奧巴馬完變白種人?GFP-GAN達到盲人臉修復新里程碑
盲人臉修復(blind face restoration)是從低質量的人臉中恢復出高質量人臉的過程。這些質量較低的肖像圖可能由各種原因導致退化,如低分辨率,噪音,模糊或是被壓縮。
和一般的圖像修復相比,人臉修復更加注重細節,如一些皺紋、酒窩等都需要恢復出來才能讓人感覺這個系統不錯,也就是說,這是一個粒度更細的圖像修復任務。
其次,如標題中 blind 所言,照片的退化函數的類型、數量我們是無法事先獲悉的。通常的圖像修復都是針對一種退化場景設計的,比如,在去噪任務中,可能就只是針對某種或某幾種噪聲而言,而不考慮圖像模糊等其他因素,因此任務相對簡單。
但如果退化的種類太多,退化函數本身可能會非常復雜,即使神經網絡也未必能近似出來。
之前盲人臉恢復的研究通常依賴于面部幾何特征或參考之前照片細節進行恢復。但這類方法在現實場景中的適用性十分有限,低質量的輸入通常無法提供準確的幾何先驗,也無法獲得高質量的參考。
針對這個問題,騰訊PCG的應用研究中心ARC實驗室提出了GFP-GAN模型,利用封裝在預訓練面部GAN中的豐富多樣的先驗信息進行盲面部修復。這種生成性面部先驗模型(Generative Facial Prior, GFP)通過空間特征變換層被納入到面部恢復過程中,這使得該方法能夠實現真實性和保真度的良好平衡。

并且得益于強大的通用面部先驗和精細設計,GFP-GAN只需一次前向傳遞即可同時修復面部細節和增強顏色,而GAN inversion方法需要在推理時進行特定圖像的優化。
文章的第一作者是騰訊 ARC 實驗室(深圳應用研究中心)的研究員,在香港中文大學多媒體實驗室獲得博士學位,并在湯曉鷗教授和Chen Change Loy教授的指導下進行研究。
于2016年獲得浙江大學工程學士學位。研究興趣包括計算機視覺和深度學習,尤其關注圖像/視頻恢復任務,如超分辨率。
主流的圖像修復技術還是對抗生成網絡GAN,但如何用好GAN是個學問。
GFP-GAN 進行真實世界盲人臉復原。面部先驗知識隱含在像 StyleGAN 這樣經過訓練的面部 GAN 模型中。這些面部GAN模型可以生成具有各種各樣的面孔,可以生成多種臉型、多種膚色、紋理特征的面部。

這里的難點涉及到將這些生成的先驗納入修復過程。在過去,研究通常使用 GAN inversion方法來恢復。在這個過程中,退化的圖像首先被反轉回一個預訓練的 GAN隱空間的編碼,之后進行緩慢的image-specific的優化重建圖像。
雖然輸出在視覺上是真實的,但是它們的保真度很低。
GFP-GAN 通過使用了一個巧妙的設計來解決這些問題,有助于在single forward pass中平衡真實性和保真度。
GFP-GAN 包括一個退化清除模塊和一個預訓練的面部 GAN 作為面部先驗。這兩個模塊通過直接的隱編碼映射和多個信道分割空間特征變換(CS-SFT)層以粗到精的方式連接。
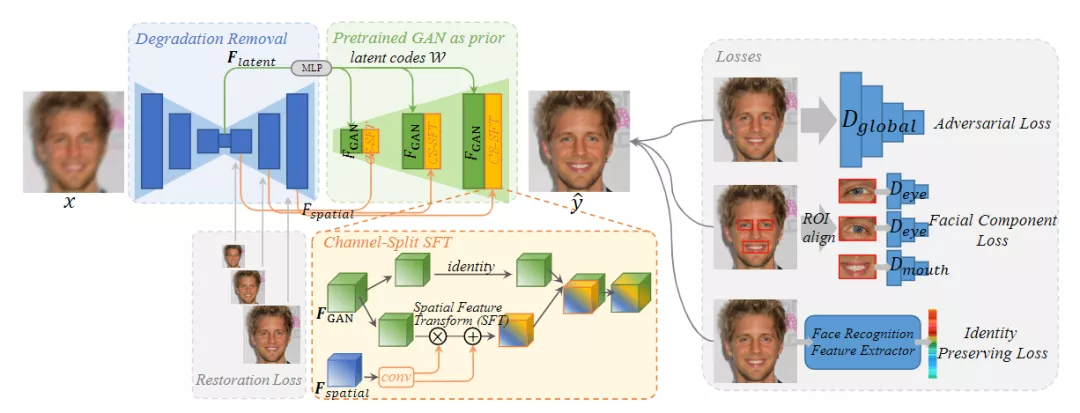
CS-SFT 層對特征進行空間調節。左邊的特征是直接通過信息保存,其中包含生成預先,同時保持高保真度。
研究人員還引入了面部部件損失( facial component loss),使用局部判別器來增強不變的面部細節,同時通過識別保留損失(identity preserving loss)來提高保真度。
盡管在改善盲人影像復原方面取得了進展,但仍然面臨很多難點,GFP-GAN 方法也不能很好地解決。按照作者的說法,盡管 GFP-GAN 在各種人口群體的大多數面孔上表現良好,但當輸入的圖像是灰度圖像時,問題就出現了。這可能會導致輸出有顏色偏差,因為輸入中并不包含足夠判斷膚色的顏色信息。

此外,如果退化的真實圖像十分嚴重的,修復的面部細節就完全是由 GFP-GAN 生成的了,也就是說跟原圖關系不大。由于合成退化和訓練數據分布不同于現實世界中的數據分布,這種方法也容易對非常大的姿勢產生非自然的結果。作者認為,這種局限性可以通過使用真實數據的分布來克服,而不是僅僅依賴于合成數據。
人臉修復是一個棘手的領域,尤其是在偏見因素方面。最近發生的一個有趣的事是PULSE 算法將一張低質量的巴拉克•奧巴馬(Barack Obama)照片進行了高倍放大,從而輸出了一張高分辨率的白人照片。這種偏差問題在機器學習中非常普遍,因為人臉識別算法在非白人和女性面孔上的數據收集較少。

人臉盲修復已經是CV中重要研究領域,所以相關的工作也有很多,例如最近的 CVPR 2021中,有研究人員引入了漸進式語義感知風格轉換框架 (progressive semantic-aware style transformation framework-GAN, PSFR-GAN)方法。該技術通過語義感知樣式轉換恢復低質量的人臉圖像,首先建立一個多尺度輸入金字塔,然后逐步從粗到精調整不同尺度的特征。

DeblurGAN 使用端到端的 GAN 進行單幅圖像運動去模糊。這種方法可以提高模型的去模糊效率、靈活性和質量,是基于條件 GAN 與雙尺度判別器(double-scale discriminator)。作者聲稱這是第一次將特征金字塔網絡作為 Deblur-GAN 生成器中的核心構建模塊納入到去模糊中。

mGANprior 的方法將訓練好的 GANs 作為各種圖像處理任務之前的有效工具。該方法在生成器的中間層生成多個特征映射,然后根據自適應信道重要度對其進行合成,恢復輸入圖像。