關于深度學習編譯器,這些知識你需要了解一下
最近的十幾年深度學習發展十分迅速,業界出現了很多深度學習算法開發框架。同時,由于深度學習具有廣泛應用場景和對算力的巨大需求,我們需要將深度學習算法運行在各種通用和專用的硬件上,比如各種類型的CPU,GPU,TPU,NPU等。那么這就出現了框架和硬件之間的組合爆炸,如圖 1所示。比如說TensorFlow要支持GPU計算,就要把tensorflow里面的所有算子開發一個GPU版本,如果又要支持D芯片,又需要把每個算子開發一個D芯片的版本。這個過程無疑非常耗時耗力。

圖 1
于此同時,我們現在有非常多的算法網絡,比如說YOLO, BERT, GPT等等。而這些算法網絡是是由不同類型、不同shape,不同連接關系的算子組成的。最終它們又運行在不同種類和型號的硬件上面。這就導致人工去為每個場景開發和實現最優算子成本很高。這里舉了兩個例子,如圖 2所示,算子融合是一個常見的性能優化方法,在融合之前,每個算子計算前后都需要把數據從內存讀到緩存,再從緩存寫回到內存。而融合之后,可以避免算子之間內存讀寫從而提高性能。傳統的做法就是人工去根據算子連接關系開發融合算子,但是不同網絡不同類別算子連接關系幾乎不可能完全枚舉。另一個例子就是算子調優,算子實現過程有很多參數會影響性能,但是傳統人工算子開發方式很難去表達和維護這些參數,并且對這些參數進行調優從而實現不同shape和硬件的最優性能。
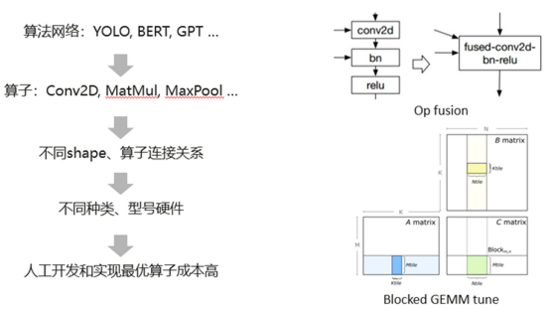
圖 2
深度學習編譯器正是為了解決上面一系列問題而誕生的,它可以作為框架和硬件之間的公共組件和橋梁,最終希望實現的目標是我們只用開發一次,就能夠為自動為任何設備生成最優代碼。比如為CPU開發的算子可以幾乎原封不同的用于GPU和D芯片,從而顯著降低成本。
這里簡單介紹一下深度學習編譯器的組成部分和功能,如圖 3所示。首先它的前端是從不同的框架拿到計算圖,并且使用這個High level IR的數據結構來表示,然后在這個階段進行一系列圖優化,比如常量折疊,算子融合,等價替換等。這里展示了一個等價替換的例子,原來計算圖是這樣的,我們給它換一個計算方式,結果不變,但是性能可能更優。接著,對于計算圖里面的每一個算子,采用DSL一種領域特定的語言來描述算子的計算過程和對算子進行優化。比如對算子進行tiling,多核,double-buffer等優化。由于算子的計算過程通常是用多重循環來實現的,比如說矩陣乘法是一個三重的循環。深度學習編譯器可以很方便的對循環進行各種變換,并且對這些變換的參數進行調優,從而得到不同shape和硬件的最佳算子實現。最后,基于low level IR為不同硬件生成具體的代碼。
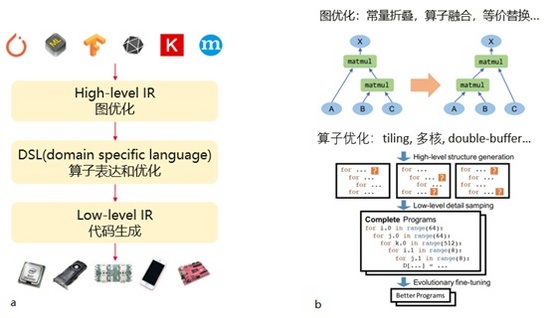
圖 3
最后介紹下業界已有的編譯器項目。目前生態最完善,開源的,框架不依賴的項目首推TVM,已經被很多公司所采用。TVM流程如如圖 3a所示,TVM可以導入各個框架的模型,例如TensorFlow pb,onnx,TorchScript等模型,統一用TVM稱為Relay的High level IR進行表示。IR中每個算子采用了Tensor expression的DSL來進行計算描述和調度。這個DSL采用Einstein’s notation的方式進行算子的compute描述,算子compute一般體現為多重for循環。然后基于Halide思想使用schedule對這個多重for循環進行各種變換,例如循環合并,split,順序變換等等。最后,lower到low-level IR生成具體的device代碼并進行推理。
這里再簡單介紹下TVM具體如何生成最優的算子代碼。上面介紹了算子需要進行compute描述,然后需要對compute對應的多重for循環進行調度變換,即schedule。TVM的算子生成和調優經歷了3代發展。第一代TVM/AutoTVM,這一代需要用戶編寫算子的compute和算子的schedule,AutoTVM與TVM的區別在于可以在schedule定義一些可變的參數,然后采用例如遺傳算法進行參數調優。例如把一個loop切分為2段,那么在哪里進行切分是可以進行優化的。第二代AutoScheduler (Ansor),這一代只需要用戶開發算子ompute,Ansor內部自動根據一些規則進行調度變換。由于調度開發需要同時熟悉TVM的表達機制和底層硬件原理,schedule開發往往具有很高的難度,因此Ansor可以顯著降低開發人員工作量和開發難度,缺點就是Ansor調優時間很長,往往需要1小時才能調優1個算子。以卷積網絡為例,Ansor在部分場景能超過TensorFlow算子性能,距離TensorRT實現有一定差距。第三代Meta Schedule (AutoTensorIR)才處于起步階段,預期會對調優速度和性能進行優化,暫時還不可用,我們拭目以待。
TVM的落地包括華為D芯片TBE算子開發工具,在TVM的基礎上增加了D芯片的代碼生成支持。TVM采用了Halide計算+調度的路線,還有另外一種采用polyhedral算法路線的編譯器,比如Tensor Comprehensions,Tiramisu,華為自研的AKG等。這種方法跟Ansor一樣,也只需要用戶開發算子compute,無需開發schedule,因此對用戶也較為友好。其中AKG已經用在了MindSpore的圖算融合里面。其他的深度學習編譯器還有TensorFlow的XLA、TensorRT等,大家可能已經用過。
總之,深度學習編譯器具有很多優勢。比如易于支持新硬件,避免重復開發,采用一系列自動優化代替人工優化,可以實現極致性價比等。目前深度學習編譯器也有一些不足,仍然出于一個快速發展的狀態。例如調優時間長,對于復雜的算子無法有效生成,一個模型中深度學習編譯器生成的算子能超過庫調用的算子比例較低等,仍然需要大家持續投入和優化。