Kafka 精妙的高性能設(shè)計之一
這是《吃透 MQ 系列》之 Kafka 的第 4 篇,錯過前 3 篇的,通過下面的鏈接一睹為快:
第 2 篇:Kafka 架構(gòu)設(shè)計的任督二脈
第 3 篇文章我深入剖析了 Kafka 選用「日志文件」作為存儲方案的來龍去脈以及背后「磁盤順序?qū)?+ 稀疏索引」的精妙設(shè)計思路。
但是,Kafka 能做到單機每秒幾十萬的吞吐量,它的性能優(yōu)化手段絕不止這一點。
Kafka 的高性能設(shè)計可以說是全方位的,從 Prodcuer 、到 Broker、再到 Consumer,Kafka 在掏空心思地優(yōu)化每一個細節(jié),最終才做到了這樣的極致性能。
這篇文章我想先帶大家建立一個高性能設(shè)計的思維模式,然后再一探究竟 Kafka 的高性能設(shè)計方案,最終讓大家更體系地掌握所有知識點,并理解它的設(shè)計哲學(xué)。
一. 如何理解高性能設(shè)計?
我們暫且把 Kafka 拋在一邊,先嘗試理解下高性能設(shè)計的本質(zhì)。
有過高并發(fā)開發(fā)經(jīng)驗的同學(xué),對于線程池、多級緩存、IO 多路復(fù)用、零拷貝等技術(shù)概念早就了然于胸,但是返璞歸真,這些技術(shù)手段的本質(zhì)到底是什么?
這其實是一個系統(tǒng)性的問題,至少需要深入到操作系統(tǒng)層面,從 CPU 和存儲入手,去了解底層的實現(xiàn)機制,然后再自底往上,一層一層去解密和貫穿起來。
但是站在更高的視角來看,我認為:高性能設(shè)計其實萬變不離其宗,一定是從「計算和 IO」這兩個維度出發(fā),去考慮可能的優(yōu)化點。
那「計算」維度的性能優(yōu)化手段有哪些呢?無外乎這兩種方式:
1、讓更多的核來參與計算:比如用多線程代替單線程、用集群代替單機等。
2、減少計算量:比如用索引來取代全局掃描、用同步代替異步、通過限流來減少請求處理量、采用更高效的數(shù)據(jù)結(jié)構(gòu)和算法等。
再看下「IO」維度的性能優(yōu)化手段又有哪些? 可以通過 Linux 系統(tǒng)的 IO 棧圖來輔助思考。
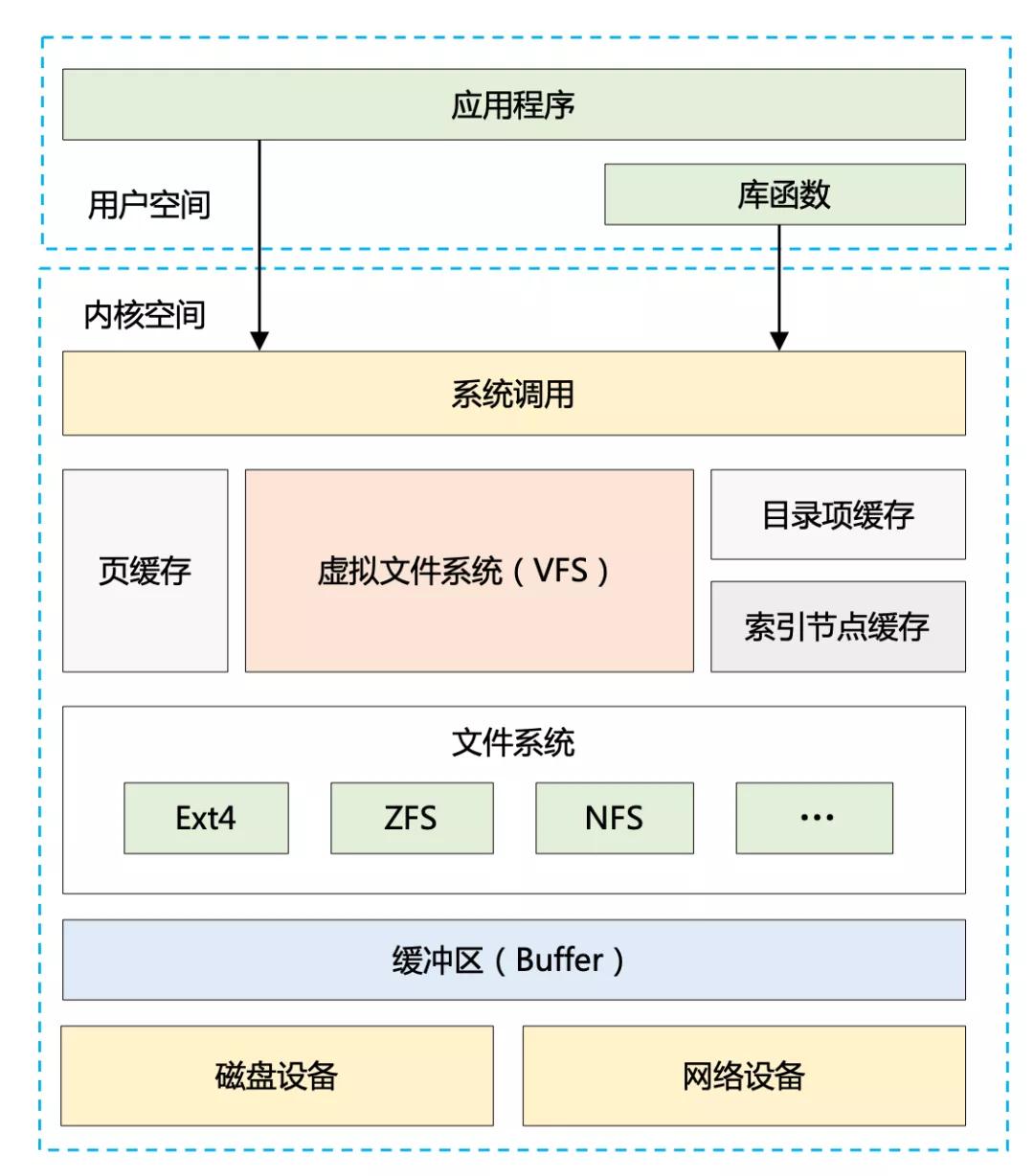
圖 1:Linux 系統(tǒng)的 IO 棧圖
可以看到,整個 IO 體系結(jié)構(gòu)是分層的,我們能夠從應(yīng)用程序、操作系統(tǒng)、磁盤等各個層次來考慮性能優(yōu)化,而所有這些手段又幾乎圍繞以下兩個方面展開:
1、加快 IO 速度:比如用磁盤順序?qū)懘骐S機寫、用 NIO 代替 BIO、用性能更好的 SSD 代替機械硬盤等。
2、減少 IO 次數(shù)或者 IO 數(shù)據(jù)量:比如借助系統(tǒng)緩存或者外部緩存、通過零拷貝技術(shù)減少 IO 復(fù)制次數(shù)、批量讀寫、數(shù)據(jù)壓縮等。
上面這些內(nèi)容可以理解成高性能設(shè)計的「道」,當(dāng)然絕不是幾百字就可以說清楚的,我更多的是拋磚引玉,用另外一個視角來看高并發(fā),給大家一個方向上的指引。
當(dāng)大家抓住了「計算和 IO」這兩個最本質(zhì)的東西,然后以這兩點作為根,再去探究這兩個維度分別有哪些性能優(yōu)化手段?它們的原理又是什么樣的?便能一層一層剝開高性能設(shè)計的神秘面紗,形成可靠的知識體系。
這種分析方法可用來研究 Kafka,同樣可以用來研究我們熟知的 Redis、ES 以及其他高性能的應(yīng)用系統(tǒng)。
二. Kafka 高性能設(shè)計的全景圖
有了高性能設(shè)計的思維模式后,我們再回到 Kafka 本身進行分析。
前文提到過 Kafka 的性能優(yōu)化手段非常豐富,至少有 10 條以上的精妙設(shè)計,雖然我們可以從計算和 IO 兩個維度去聯(lián)想這些手段,但是要完整地記住它們,似乎也不是件容易的事。
這樣就引出了另外一個話題:我們應(yīng)該選用一條什么樣的脈絡(luò),去串聯(lián)這些優(yōu)化手段呢?
之前的文章做過分析:不管 Kafka 、RocketMQ 還是其他消息隊列,其本質(zhì)都是「一發(fā)一存一消費」。
我們完全可以順著這條主線去做結(jié)構(gòu)化梳理。基于這個思路,便形成了下面這張 Kafka 高性能設(shè)計的全景圖,我按照生產(chǎn)消息、存儲消息、消費消息 3 個模塊,將 Kafka 最具代表性的 12 條性能優(yōu)化手段做了歸類。
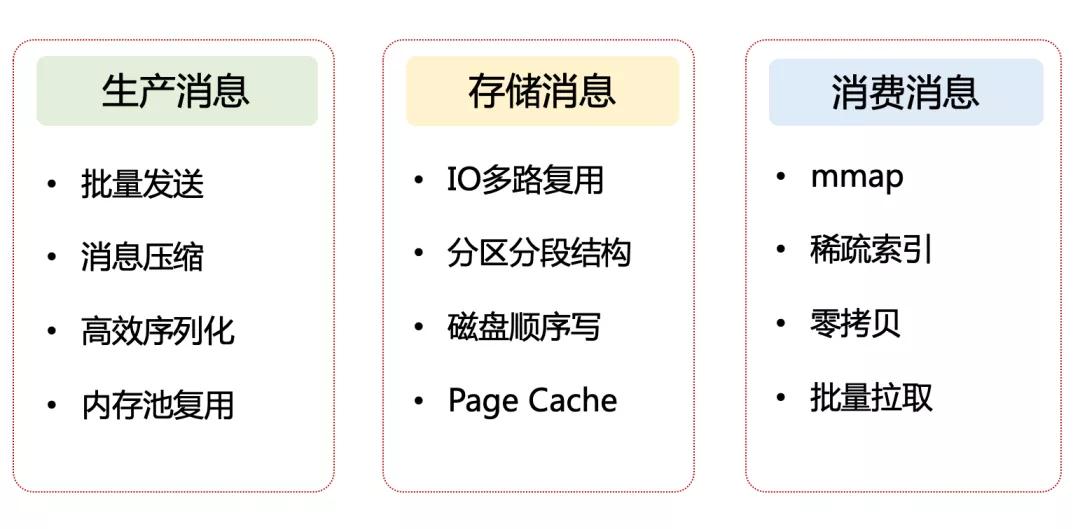
圖 2:Kafka 高性能設(shè)計的全景圖
有了這張全景圖,下面我再挨個分析下每個手段背后的大致原理,并嘗試解讀下 Kafka 的設(shè)計哲學(xué)。
三. 生產(chǎn)消息的性能優(yōu)化手段
我們先從生產(chǎn)消息開始看,下面是 Producer 端所采用的 4 條優(yōu)化手段。
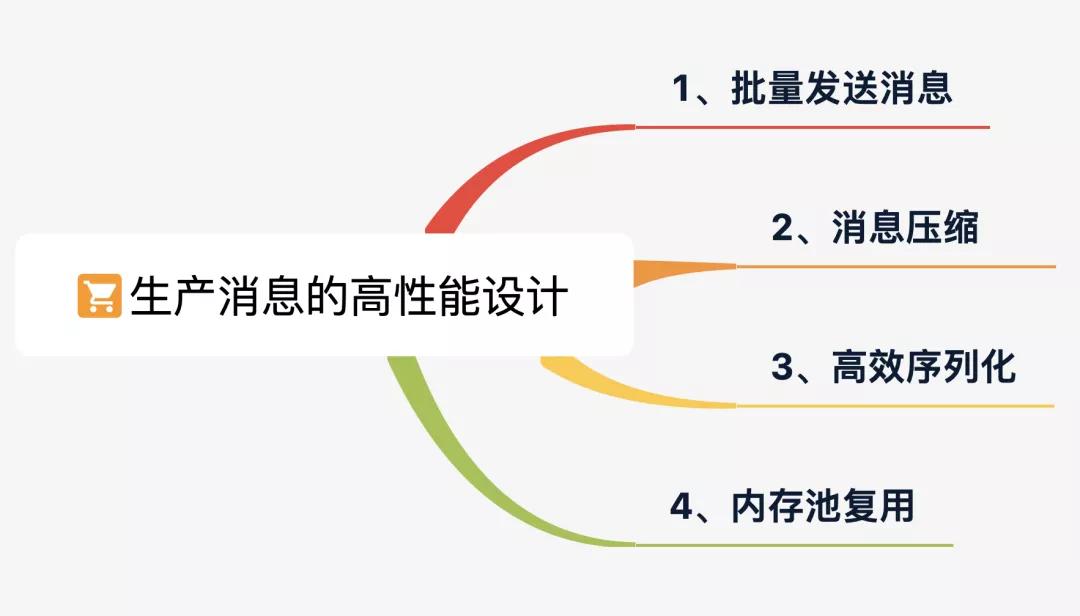
1、批量發(fā)送消息
Kafka 作為一個消息隊列,很顯然是一個 IO 密集型應(yīng)用,它所面臨的挑戰(zhàn)除了磁盤 IO(Broker 端需要對消息持久化),還有網(wǎng)絡(luò) IO(Producer 到 Broker,Broker 到 Consumer,都需要通過網(wǎng)絡(luò)進行消息傳輸)。
在上一篇文章已經(jīng)指出過:磁盤順序 IO 的速度其實非常快,不亞于內(nèi)存隨機讀寫。這樣網(wǎng)絡(luò) IO 便成為了 Kafka 的性能瓶頸所在。
基于這個背景, Kafka 采用了批量發(fā)送消息的方式,通過將多條消息按照分區(qū)進行分組,然后每次發(fā)送一個消息集合,從而大大減少了網(wǎng)絡(luò)傳輸?shù)? overhead。
看似很平常的一個手段,其實它大大提升了 Kafka 的吞吐量,而且它的精妙之處遠非如此,下面幾條優(yōu)化手段都和它息息相關(guān)。
2、消息壓縮
消息壓縮的目的是為了進一步減少網(wǎng)絡(luò)傳輸帶寬。而對于壓縮算法來說,通常是:數(shù)據(jù)量越大,壓縮效果才會越好。
因為有了批量發(fā)送這個前期,從而使得 Kafka 的消息壓縮機制能真正發(fā)揮出它的威力(壓縮的本質(zhì)取決于多消息的重復(fù)性)。對比壓縮單條消息,同時對多條消息進行壓縮,能大幅減少數(shù)據(jù)量,從而更大程度提高網(wǎng)絡(luò)傳輸率。
有文章對 Kafka 支持的三種壓縮算法:gzip、snappy、lz4 進行了性能對比,測試 2 萬條消息,效果如下:
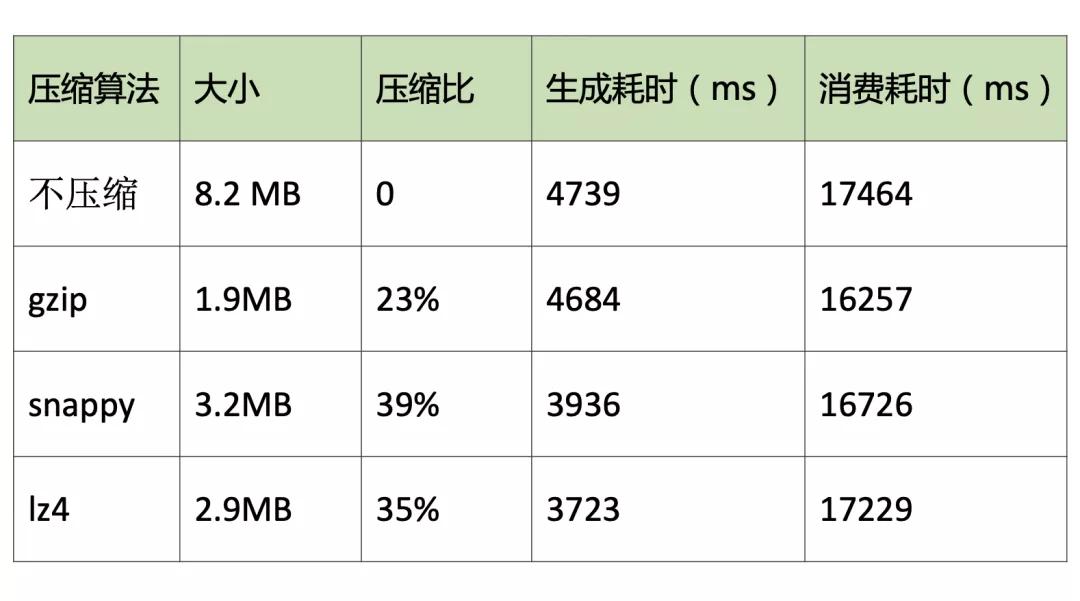
圖 3:壓縮效果對比,來源:https://www.jianshu.com/p/d69e27749b00
整體來看,gzip 壓縮效果最好,但是生成耗時更長,綜合對比 lz4 性能最佳。
其實壓縮消息不僅僅減少了網(wǎng)絡(luò) IO,它還大大降低了磁盤 IO。因為批量消息在持久化到 Broker 中的磁盤時,仍然保持的是壓縮狀態(tài),最終是在 Consumer 端做了解壓縮操作。
這種端到端的壓縮設(shè)計,其實非常巧妙,它又大大提高了寫磁盤的效率。
3、高效序列化
Kafka 消息中的 Key 和 Value,都支持自定義類型,只需要提供相應(yīng)的序列化和反序列化器即可。因此,用戶可以根據(jù)實際情況選用快速且緊湊的序列化方式(比如 ProtoBuf、Avro)來減少實際的網(wǎng)絡(luò)傳輸量以及磁盤存儲量,進一步提高吞吐量。
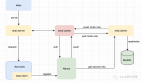
4、內(nèi)存池復(fù)用
前面說過 Producer 發(fā)送消息是批量的,因此消息都會先寫入 Producer 的內(nèi)存中進行緩沖,直到多條消息組成了一個 Batch,才會通過網(wǎng)絡(luò)把 Batch 發(fā)給 Broker。
當(dāng)這個 Batch 發(fā)送完畢后,顯然這部分數(shù)據(jù)還會在 Producer 端的 JVM 內(nèi)存中,由于不存在引用了,它是可以被 JVM 回收掉的。
但是大家都知道,JVM GC 時一定會存在 Stop The World 的過程,即使采用最先進的垃圾回收器,也勢必會導(dǎo)致工作線程的短暫停頓,這對于 Kafka 這種高并發(fā)場景肯定會帶來性能上的影響。
有了這個背景,便引出了 Kafka 非常優(yōu)秀的內(nèi)存池機制,它和連接池、線程池的本質(zhì)一樣,都是為了提高復(fù)用,減少頻繁的創(chuàng)建和釋放。
具體是如何實現(xiàn)的呢?其實很簡單:Producer 一上來就會占用一個固定大小的內(nèi)存塊,比如 64MB,然后將 64 MB 劃分成 M 個小內(nèi)存塊(比如一個小內(nèi)存塊大小是 16KB)。
當(dāng)需要創(chuàng)建一個新的 Batch 時,直接從內(nèi)存池中取出一個 16 KB 的內(nèi)存塊即可,然后往里面不斷寫入消息,但最大寫入量就是 16 KB,接著將 Batch 發(fā)送給 Broker ,此時該內(nèi)存塊就可以還回到緩沖池中繼續(xù)復(fù)用了,根本不涉及垃圾回收。最終整個流程如下圖所示:
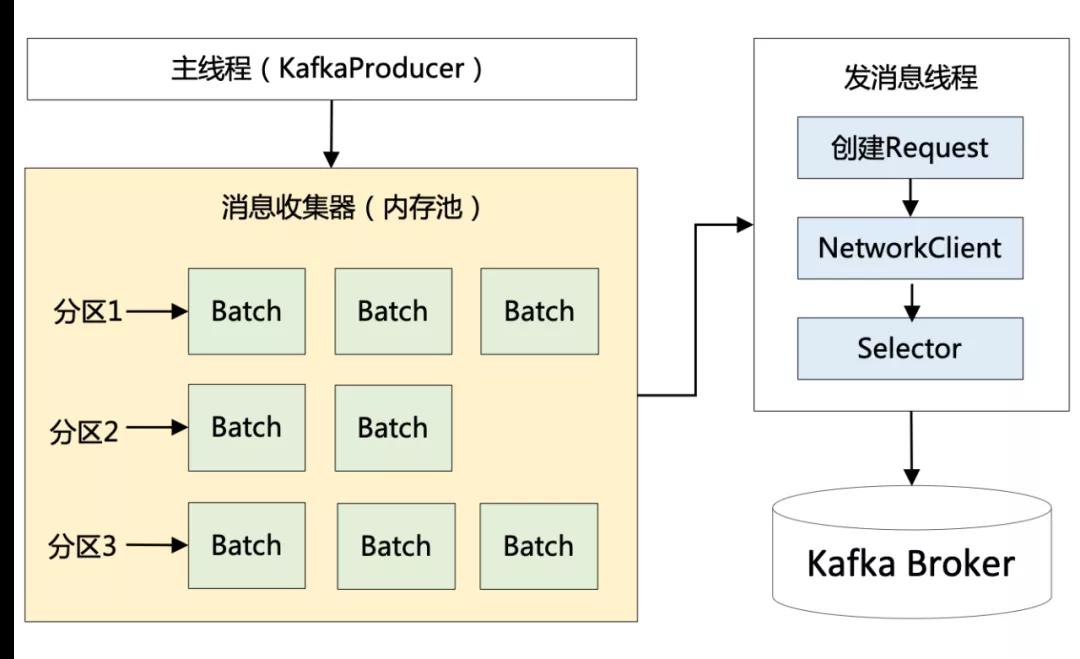
圖 4:Kafka 發(fā)送端的流程
了解了 Producer 端上面 4 條高性能設(shè)計后,大家一定會有一個疑問:傳統(tǒng)的數(shù)據(jù)庫或者消息中間件都是想辦法讓 Client 端更輕量,將 Server 設(shè)計成重量級,僅讓 Client 充當(dāng)應(yīng)用程序和 Server 之間的接口。
但是 Kafka 卻反其道而行之,采取了獨具一格的設(shè)計思路,在將消息發(fā)送給 Broker 之前,需要先在 Client 端完成大量的工作,例如:消息的分區(qū)路由、校驗和的計算、壓縮消息等。這樣便很好地分攤 Broker 的計算壓力。
可見,沒有最好的設(shè)計,只有最合適的設(shè)計,這就是架構(gòu)的本源。
四. 寫在最后
Kafka 在創(chuàng)造一個以性能為核心導(dǎo)向的解決方案上做得極其出色,它有非常多的設(shè)計理念值得深入研究和學(xué)習(xí)。
考慮篇幅問題,我將 Kafka 的高性能設(shè)計分成了上下兩篇,下一篇將繼續(xù)展開闡述剩余 8 條高性能設(shè)計手段以及背后的設(shè)計思想。
看到這里,我更希望大家能建立起高性能設(shè)計的思維模式以及學(xué)習(xí)方法,這些技巧同樣可以幫助你吃透其他高性能的中間件。