數遷移。遷移學習初期被廣泛應用在計算機視覺領域,在人類標注的ImageNet數據集上預訓練的模型通過小數據集的微調就可以很好地應用在下游任務中,這掀起了預訓練模型(Pre-trained Model, PTM)的熱潮。受此啟發,NLP 社區也開始探索針對 NLP 任務的預訓練模型,最具有代表性的工作是 CoVE[8]。和圖像處理領域最大的區別在于,NLP 領域沒有人類標注的大量數據集,因此 NLP 社區開始充分使用大量未標注的數據,并且在未標注的數據上使用自監督方法,能夠讓預訓練模型學習到語言本身的特征。
1.2 自監督學習與自監督訓練
遷移學習能夠分類為四種子設置:歸納遷移學習、直推式遷移學習、自學遷移學習和無監督遷移學習。其中歸納遷移學習和直推式遷移學習是研究的核心,因為它們能夠將監督學習中學到的知識遷移到目標任務中。由于監督學習需要大量的標注數據,因此越來越多的研究者開始關注大規模的無標注數據,并嘗試從無標注數據中提取關鍵信息。
自監督學習是從無標注數據中提取知識的一種手段,它能夠利用數據本身的隱藏信息作為監督,和無監督有非常相似的設置。由于自然語言很難標注且又存在大量未標注的句子,所以NLP 領域的預訓練模型主要致力于自監督學習,進而大大促進了NLP領域的發展。NLP任務早期的預訓練模型就是廣為人知的單詞詞嵌入編碼。由于單詞通常存在一詞多義的問題 [4],進一步提出了能夠捕獲單詞上下文語義信息的句子級別單詞詞嵌入編碼模型,這種模型幾乎成為當前 NLP 任務的最常見模式,其中最具代表性的工作是自回歸語言模型(GPT)和自編碼語言模型(BERT)。受二者的啟發,后期又提出了很多更高效的預訓練模型,如 RoBERTa[9]、XLNET[10]、BART和T5[11]。
2、代表性工作
預訓練模型成功的關鍵是自監督學習與Transformer的結合,具有代表性的工作是 GPT 和BERT系列模型。后續的其他預訓練模型都是這兩個經典模型的變體。預訓練模型的相關模型家族如圖3所示。
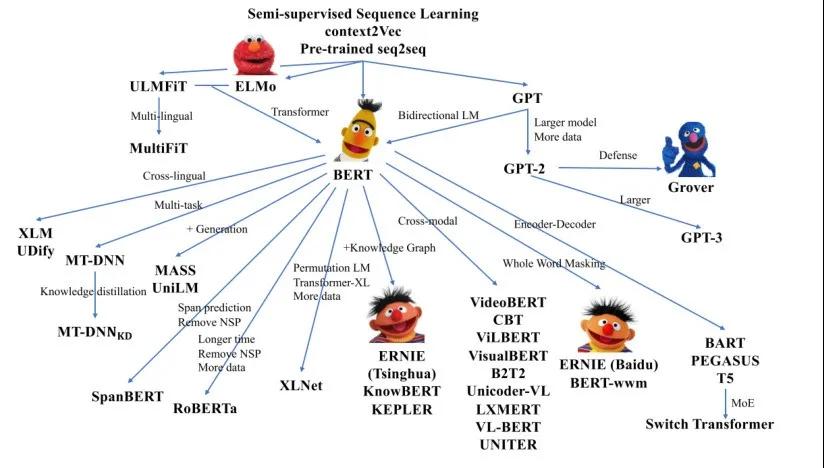
圖3 近年來的預訓練模型家族
2.1 Transformer
Transformer是一個應用自注意力機制的編碼-解碼器結構,它能夠建模輸入句子中不同單詞之間的關系。歸因于self-attention機制的平行計算,Transformer能夠充分利用增強的計算設備去訓練大范圍模型。Transformer的編碼和解碼階段,self-attention機制可以計算所有輸入單詞的表示,Transformer的模型結構如圖4所示。
在編碼階段,給定一個單詞,Transformer通過比較該單詞與輸入的其他單詞來計算注意力得分,每一個注意力得分顯示了其他單詞對該單詞表示的貢獻程度,然后該注意力得分被作為其他單詞對該單詞的權重來計算給定單詞的加權表示。通過喂入所有單詞表示的加權平均到全連接網絡,可以獲得給定單詞的影響力表示。這個過程是整個句子信息回歸方法,在平行計算的輔助下,可以同時為所有單詞生成句子表示。在解碼階段,注意力機制是相似于編碼階段的,唯一不同的是,它一次只能從左到右解碼一個表示,并且每一步的解碼過程都會考慮以前的解碼結果。
由于突出的優勢,Transformer逐漸成為自然語言理解和生成的標準網絡結構。此外,它還充當隨后派生的PTM的主干結構。下文將介紹的GPT和BERT兩個模型,完全打開了大規模自監督PTMs時代的里程碑。總的來說,GPT擅長自然語言生成,而BERT更側重于自然語言理解。
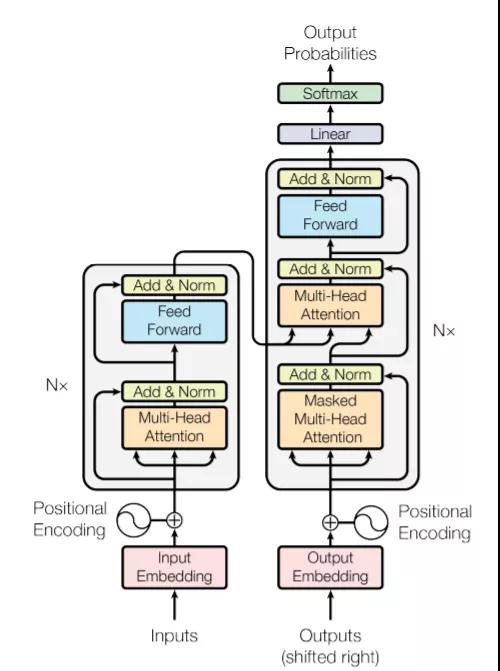
圖4 Transformer的模型結構
2.2 GPT
PTMs主要包含兩個階段,預訓練階段和微調階段。GPT采用Transformer結構作為模型骨架,應用生成式預訓練和鑒別式微調。理論上來說,GPT是第一個結合Transformer結構和自監督預訓練目標的模型,它在自然語言推理、問答任務和常識推理等多個NLP任務上都取得了重大的成功。
具體來說,給定一個無標簽的大規模語料庫,GPT能夠優化一個標準的自回歸語言模型,即最大化單詞在給定上下文情況下的預測條件概率。在GPT的預訓練階段,每個單詞的條件概率由Transformer建模。GPT對特定任務的適應過程是微調的,通過使用 GPT的預訓練參數作為下游任務的起點。在微調階段,將輸入序列通過 GPT,我們可以獲得GPT Transformer 最后一層的表示。通過使用最后一層的表示和特定于任務的標簽,GPT使用簡單的額外輸出層優化下游任務的標準目標,GPT模型的具體結構如圖5所示。
由于GPT有數億個參數,在8個GPU上訓練了1個月,這是 NLP歷史上第一個“大規模”的PTM,GPT的成功為后續一系列大規模PTM的興起鋪平了道路。
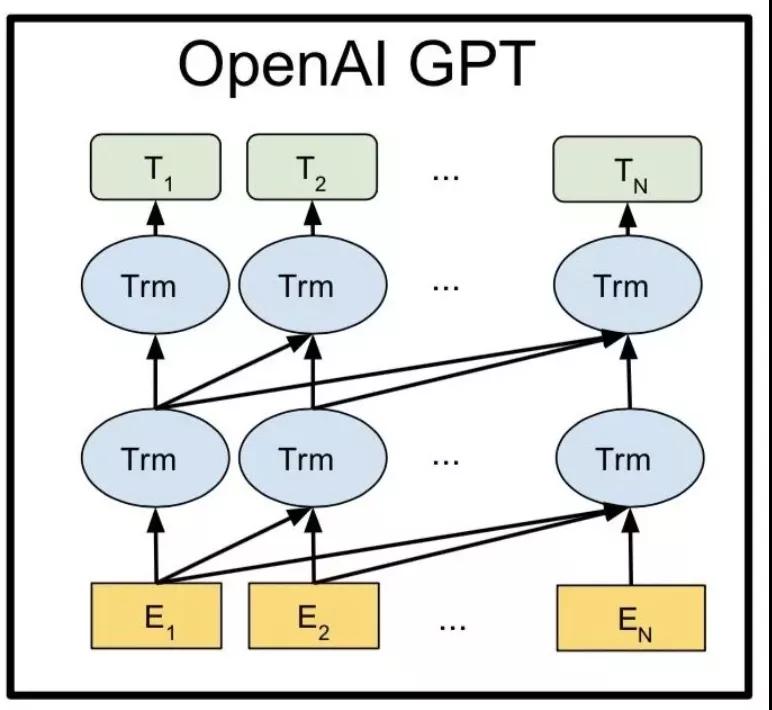
圖5 GPT模型結構
2.3 BERT
BERT是另一個最具代表性的模型。與GPT相比,BERT 使用雙向深度Transformer作為主要結構,BERT的模型結構如圖6所示。BERT模型包括預訓練和微調兩個階段。在預訓練階段,BERT應用自編碼語言建模,受完形填空的啟發,提出了一種Mask語言模型(MLM),將目標詞用[MASK]符號遮蓋,目的是在預測該遮蓋詞時能夠同時考慮到上文和下文的全部信息。與GPT采用的單向自回歸語言建模相比,MLM 可以學習到深度雙向所有token的表示。
除了MLM任務之外,還采用下一句預測(NSP)的目標來捕捉句子之間的話語關系,用于一些多個句子的下游任務。在預訓練階段,MLM和NSP共同優化BERT的參數。
預訓練后,BERT可以獲得下游任務的穩健參數。通過使用下游任務的數據修改輸入和輸出,BERT 可以針對任何 NLP 任務進行微調。BERT 可以通過輸入單個句子或句子對有效地處理這些應用程序。對于輸入,它的模式是用特殊標記 [SEP] 連接的兩個句子,它可以表示:(1)釋義中的句子對;(2)蘊涵中的假設-前提對;(3)問答中的問題-段落對;(4) 用于文本分類或序列標記的單個句子。對于輸出,BERT 將為每個令牌生成一個token-level表示,可用于處理序列標記或問答,并且特殊令牌 [CLS] 可以輸入額外的層進行分類。
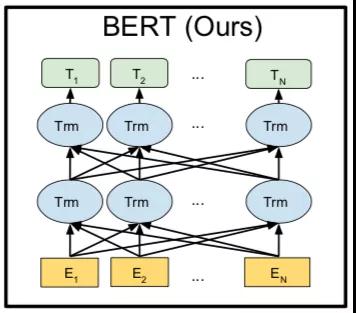
圖6 BERT模型結構
2.4 GPT和BERT的子子孫孫
在GPT和BERT預訓練模型之后,又出現了一些基于二者的改進,如RoBERTa和 ALBERT[12]。RoBERTa的改進思路主要是去除了NSP任務,增加了訓練步數以及更多的數據,并將[MASK]改變為動態模式。實證結果表明Roberta比BERT更好,并且RoBERTa 已經指出 NSP 任務對于BERT的訓練來說是相對無用的。
ALBERT是BERT的另一個重要變體,它的出發點是減少模型的參數。首先,它將輸入詞嵌入矩陣分解為兩個較小的矩陣;其次它強制所有 transformer 層之間的參數共享以減少參數量;第三,它提出了句子順序預測任務來代替BERT的NSP任務。但是,由于犧牲了空間效率,ALBERT 的微調和推理速度相對較慢。
除了 RoBERTa和ALBERT之外,近年來研究者們還提出了各種預訓練模型以更好地從未標注數據中獲取知識。一些工作改進了模型架構并探索了新的預訓練任務,如 XLNet[10]、UniLM[13]、MASS[14]、SpanBERT[15]和ELECTRA[16]。此外研究者嘗試在模型中整合更多的知識,如多語言語料庫、知識圖譜和圖像等。
3、小 結
由于NLP領域沒有公開的大規模標注語料庫,所以預訓練模型的提出使得NLP模型能夠充分地利用到海量無標注的數據,從而大大提升了NLP任務的性能。特別是,GPT和BERT預訓練模型的出現,讓NLP領域有了突飛式發展,同時,優化與完善的預訓練模型也如雨后春筍般涌現,相關的探索工作將在下篇詳細介紹。
參考文獻
[1] Xu H, Zhengyan Z, Ning D, et al. Pre-Trained Models: Past, Present and Future[J]. arXiv preprint arXiv:2106.07139, 2021.
[2] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, pp. 3111–3119, 2013.
[3] O. Melamud, J. Goldberger, and I. Dagan, “context2vec: Learning generic context embedding with bidirectional lstm,” in Proceedings of the 20th SIGNLL conference on computational natural language learning, pp. 51–61, 2016.
[4] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contex-tualized word representations,” arXiv preprint arXiv:1802.05365, 2018.
[5] J. Howard and S. Ruder, “Universal language model fine-tuning for text classification,” arXiv preprint arXiv:1801.06146, 2018.
[6] S. Thrun and L. Pratt, “Learning to learn: Introduction and overview,” in Learning to learn, pp. 3–17, Springer, 1998.
[7] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on knowledge and data engineering, vol. 22, no. 10, pp. 1345–1359, 2009.
[8] B. McCann, J. Bradbury, C. Xiong, and R. Socher, “Learned in translation: Contextualized word vectors,” arXiv preprint arXiv:1708.00107, 2017.
[9] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
[10] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” Advances in neural information processing systems, vol. 32, 2019.
[11] A. Roberts, C. Raffel, K. Lee, M. Matena, N. Shazeer, P. J. Liu, S. Narang, W. Li, and Y. Zhou,
“Exploring the limits of transfer learning with a unified text-to-text transformer,” 2019.
[12] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
[13] L. Dong, N. Yang, W. Wang, F. Wei, X. Liu, Y. Wang, J. Gao, M. Zhou, and H.-W. Hon, “Uni-
fied language model pre-training for natural language understanding and generation,” arXiv preprint
arXiv:1905.03197, 2019.
[14] K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu, “Mass: Masked sequence to sequence pre-training for language generation,” arXiv preprint arXiv:1905.02450, 2019.
[15] M. Joshi, D. Chen, Y. Liu, D. S. Weld, L. Zettlemoyer, and O. Levy, “Spanbert: Improving pre-training by representing and predicting spans,” Transactions of the Association for Computational Linguistics, vol. 8, pp. 64–77, 2020.
[16] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pre-training text encoders as discriminators rather than generators,” arXiv preprint arXiv:2003.10555, 2020.

















