Linux中TCP三次握手與四次揮手介紹及調優
TCP介紹
TCP是一種面向連接的單播協議,在發送數據前,通信雙方必須在彼此間建立一條連接。所謂的“連接”,其實是客戶端和服務器的內存里保存的一份關于對方的信息,如ip地址、端口號等。
TCP可以看成是一種字節流,它會處理IP層或以下的層的丟包、重復以及錯誤問題。在連接的建立過程中,雙方需要交換一些連接的參數。這些參數可以放在TCP頭部。
TCP提供了一種可靠、面向連接、字節流、傳輸層的服務,采用三次握手建立一個連接。采用4次揮手來關閉一個連接。
TCP三次握手
客戶端和服務端通信前要進行連接,“3次握手”的作用就是雙方都能明確自己和對方的收、發能力是正常的。
- 第一次握手:客戶端發送網絡包,服務端收到了。這樣服務端就能得出結論:客戶端的發送能力、服務端的接收能力是正常的。
- 第二次握手:服務端發包,客戶端收到了。這樣客戶端就能得出結論:服務端的接收、發送能力,客戶端的接收、發送能力是正常的。從客戶端的視角來看,我接到了服務端發送過來的響應數據包,說明服務端接收到了我在第一次握手時發送的網絡包,并且成功發送了響應數據包,這就說明,服務端的接收、發送能力正常。而另一方面,我收到了服務端的響應數據包,說明我第一次發送的網絡包成功到達服務端,這樣,我自己的發送和接收能力也是正常的。
- 第三次握手:客戶端發包,服務端收到了。這樣服務端就能得出結論:客戶端的接收、發送能力,服務端的發送、接收能力是正常的。第一、二次握手后,服務端并不知道客戶端的接收能力以及自己的發送能力是否正常。而在第三次握手時,服務端收到了客戶端對第二次握手作的回應。從服務端的角度,我在第二次握手時的響應數據發送出去了,客戶端接收到了。所以,我的發送能力是正常的。而客戶端的接收能力也是正常的。
經歷了上面的三次握手過程,客戶端和服務端都確認了自己的接收、發送能力是正常的。之后就可以正常通信了。
TCP三次握手中的狀態
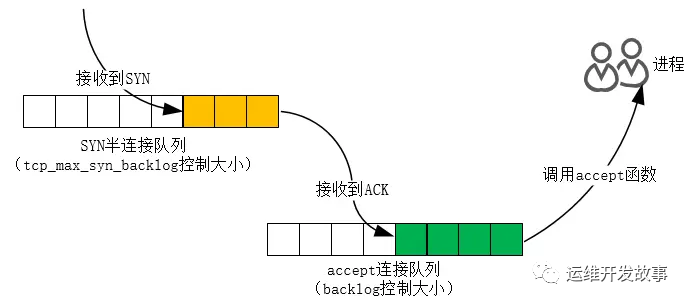
在 TCP 三次握手的時候,Linux 內核會維護兩個隊列,分別是:
- 半連接隊列,也稱 SYN 隊列;
- 全連接隊列,也稱 accepet 隊列;
服務端收到客戶端發起的 SYN 請求后,內核會把該連接存儲到半連接隊列,并向客戶端響應 SYN+ACK,接著客戶端會返回 ACK,服務端收到第三次握手的 ACK 后,內核會把連接從半連接隊列移除,然后創建新的完全的連接,并將其添加到 accept 隊列,等待進程調用 accept 函數時把連接取出來。

不管是半連接隊列還是全連接隊列,都有最大長度限制,超過限制時,內核會直接丟棄,或返回 RST 包。
半連接
很遺憾,我們沒有命令可以查看系統的半連接隊列數量。但是我們可以抓住 TCP 半連接的特點,就是服務端處于 SYN_RECV 狀態的 TCP 連接,就是 TCP 半連接隊列。使用如下命令計算當前 TCP 半連接隊列長度:
- $ netstat |grep SYN_RECV |wc -l
- 1723
SYN_RECV 狀態下,服務器必須建立一個 SYN 半連接隊列來維護未完成的握手信息,當這個隊列溢出后,服務器將無法再建立新連接。
如何模擬 TCP 半連接隊列溢出場景?
模擬 TCP 半連接溢出場景不難,實際上就是對服務端一直發送 TCP SYN 包,但是不回第三次握手 ACK,這樣就會使得服務端有大量的處于 SYN_RECV 狀態的 TCP 連接。這其實也就是所謂的 SYN 洪泛、SYN 攻擊、DDos 攻擊。
實驗環境:
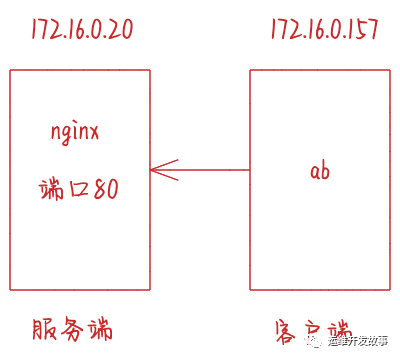
- 客戶端和服務端都是 CentOS Linux release 7.9.2009 (Core) ,Linux 內核版本 3.10.0-1160.15.2.el7.x86_64
- 服務端 IP 172.16.0.20,客戶端 IP 172.16.0.157
- 服務端是 Nginx 服務,端口為 80
本次實驗使用 hping3 工具模擬 SYN 攻擊:
- $ hping3 -S -p 80 --flood 172.16.0.20
- HPING 172.16.0.20 (eth0 172.16.0.20): S set, 40 headers + 0 data bytes
- hping in flood mode, no replies will be shown
新連接建立失敗的原因有很多,怎樣獲得由于隊列已滿而引發的失敗次數呢?netstat -s 命令給出的統計結果中可以得到。
- $ netstat -s|grep "SYNs to LISTEN"
- 1541918 SYNs to LISTEN sockets dropped
這里給出的是隊列溢出導致 SYN 被丟棄的個數。注意這是一個累計值,如果數值在持續增加,則應該調大 SYN 半連接隊列。修改隊列大小的方法,是設置 Linux 的 tcp_max_syn_backlog 參數:
- sysctl -w net.ipv4.tcp_max_syn_backlog = 1024
如果 SYN 半連接隊列已滿,只能丟棄連接嗎?并不是這樣,開啟 syncookies 功能就可以在不使用 SYN 隊列的情況下成功建立連接。syncookies 是這么做的:服務器根據當前狀態計算出一個值,放在己方發出的 SYN+ACK 報文中發出,當客戶端返回 ACK 報文時,取出該值驗證,如果合法,就認為連接建立成功,如下圖所示。
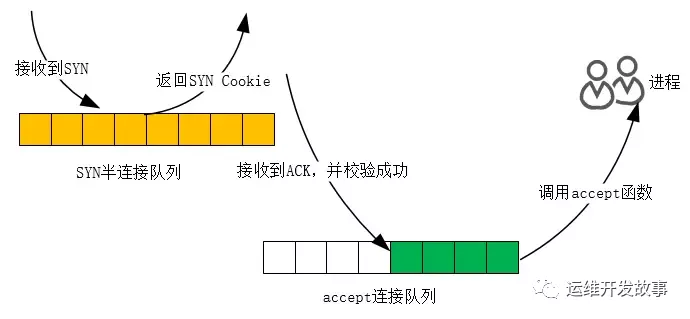
Linux 下怎樣開啟 syncookies 功能呢?修改 tcp_syncookies 參數即可,其中值為 0 時表示關閉該功能,2 表示無條件開啟功能,而 1 則表示僅當 SYN 半連接隊列放不下時,再啟用它。由于 syncookie 僅用于應對 SYN 泛洪攻擊(攻擊者惡意構造大量的 SYN 報文發送給服務器,造成 SYN 半連接隊列溢出,導致正常客戶端的連接無法建立),這種方式建立的連接,許多 TCP 特性都無法使用。所以,應當把 tcp_syncookies 設置為 1,僅在隊列滿時再啟用。
- sysctl -w net.ipv4.tcp_syncookies = 1
全連接
在服務端可以使用 ss 命令,來查看 TCP 全連接隊列的情況:但需要注意的是 ss 命令獲取的 Recv-Q/Send-Q 在「LISTEN 狀態」和「非 LISTEN 狀態」所表達的含義是不同的。從下面的內核代碼可以看出區別:
- static void tcp_diag_get_info(struct sock *sk, struct inet_diag_msg *r,
- void *_info)
- {
- const struct tcp_sock *tp = tcp_sk(sk);
- struct tcp_info *info = _info;
- if (sk->sk_state == TCP_LISTEN) {
- r->idiag_rqueue = sk->sk_ack_backlog;
- r->idiag_wqueue = sk->sk_max_ack_backlog;
- } else {
- r->idiag_rqueue = tp->rcv_nxt - tp->copied_seq;
- r->idiag_wqueue = tp->write_seq - tp->snd_una;
- }
- if (info != NULL)
- tcp_get_info(sk, info);
- }
在「LISTEN 狀態」時,Recv-Q/Send-Q 表示的含義如下:
- $ ss -ltnp
- LISTEN 0 1024 *:8081 *:* users:(("java",pid=5686,fd=310))
- Recv-Q:當前全連接隊列的大小,也就是當前已完成三次握手并等待服務端 accept() 的 TCP 連接;
- Send-Q:當前全連接最大隊列長度,上面的輸出結果說明監聽 8088 端口的 TCP 服務,最大全連接長度為 1024;
在「非 LISTEN 狀態」時,Recv-Q/Send-Q 表示的含義如下:
- $ ss -tnp
- ESTAB 0 0 172.16.0.20:57672 172.16.0.20:2181 users:(("java",pid=5686,fd=292))
- Recv-Q:已收到但未被應用進程讀取的字節數;
- Send-Q:已發送但未收到確認的字節數;
如何模擬 TCP 全連接隊列溢出的場景?
實驗環境:
- 客戶端和服務端都是 CentOS Linux release 7.9.2009 (Core) ,Linux 內核版本 3.10.0-1160.15.2.el7.x86_64
- 服務端 IP 172.16.0.20,客戶端 IP 172.16.0.157
- 服務端是 Nginx 服務,端口為 80
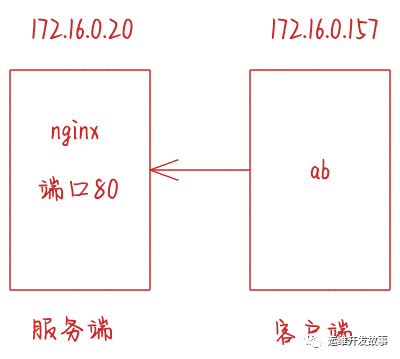
ab是apache bench命令的縮寫。ab是apache自帶的壓力測試工具。ab非常實用,它不僅可以對apache服務器進行網站訪問壓力測試,也可以對或其它類型的服務器進行壓力測試。比如nginx、tomcat、IIS等。ab的原理:ab命令會創建多個并發訪問線程,模擬多個訪問者同時對某一URL地址進行訪問。它的測試目標是基于URL的,因此,它既可以用來測試apache的負載壓力,也可以測試nginx、lighthttp、tomcat、IIS等其它Web服務器的壓力。ab命令對發出負載的計算機要求很低,它既不會占用很高CPU,也不會占用很多內存。但卻會給目標服務器造成巨大的負載,其原理類似CC攻擊。自己測試使用也需要注意,否則一次上太多的負載。可能造成目標服務器資源耗完,嚴重時甚至導致死機。
TCP 全連接隊列的最大值取決于 somaxconn 和 backlog 之間的最小值,也就是 min(somaxconn, backlog)。從下面的 Linux 內核代碼可以得知:
- int __sys_listen(int fd, int backlog)
- {
- struct socket *sock;
- int err, fput_needed;
- int somaxconn;
- sock = sockfd_lookup_light(fd, &err, &fput_needed);
- if (sock) {
- somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
- if ((unsigned int)backlog > somaxconn)
- backlog = somaxconn;
- err = security_socket_listen(sock, backlog);
- if (!err)
- err = sock->ops->listen(sock, backlog);
- fput_light(sock->file, fput_needed);
- }
- return err;
- }
- somaxconn 是 Linux 內核的參數,默認值是 128,可以通過 /proc/sys/net/core/somaxconn 來設置其值;我們設置為40000了。
- backlog 是 listen(int sockfd, int backlog) 函數中的 backlog 大小,Nginx 默認值是 511,可以通過修改配置文件設置其長度;
所以測試環境的 TCP 全連接隊列最大值為 min(128, 511),也就是 511,可以執行 ss 命令查看:
- ss -tulnp|grep 80
- tcp LISTEN 0 511 *:80 *:* users:(("nginx",pid=22913,fd=6),("nginx",pid=22912,fd=6),("nginx",pid=22911,fd=6))
- tcp LISTEN 0 511 [::]:80 [::]:* users:(("nginx",pid=22913,fd=7),("nginx",pid=22912,fd=7),("nginx",pid=22911,fd=7))
客戶端執行 ab 命令對服務端發起壓力測試,并發 1 萬個連接,發送10萬個包:
- -n表示總的請求數為10000
- -c表示并發請求數為1000
- ab -c 10000 -n 100000 http://172.16.0.20:80/
- This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
- Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
- Licensed to The Apache Software Foundation, http://www.apache.org/
- Benchmarking 172.16.0.20 (be patient)
- Completed 10000 requests
- Completed 20000 requests
- Completed 30000 requests
- Completed 40000 requests
- Completed 50000 requests
- Completed 60000 requests
- Completed 70000 requests
- Completed 80000 requests
- Completed 90000 requests
- Completed 100000 requests
- Finished 100000 requests
- Server Software: nginx/1.20.1
- Server Hostname: 172.16.0.20
- Server Port: 80
- Document Path: /
- Document Length: 4833 bytes
- Concurrency Level: 10000
- Time taken for tests: 2.698 seconds
- Complete requests: 100000
- Failed requests: 167336
- (Connect: 0, Receive: 0, Length: 84384, Exceptions: 82952)
- Write errors: 0
- Total transferred: 86399264 bytes
- HTML transferred: 82392984 bytes
- Requests per second: 37069.19 [#/sec] (mean)
- Time per request: 269.766 [ms] (mean)
- Time per request: 0.027 [ms] (mean, across all concurrent requests)
- Transfer rate: 31276.86 [Kbytes/sec] received
- Connection Times (ms)
- min mean[+/-sd] median max
- Connect: 0 129 151.5 106 1144
- Processing: 39 121 37.7 114 239
- Waiting: 0 23 51.8 0 159
- Total: 142 250 152.4 224 1346
- Percentage of the requests served within a certain time (ms)
- 50% 224
- 66% 227
- 75% 232
- 80% 236
- 90% 283
- 95% 299
- 98% 1216
- 99% 1228
- 100% 1346 (longest request)
其間共執行了兩次 ss 命令,從上面的輸出結果,可以發現當前 TCP 全連接隊列上升到了 512 大小,超過了最大 TCP 全連接隊列。
- ss -tulnp|grep 80
- tcp LISTEN 411 511 *:80 *:* users:(("nginx",pid=22913,fd=6),("nginx",pid=22912,fd=6),("nginx",pid=22911,fd=6))
- ss -tulnp|grep 80
- tcp LISTEN 512 511 *:80 *:* users:(("nginx",pid=22913,fd=6),("nginx",pid=22912,fd=6),("nginx",pid=22911,fd=6))
當超過了 TCP 最大全連接隊列,服務端則會丟掉后續進來的 TCP 連接,丟掉的 TCP 連接的個數會被統計起來,我們可以使用 netstat -s 命令來查看:
- netstat -s|grep overflowed
- 1233972 times the listen queue of a socket overflowed
上面看到的 1233972 times ,表示全連接隊列溢出的次數,注意這個是累計值。可以隔幾秒鐘執行下,如果這個數字一直在增加的話肯定全連接隊列滿了。
- netstat -s|grep overflowed
- 1292022 times the listen queue of a socket overflowed
從上面的模擬結果,可以得知,當服務端并發處理大量請求時,如果 TCP 全連接隊列過小,就容易溢出。發生 TCP 全連接隊列溢出的時候,后續的請求就會被丟棄,這樣就會出現服務端請求數量上不去的現象。
Linux 有個參數可以指定當 TCP 全連接隊列滿了會使用什么策略來回應客戶端
實際上,丟棄連接只是 Linux 的默認行為,我們還可以選擇向客戶端發送 RST 復位報文,告訴客戶端連接已經建立失敗。
- $ cat /proc/sys/net/ipv4/tcp_abort_on_overflow
- 0
tcp_abort_on_overflow 共有兩個值分別是 0 和 1,其分別表示:
- 0 :如果全連接隊列滿了,那么 server 扔掉 client 發過來的 ack ;
- 1 :如果全連接隊列滿了,server 發送一個 reset 包給 client,表示廢掉這個握手過程和這個連接;
如果要想知道客戶端連接不上服務端,是不是服務端 TCP 全連接隊列滿的原因,那么可以把 tcp_abort_on_overflow 設置為 1,這時如果在客戶端異常中可以看到很多 connection reset by peer 的錯誤,那么就可以證明是由于服務端 TCP 全連接隊列溢出的問題。通常情況下,應當把 tcp_abort_on_overflow 設置為 0,因為這樣更有利于應對突發流量。所以,tcp_abort_on_overflow 設為 0 可以提高連接建立的成功率,只有你非常肯定 TCP 全連接隊列會長期溢出時,才能設置為 1 以盡快通知客戶端。
- sysctl -w net.ipv4.tcp_abort_on_overflow = 0
如何增大 TCP 全連接隊列呢?
根據上面提到的TCP 全連接隊列的最大值取決于 somaxconn 和 backlog 之間的最小值,也就是 min(somaxconn, backlog)。我們現在調整somaxconn值:
- $ sysctl -w net.core.somaxconn=65535
調整nginx配置:
- server {
- listen 80 backlog=65535;
- ...
最后要重啟 Nginx 服務,因為只有重新調用 listen() 函數 TCP 全連接隊列才會重新初始化。服務端執行 ss 命令,查看 TCP 全連接隊列大小:
- $ ss -tulntp|grep 80
- tcp LISTEN 0 65535 *:80 *:* users:(("nginx",pid=24212,fd=6),("nginx",pid=24211,fd=6),("nginx",pid=24210,fd=6))
從執行結果,可以發現 TCP 全連接最大值為 65535。
增大 TCP 全連接隊列后,繼續壓測
- ab -c 10000 -n 100000 http://172.16.0.20:80/
- This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
- Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
- Licensed to The Apache Software Foundation, http://www.apache.org/
- Benchmarking 172.16.0.20 (be patient)
- Completed 10000 requests
- Completed 20000 requests
- Completed 30000 requests
- Completed 40000 requests
- Completed 50000 requests
- Completed 60000 requests
- Completed 70000 requests
- Completed 80000 requests
- Completed 90000 requests
- Completed 100000 requests
- Finished 100000 requests
- Server Software: nginx/1.20.1
- Server Hostname: 172.16.0.20
- Server Port: 80
- Document Path: /
- Document Length: 4833 bytes
- Concurrency Level: 10000
- Time taken for tests: 2.844 seconds
- Complete requests: 100000
- Failed requests: 178364
- (Connect: 0, Receive: 0, Length: 89728, Exceptions: 88636)
- Write errors: 0
- Total transferred: 57592752 bytes
- HTML transferred: 54922212 bytes
- Requests per second: 35159.35 [#/sec] (mean)
- Time per request: 284.419 [ms] (mean)
- Time per request: 0.028 [ms] (mean, across all concurrent requests)
- Transfer rate: 19774.64 [Kbytes/sec] received
- Connection Times (ms)
- min mean[+/-sd] median max
- Connect: 0 130 18.3 130 172
- Processing: 45 142 40.1 138 281
- Waiting: 0 19 52.4 0 185
- Total: 159 272 31.2 272 390
- Percentage of the requests served within a certain time (ms)
- 50% 272
- 66% 274
- 75% 275
- 80% 276
- 90% 280
- 95% 358
- 98% 370
- 99% 375
- 100% 390 (longest request)
服務端執行 ss 命令,查看 TCP 全連接隊列使用情況:
- $ ss -tulnp|grep 80
- tcp LISTEN 8 65535 *:80 *:* users:(("nginx",pid=24212,fd=6),("nginx",pid=24211,fd=6),("nginx",pid=24210,fd=6))
- $ ss -tulnp|grep 80
- tcp LISTEN 352 65535 *:80 *:* users:(("nginx",pid=24212,fd=6),("nginx",pid=24211,fd=6),("nginx",pid=24210,fd=6))
- $ ss -tulnp|grep 80
- tcp LISTEN 0 65535 *:80 *:* users:(("nginx",pid=24212,fd=6),("nginx",pid=24211,fd=6),("nginx",pid=24210,fd=6))
從上面的執行結果,可以發現全連接隊列使用增長的很快,但是一直都沒有超過最大值,所以就不會溢出,那么 netstat -s 就不會有 TCP 全連接隊列溢出個數繼續增加:
- $ netstat -s|grep overflowed
- 1540879 times the listen queue of a socket overflowed
- $ netstat -s|grep overflowed
- 1540879 times the listen queue of a socket overflowed
- $ netstat -s|grep overflowed
- 1540879 times the listen queue of a socket overflowed
- $ netstat -s|grep overflowed
- 1540879 times the listen queue of a socket overflowed
說明 TCP 全連接隊列最大值從 512 增大到 65535 后,服務端抗住了 10 萬連接并發請求,也沒有發生全連接隊列溢出的現象了。如果持續不斷地有連接因為 TCP 全連接隊列溢出被丟棄,就應該調大 backlog 以及 somaxconn 參數。
TCP四次揮手
- 第一次揮手:主動關閉方發送一個FIN,用來關閉主動方到被動關閉方的數據傳送,也就是主動關閉方告訴被動關閉方:我已經不會再給你發數據了(當然,在fin包之前發送出去的數據,如果沒有收到對應的ack確認報文,主動關閉方依然會重發這些數據),但此時主動關閉方還可以接受數據。
- 第二次揮手:被動關閉方收到FIN包后,發送一個ACK給對方,確認序號為收到序號+1(與SYN相同,一個FIN占用一個序號)。
- 第三次揮手:被動關閉方發送一個FIN,用來關閉被動關閉方到主動關閉方的數據傳送,也就是告訴主動關閉方,我的數據也發送完了,不會再給你發數據了。
- 第四次揮手:主動關閉方收到FIN后,發送一個ACK給被動關閉方,確認序號為收到序號+1,至此,完成四次揮手。
互聯網中往往服務器才是主動關閉連接的一方。這是因為,HTTP 消息是單向傳輸協議,服務器接收完請求才能生成響應,發送完響應后就會立刻關閉 TCP 連接,這樣及時釋放了資源,能夠為更多的用戶服務。
四次揮手的狀態
我們來看斷開連接的時候的狀態時序圖:
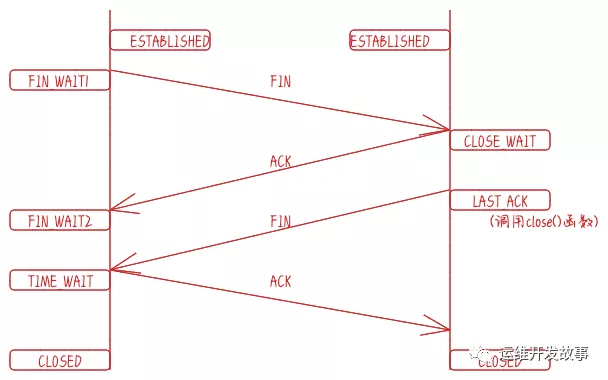
其實四次揮手只涉及兩種報文:FIN 和 ACK。FIN 就是 Finish 結束連接的意思,誰發出 FIN 報文,就表示它將不再發送任何數據,關閉這一方向的傳輸通道。ACK 是 Acknowledge 確認的意思,它用來通知對方,你方的發送通道已經關閉。
- 當主動方關閉連接時,會發送 FIN 報文,此時主動方的連接狀態由 ESTABLISHED 變為 FIN_WAIT1。
- 當被動方收到 FIN 報文后,內核自動回復 ACK 報文,連接狀態由 ESTABLISHED 變為 CLOSE_WAIT,顧名思義,它在等待進程調用 close 函數關閉連接。
- 當主動方接收到這個 ACK 報文后,連接狀態由 FIN_WAIT1 變為 FIN_WAIT2,主動方的發送通道就關閉了。
- 當被動方進入 CLOSE_WAIT 狀態時,進程的 read 函數會返回 0,這樣開發人員就會有針對性地調用 close 函數,進而觸發內核發送 FIN 報文,此時被動方連接的狀態變為 LAST_ACK。當主動方收到這個 FIN 報文時,內核會自動回復 ACK,同時連接的狀態由 FIN_WAIT2 變為 TIME_WAIT,Linux 系統下等待的時間設為 2MSL,MSL 是 Maximum Segment Lifetime,報文最大生存時間,它是任何報文在網絡上存在的最長時間,超過這個時間報文將被丟棄。TIME_WAIT 狀態的連接才會徹底關閉。
當被動方收到 ACK 報文后,連接就會關閉。
主動方TIME_WAIT優化
大量處于 TIME_WAIT 狀態的連接,它們會占用大量內存和端口資源。這時,我們可以優化與 TIME_WAIT 狀態相關的內核選項,比如采取下面幾種措施。
- 增大處于 TIME_WAIT 狀態的連接數量 net.ipv4.tcp_max_tw_buckets ,并增大連接跟蹤表的大小 net.netfilter.nf_conntrack_max。
- sysctl -w net.ipv4.tcp_max_tw_buckets=1048576
- sysctl -w net.netfilter.nf_conntrack_max=1048576
- 減小FIN_WAIT2狀態的參數 net.ipv4.tcp_fin_timeout 的時間和減小TIME_WAIT 狀態的參數net.netfilter.nf_conntrack_tcp_timeout_time_wait的時間 ,讓系統盡快釋放它們所占用的資源。
- sysctl -w net.ipv4.tcp_fin_timeout=15
- sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
- 開啟端口復用 net.ipv4.tcp_tw_reuse。這樣,被 TIME_WAIT 狀態占用的端口,還能用到新建的連接中。
- sysctl -w net.ipv4.tcp_tw_reuse=1
- 增大本地端口的范圍 net.ipv4.ip_local_port_range 。這樣就可以支持更多連接,提高整體的并發能力。
- sysctl -w net.ipv4.ip_local_port_range="1024 65535"
- 增加最大文件描述符的數量。你可以使用 fs.nr_open 和 fs.file-max ,分別增大進程和系統的最大文件描述符數;或在應用程序的 systemd 配置文件中,配置 LimitNOFILE ,設置應用程序的最大文件描述符數。
- sysctl -w fs.nr_open=1048576
- sysctl -w fs.file-max=1048576
巨人的肩膀
[1] 系統性能調優必知必會.陶輝.極客時間.
[2] TCP/IP詳解卷二:實現
本文轉載自微信公眾號「 運維開發故事」,可以通過以下二維碼關注。轉載本文請聯系 運維開發故事公眾號。

【編輯推薦】