性能提升了200%!(優化篇)
最近不少運營同事找到我說:咱們的數據校對系統越來越慢了,要過很久才會顯示出校對結果,你能不能快速優化一下呢?我:好的,我先了解下業務,后續優化下。
優化背景
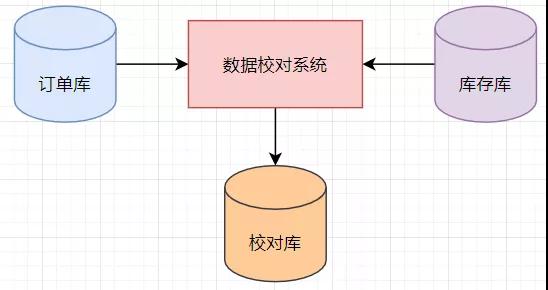
由于這個數據校對系統最初不是我開發的,我了解了下數據校對系統的業務,整體來說,數據校對系統的業務還是比較簡單的。用戶通過商城提交訂單后,會在訂單微服務中生成訂單信息,保存在訂單數據庫中。訂單微服務會調用庫存微服務的接口,扣減商品的庫存數量,并且會將每筆訂單扣減庫存的記錄保存在庫存數據庫中。為了防止用戶提交訂單后沒有扣減庫存,或者重復扣減庫存,數據校對系統每天會校驗訂單中提交的商品數量與扣減的庫存數量是否一致,并且會將校對的結果信息保存到數據校對信息表中。
數據校對系統的總體流程為:先查詢訂單記錄,然后在查詢庫存的扣減記錄,然后對比訂單和庫存扣減記錄,然后將校對的結果信息保存到數據校對信息表中,整體流程如下所示。
為了能夠讓大家更好的了解數據校對系統對于訂單和庫存的校對業務,我將代碼精簡了下,核心業務邏輯代碼如下所示。
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- while(checkOrders != null){
- //查詢未校對的訂單信息
- hasNoOrders = getHasNoOrders();
- //查詢未校對的庫存記錄
- hasNoStock = getHasNoStock();
- //校對數據并返回結果
- checkResult = checkData(hasNoOrders, hasNoStock);
- //將結果信息保存到數據校對信息表中
- saveCheckResult(checkResult);
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- }
好了,上述就是系統優化的背景,想必看到這里,很多小伙伴應該知道問題出在哪里了。我們繼續往下看。
問題分析
雖然很多小伙伴應該已經知道系統性能低下的問題所在了,這里,我們就一起詳細分析下校對系統性能低下的原因。
既然運營的同事說數據校對系統越來越慢了,我們首先要做的就是找到系統的性能瓶頸所在。據了解,目前的數據對賬系統,由于訂單記錄和庫存扣減記錄數據量巨大,所以查詢未校對的訂單信息的方法getHasNoOrders()和查詢為校對的庫存記錄的方法getHasNoStock()相對來說比較慢。并且在數據校對系統中,校對訂單和庫存記錄的方法是單線程執行的,我們可以簡單畫一個時間抽線圖,如下所示。
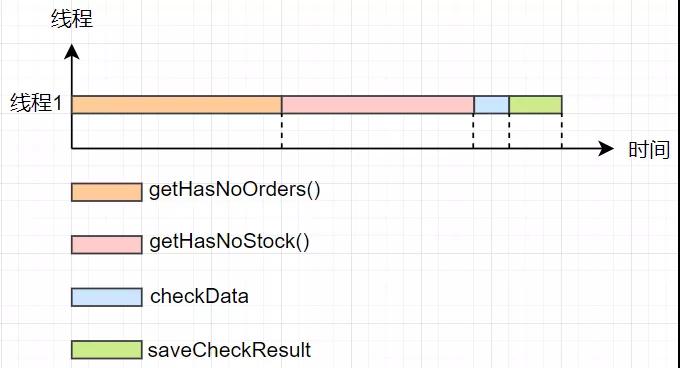
由圖可以看出,以單線程的方式getHasNoOrders()方法和getHasNoStock()方法耗費了大量的時間,這兩個方法本身在邏輯上就是兩個獨立的方法,并且這兩個方法沒有先后的執行的順序依賴。那這兩個方法能不能并行執行呢?很顯然是可以的。那我們把getHasNoOrders()方法和getHasNoStock()方法分別放到兩個不同的線程中,優化下系統的性能,整體流程如下所示。
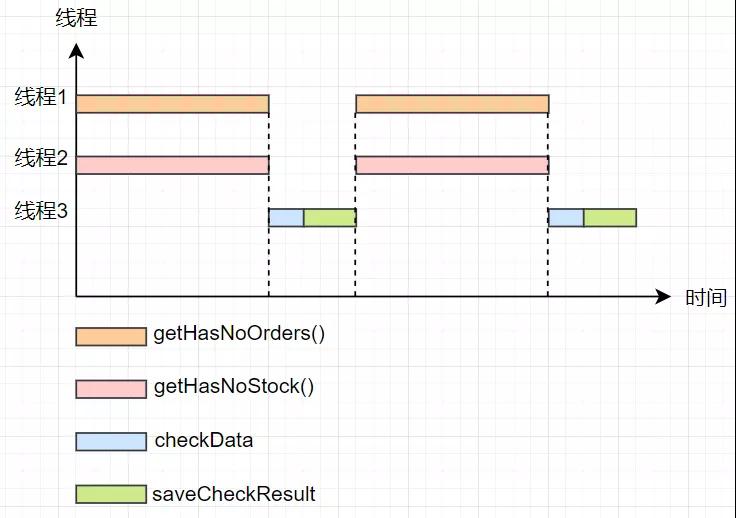
優化后,我們將getHasNoOrders()方法放到線程1中執行,getHasNoStock()方法放到線程2中執行,checkData()方法和saveCheckResult()方法發放到線程3中執行,優化后的系統性能相比優化前的系統性能幾乎提升了一倍,優化效果相對來說還是比較明顯的。
說到這里,大家應該應該知道具體怎么優化了吧?好,我們繼續往下看!
解決方案
解決問題的思路有了,接下來,我們看看如何使用代碼實現我們上面分析的解決問題的思路。這里,我們可以分別開啟兩個線程執行getHasNoOrders()方法和getHasNoStock()方法,在主線程中執行checkData()方法和saveCheckResult()方法。這里需要注意的是:主線程需要等待兩個子線程執行完畢之后再執行checkData()方法和saveCheckResult()方法。 為了實現這個功能,我們可以使用Thread類中join()方法,有關Thread類中join()方法的具體說明,這里,具體的邏輯就是在主線程中調用兩個子線程的join()方法實現阻塞等待,當兩個子線程執行完畢退出時,調用兩個子線程join()方法的主線程會被喚醒,從而執行主線程中的checkData()方法和saveCheckResult()方法。大體代碼如下所示。
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- while(checkOrders != null){
- Thread t1 = new Thread(()->{
- //查詢未校對的訂單信息
- hasNoOrders = getHasNoOrders();
- });
- t1.start();
- Thread t2 = new Thread(()->{
- //查詢未校對的庫存記錄
- hasNoStock = getHasNoStock();
- });
- t2.start();
- //阻塞主線程,等待線程t1和線程t2執行完畢
- t1.join();
- t2.join();
- //校對數據并返回結果
- checkResult = checkData(hasNoOrders, hasNoStock);
- //將結果信息保存到數據校對信息表中
- saveCheckResult(checkResult);
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- }
至此,我們基本上能夠解決問題了。但是,還有沒有進一步優化的空間呢?我們進一步往下看。
進一步優化
通過上面對系統優化,基本能夠達成我們的優化目標,但是上面的解決方案存在著不足的地方,那就是在while循環里每次都要新建兩個線程分別執行getHasNoOrders()方法和getHasNoStock()方法,了解Java多線程的小伙伴們應該都知道,在Java中創建線程可是個非常耗時的操作。所以,最好是能夠將創建出來的線程反復使用。這里,估計很多小伙伴都會想到使用線程池,沒錯,我們可以使用線程池進一步優化上面的代碼。
遇到新的問題
不過在使用線程池進一步優化時,我們會遇到一個問題,就是主線程如何等待子線程中的結果數據呢?說直白點就是:主線程如何知道子線程中的getHasNoOrders()方法和getHasNoStock()方法執行完了? 由于在之前的代碼中我們是在主線程中調用子線程的join()方法等待子線程執行完畢,獲取到子線程執行的結果后,繼續執行主線程的邏輯。但是如果使用了線程池的話,線程池中的線程根本不會退出,此時,我們無法使用線程的join()方法等待線程執行完畢。
所以,主線程如何知道子線程中的getHasNoOrders()方法和getHasNoStock()方法執行完了? 這個問題就成了關鍵的突破點。這里,我們使用線程池進一步優化的代碼如下所示。
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- //創建線程池
- Executor executor = Executors.newFixedThreadPool(2);
- while(checkOrders != null){
- executor.execute(()->{
- //查詢未校對的訂單信息
- hasNoOrders = getHasNoOrders();
- });
- executor.execute(()->{
- //查詢未校對的庫存記錄
- hasNoStock = getHasNoStock();
- });
- /**如何知道子線程中的getHasNoOrders()方法和getHasNoStock()方法執行完了成為關鍵**/
- //校對數據并返回結果
- checkResult = checkData(hasNoOrders, hasNoStock);
- //將結果信息保存到數據校對信息表中
- saveCheckResult(checkResult);
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- }
那么,如何解決這個問題呢?我們繼續往下看。
新的解決方案
相信細心的小伙伴們能夠看出,整個業務的場景就是:一個線程需要等待其他兩個線程的邏輯執行完畢后再執行。在Java的并發類庫中,為我們提供了一個能夠在這種場景下使用的類庫,那就是CountDownLatch類。
使用CountDownLatch類優化我們程序的具體做法就是:在程序的while()循環中首先創建一個CountDownLatch對象,計數器的值初始化為2。分別在hasNoOrders = getHasNoOrders();代碼和hasNoStock = getHasNoStock();代碼的后面調用latch.countDown()方法使得計數器的值分別減1。在主線程中調用latch.await()方法,等待計數器的值變為0,繼續往下執行。這樣,就能夠完美解決我們遇到的問題了。優化后的代碼如下所示。
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- //創建線程池
- Executor executor = Executors.newFixedThreadPool(2);
- while(checkOrders != null){
- CountDownLatch latch = new CountDownLatch(2);
- executor.execute(()->{
- //查詢未校對的訂單信息
- hasNoOrders = getHasNoOrders();
- latch.countDown();
- });
- executor.execute(()->{
- //查詢未校對的庫存記錄
- hasNoStock = getHasNoStock();
- latch.countDown();
- });
- //等待子線程的邏輯執行完畢
- latch.await();
- //校對數據并返回結果
- checkResult = checkData(hasNoOrders, hasNoStock);
- //將結果信息保存到數據校對信息表中
- saveCheckResult(checkResult);
- //檢測是否存在未對賬訂單
- checkOrders = checkOrders();
- }
至此,我們就完成了系統的優化工作。
總結與思考
這次系統性能的優化,主要是將單線程執行的數據校對業務,優化成使用多線程執行。在平時的工作過程中,我們需要認真思考,找到系統性能瓶頸所在,找出在邏輯上不相干,并且沒有先后順序的業務邏輯,將其放到不同的線程中執行,能夠大大提供系統的性能。
這次,對于系統的優化,我們最終使用線程池來執行比較耗時的查詢訂單與查詢庫存記錄的操作,并且在主線程中等待線程池中的線程邏輯執行完畢后再執行主線程的后續業務邏輯。這種場景,使用Java中提供的CountDownLatch類再合適不過了。這里,再強調一下:CountDownLatch主要的使用場景就是一個線程等待多個線程執行完畢后再執行。如下圖所示。
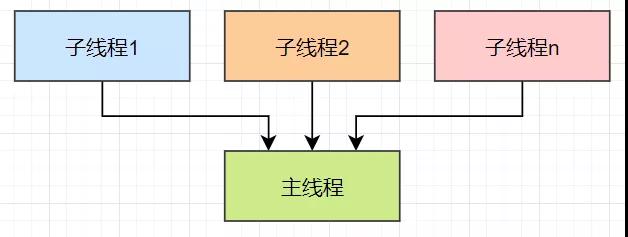
這里,也進一步提醒了我們:如果想學好并發編程,熟練的掌握Java中提供的并發類庫是我們必須要做到的。
本文轉載自微信公眾號「冰河技術」,可以通過以下二維碼關注。轉載本文請聯系冰河技術公眾號。