Flink 和 Iceberg 如何解決數(shù)據(jù)入湖面臨的挑戰(zhàn)
一、數(shù)據(jù)入湖的核心挑戰(zhàn)
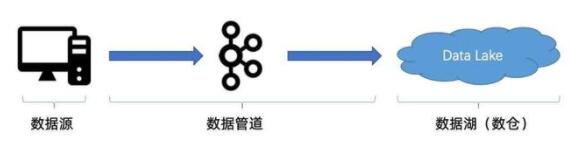
數(shù)據(jù)實(shí)時入湖可以分成三個部分,分別是數(shù)據(jù)源、數(shù)據(jù)管道和數(shù)據(jù)湖(數(shù)倉),本文的內(nèi)容將圍繞這三部分展開。
1. Case #1:程序 BUG 導(dǎo)致數(shù)據(jù)傳輸中斷

首先,當(dāng)數(shù)據(jù)源通過數(shù)據(jù)管道傳到數(shù)據(jù)湖(數(shù)倉)時,很有可能會遇到作業(yè)有 BUG 的情況,導(dǎo)致數(shù)據(jù)傳到一半,對業(yè)務(wù)造成影響;
第二個問題是當(dāng)遇到這種情況的時候,如何重啟作業(yè),并保證數(shù)據(jù)不重復(fù)也不缺失,完整地同步到數(shù)據(jù)湖(數(shù)倉)中。
2. Case #2:數(shù)據(jù)變更太痛苦
數(shù)據(jù)變更當(dāng)發(fā)生數(shù)據(jù)變更的情況時,會給整條鏈路帶來較大的壓力和挑戰(zhàn)。以下圖為例,原先是一個表定義了兩個字段,分別是 ID 和 NAME。此時,業(yè)務(wù)方面的同學(xué)表示需要將地址加上,以方便更好地挖掘用戶的價值。首先,我們需要把 Source 表加上一個列 Address,然后再把到 Kafka 中間的鏈路加上鏈,然后修改作業(yè)并重啟。接著整條鏈路得一路改過去,添加新列,修改作業(yè)并重啟,最后把數(shù)據(jù)湖(數(shù)倉)里的所有數(shù)據(jù)全部更新,從而實(shí)現(xiàn)新增列。這個過程的操作不僅耗時,而且會引入一個問題,就是如何保證數(shù)據(jù)的隔離性,在變更的過程中不會對分析作業(yè)的讀取造成影響。
分區(qū)變更如下圖所示,數(shù)倉里面的表是以 “月” 為單位進(jìn)行分區(qū),現(xiàn)在希望改成以 “天” 為單位做分區(qū),這可能就需要將很多系統(tǒng)的數(shù)據(jù)全部更新一遍,然后再用新的策略進(jìn)行分區(qū),這個過程十分耗時。
3. Case #3:越來越慢的近實(shí)時報表?
當(dāng)業(yè)務(wù)需要更加近實(shí)時的報表時,需要將數(shù)據(jù)的導(dǎo)入周期,從 “天” 改到 “小時”,甚至 “分鐘” 級別,這可能會帶來一系列問題。
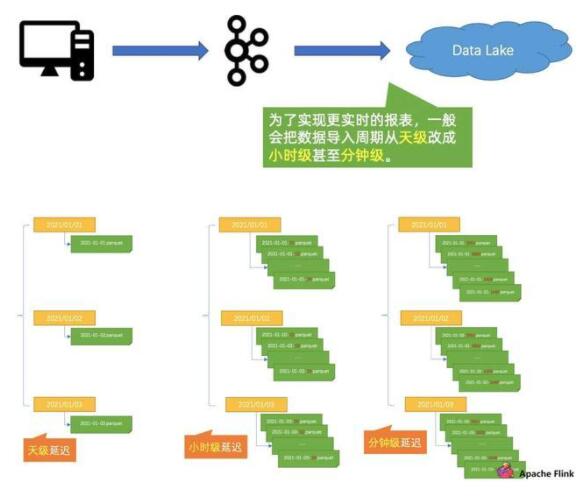
如上圖所示,首先帶來的第一個問題是:文件數(shù)以肉眼可見的速度增長,這將對外面的系統(tǒng)造成越來越大的壓力。壓力主要體現(xiàn)在兩個方面:
第一個壓力是,啟動分析作業(yè)越來越慢,Hive Metastore 面臨擴(kuò)展難題,如下圖所示。隨著小文件越來越多,使用中心化的 Metastore 的瓶頸會越來越嚴(yán)重,這會造成啟動分析作業(yè)越來越慢,因為啟動作業(yè)的時候,會把所有的小文件原數(shù)據(jù)都掃一遍。第二是因為 Metastore 是中心化的系統(tǒng),很容易碰到 Metastore 擴(kuò)展難題。例如 Hive,可能就要想辦法擴(kuò)后面的 MySQL,造成較大的維護(hù)成本和開銷。
第二個壓力是掃描分析作業(yè)越來越慢。隨著小文件增加,在分析作業(yè)起來之后,會發(fā)現(xiàn)掃描的過程越來越慢。本質(zhì)是因為小文件大量增加,導(dǎo)致掃描作業(yè)在很多個 Datanode 之間頻繁切換。
4. Case #4:實(shí)時地分析 CDC 數(shù)據(jù)很困難
大家調(diào)研 Hadoop 里各種各樣的系統(tǒng),發(fā)現(xiàn)整個鏈路需要跑得又快又好又穩(wěn)定,并且有好的并發(fā),這并不容易。
首先從源端來看,比如要將 MySQL 的數(shù)據(jù)同步到數(shù)據(jù)湖進(jìn)行分析,可能會面臨一個問題,就是 MySQL 里面有存量數(shù)據(jù),后面如果不斷產(chǎn)生增量數(shù)據(jù),如何完美地同步全量和增量數(shù)據(jù)到數(shù)據(jù)湖中,保證數(shù)據(jù)不多也不少。
此外,假設(shè)解決了源頭的全量跟增量切換,如果在同步過程中遇到異常,如上游的 Schema 變更導(dǎo)致作業(yè)中斷,如何保證 CDC 數(shù)據(jù)一行不少地同步到下游。
整條鏈路的搭建,需要涉及源頭全量跟同步的切換,包括中間數(shù)據(jù)流的串通,還有寫入到數(shù)據(jù)湖(數(shù)倉)的流程,搭建整個鏈路需要寫很多代碼,開發(fā)門檻較高。
最后一個問題,也是關(guān)鍵的一個問題,就是我們發(fā)現(xiàn)在開源的生態(tài)和系統(tǒng)中,很難找到高效、高并發(fā)分析 CDC 這種變更性質(zhì)的數(shù)據(jù)。
5. 數(shù)據(jù)入湖面臨的核心挑戰(zhàn)
數(shù)據(jù)同步任務(wù)中斷無法有效隔離寫入對分析的影響;同步任務(wù)不保證 exactly-once 語義。
端到端數(shù)據(jù)變更DDL 導(dǎo)致全鏈路更新升級復(fù)雜;修改湖/倉中存量數(shù)據(jù)困難。
越來越慢的近實(shí)時報表頻繁寫入產(chǎn)生大量小文件;Metadata 系統(tǒng)壓力大, 啟動作業(yè)慢;大量小文件導(dǎo)致數(shù)據(jù)掃描慢。
無法近實(shí)時分析 CDC 數(shù)據(jù)難以完成全量到增量同步的切換;涉及端到端的代碼開發(fā),門檻高;開源界缺乏高效的存儲系統(tǒng)。
二、Apache Iceberg 介紹
1. Netflix:Hive 上云痛點(diǎn)總結(jié)
Netflix 做 Iceberg 最關(guān)鍵的原因是想解決 Hive 上云的痛點(diǎn),痛點(diǎn)主要分為以下三個方面:
1.1 痛點(diǎn)一:數(shù)據(jù)變更和回溯困難
不提供 ACID 語義。在發(fā)生數(shù)據(jù)改動時,很難隔離對分析任務(wù)的影響。典型操作如:INSERT OVERWRITE;修改數(shù)據(jù)分區(qū);修改 Schema;
無法處理多個數(shù)據(jù)改動,造成沖突問題;
無法有效回溯歷史版本。
1.2 痛點(diǎn)二:替換 HDFS 為 S3 困難
數(shù)據(jù)訪問接口直接依賴 HDFS API;
依賴 RENAME 接口的原子性,這在類似 S3 這樣的對象存儲上很難實(shí)現(xiàn)同樣的語義;
大量依賴文件目錄的 list 接口,這在對象存儲系統(tǒng)上很低效。
1.3 痛點(diǎn)三:太多細(xì)節(jié)問題
Schema 變更時,不同文件格式行為不一致。不同 FileFormat 甚至連數(shù)據(jù)類型的支持都不一致;
Metastore 僅維護(hù) partition 級別的統(tǒng)計信息,造成不 task plan 開銷; Hive Metastore 難以擴(kuò)展;
非 partition 字段不能做 partition prune。
2. Apache Iceberg 核心特性
通用化標(biāo)準(zhǔn)設(shè)計完美解耦計算引擎Schema 標(biāo)準(zhǔn)化開放的數(shù)據(jù)格式支持 Java 和 Python
完善的 Table 語義Schema 定義與變更靈活的 Partition 策略ACID 語義Snapshot 語義
豐富的數(shù)據(jù)管理存儲的流批統(tǒng)一可擴(kuò)展的 META 設(shè)計支持批更新和 CDC支持文件加密
性價比計算下推設(shè)計低成本的元數(shù)據(jù)管理向量化計算輕量級索引
3. Apache Iceberg File Layout
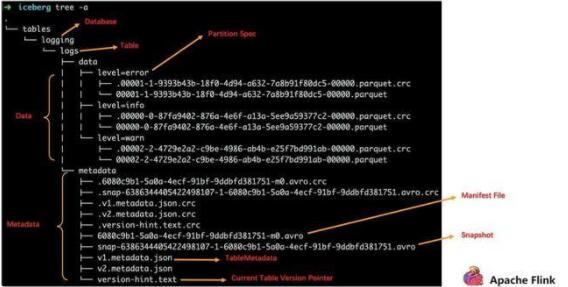
上方為一個標(biāo)準(zhǔn)的 Iceberg 的 TableFormat 結(jié)構(gòu),核心分為兩部分,一部分是 Data,一部分是 Metadata,無論哪部分都是維護(hù)在 S3 或者是 HDFS 之上的。
4. Apache Iceberg Snapshot View
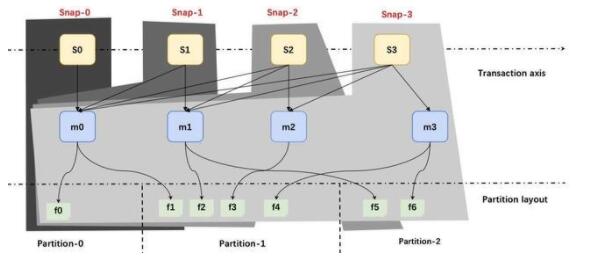
上圖為 Iceberg 的寫入跟讀取的大致流程。
可以看到這里面分三層:
最上面黃色的是快照;
中間藍(lán)色的是 Manifest;
最下面是文件。
每次寫入都會產(chǎn)生一批文件,一個或多個 Manifest,還有快照。
比如第一次形成了快照 Snap-0,第二次形成快照 Snap-1,以此類推。但是在維護(hù)原數(shù)據(jù)的時候,都是增量一步一步做追加維護(hù)的。
這樣的話可以幫助用戶在一個統(tǒng)一的存儲上做批量的數(shù)據(jù)分析,也可以基于存儲之上去做快照之間的增量分析,這也是 Iceberg 在流跟批的讀寫上能夠做到一些支持的原因。
5. 選擇 Apache Iceberg 的公司

上圖為目前在使用 Apache Iceberg 的部分公司,國內(nèi)的例子大家都較為熟悉,這里大致介紹一下國外公司的使用情況。
NetFlix 現(xiàn)在是有數(shù)百PB的數(shù)據(jù)規(guī)模放到 Apache Iceberg 之上,F(xiàn)link 每天的數(shù)據(jù)增量是上百T的數(shù)據(jù)規(guī)模。
Adobe 每天的數(shù)據(jù)新增量規(guī)模為數(shù)T,數(shù)據(jù)總規(guī)模在幾十PB左右。
AWS 把 Iceberg 作為數(shù)據(jù)湖的底座。
Cloudera 基于 Iceberg 構(gòu)建自己整個公有云平臺,像 Hadoop 這種 HDFS 私有化部署的趨勢在減弱,上云的趨勢逐步上升,Iceberg 在 Cloudera 數(shù)據(jù)架構(gòu)上云的階段中起到關(guān)鍵作用。
蘋果有兩個團(tuán)隊在使用:一是整個 iCloud 數(shù)據(jù)平臺基于 Iceberg 構(gòu)建;二是人工智能語音服務(wù) Siri,也是基于 Flink 跟 Iceberg 來構(gòu)建整個數(shù)據(jù)庫的生態(tài)。
三、Flink 和 Iceberg 如何解決問題
回到最關(guān)鍵的內(nèi)容,下面闡述 Flink 和 Iceberg 如何解決第一部分所遇到的一系列問題。
1. Case #1:程序 BUG 導(dǎo)致數(shù)據(jù)傳輸中斷
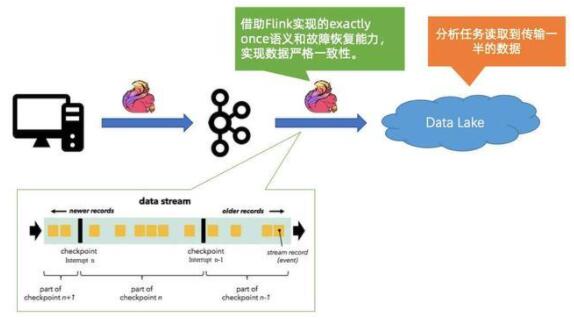
首先,同步鏈路用 Flink,可以保證 exactly once 的語義,當(dāng)作業(yè)出現(xiàn)故障時,能夠做嚴(yán)格的恢復(fù),保證數(shù)據(jù)的一致性。
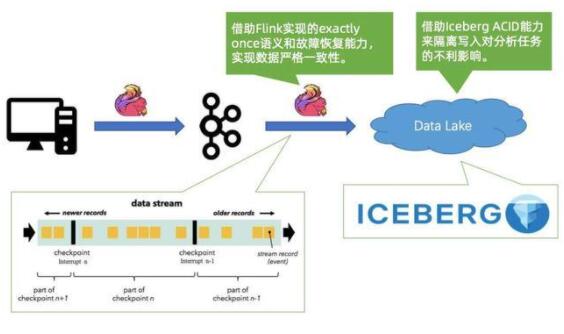
第二個是 Iceberg,它提供嚴(yán)謹(jǐn)?shù)?ACID 語義,可以幫用戶輕松隔離寫入對分析任務(wù)的不利影響。
2. Case #2:數(shù)據(jù)變更太痛苦
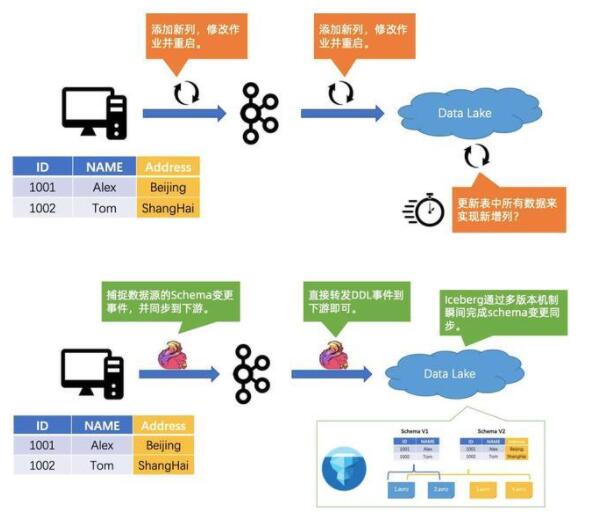
如上所示,當(dāng)發(fā)生數(shù)據(jù)變更時,用 Flink 和 Iceberg 可以解決這個問題。
Flink 可以捕捉到上游 Schema 變更的事件,然后把這個事件同步到下游,同步之后下游的 Flink 直接把數(shù)據(jù)往下轉(zhuǎn)發(fā),轉(zhuǎn)發(fā)之后到存儲,Iceberg 可以瞬間把 Schema 給變更掉。
當(dāng)做 Schema 這種 DDL 的時候,Iceberg 直接維護(hù)了多個版本的 Schema,然后老的數(shù)據(jù)源完全不動,新的數(shù)據(jù)寫新的 Schema,實(shí)現(xiàn)一鍵 Schema 隔離。
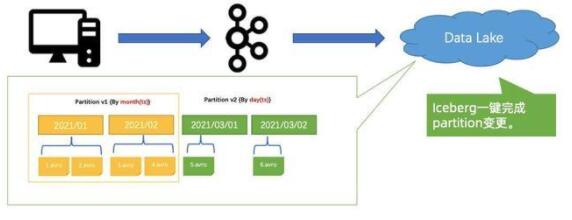
另外一個例子是分區(qū)變更的問題,Iceberg 做法如上圖所示。
之前按 “月” 做分區(qū)(上方黃色數(shù)據(jù)塊),如果希望改成按 “天” 做分區(qū),可以直接一鍵把 Partition 變更,原來的數(shù)據(jù)不變,新的數(shù)據(jù)全部按 “天” 進(jìn)行分區(qū),語義做到 ACID 隔離。
3. Case #3:越來越慢的近實(shí)時報表?
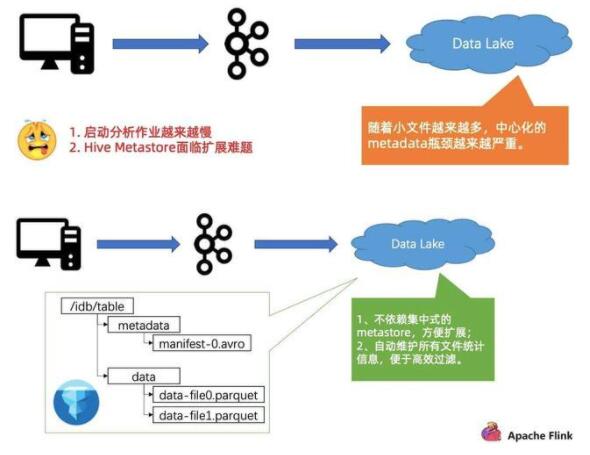
第三個問題是小文件對 Metastore 造成的壓力。
首先對于 Metastore 而言,Iceberg 是把原數(shù)據(jù)統(tǒng)一存到文件系統(tǒng)里,然后用 metadata 的方式維護(hù)。整個過程其實(shí)是去掉了中心化的 Metastore,只依賴文件系統(tǒng)擴(kuò)展,所以擴(kuò)展性較好。
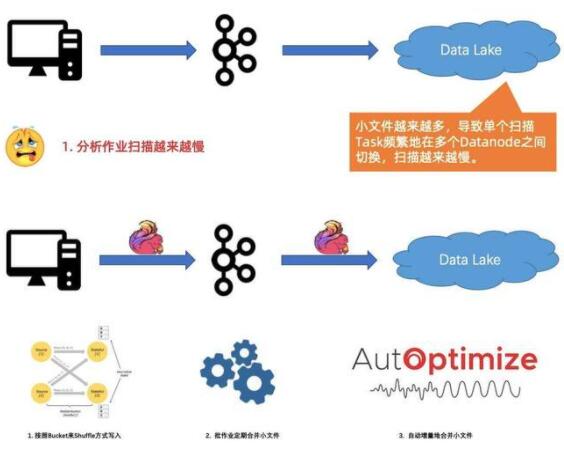
另一個問題是小文件越來越多,導(dǎo)致數(shù)據(jù)掃描會越來越慢。在這個問題上,F(xiàn)link 和 Iceberg 提供了一系列解決方案:
第一個方案是在寫入的時候優(yōu)化小文件的問題,按照 Bucket 來 Shuffle 方式寫入,因為 Shuffle 這個小文件,寫入的文件就自然而然的小。
第二個方案是批作業(yè)定期合并小文件。
第三個方案相對智能,就是自動增量地合并小文件。
4. Case #4:實(shí)時地分析CDC數(shù)據(jù)很困難
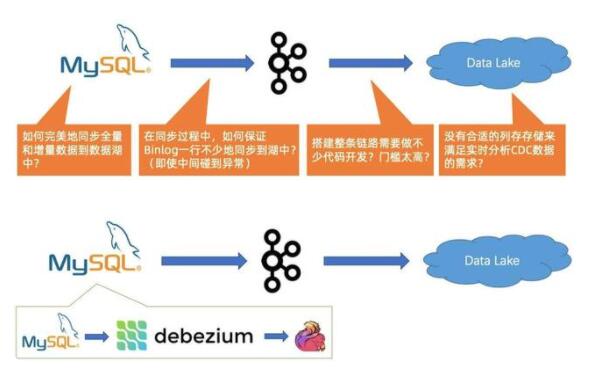
首先是是全量跟增量數(shù)據(jù)同步的問題,社區(qū)其實(shí)已有 Flink CDC Connected 方案,就是說 Connected 能夠自動做全量跟增量的無縫銜接。
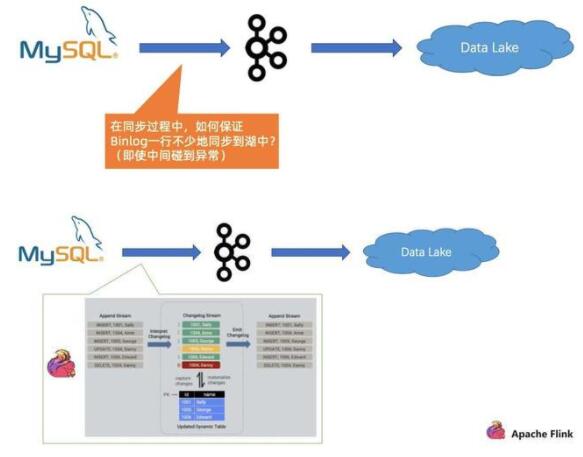
第二個問題是在同步過程中,如何保證 Binlog 一行不少地同步到湖中, 即使中間碰到異常。
對于這個問題,F(xiàn)link 在 Engine 層面能夠很好地識別不同類型的事件,然后借助 Flink 的 exactly once 的語義,即使碰到故障,它也能自動做恢復(fù)跟處理。
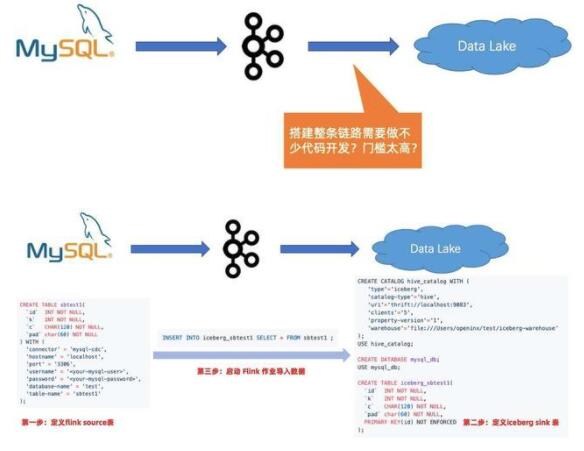
第三個問題是搭建整條鏈路需要做不少代碼開發(fā),門檻太高。
在用了 Flink 和 Data Lake 方案后,只需要寫一個 source 表和 sink 表,然后一條 INSERT INTO,整個鏈路就可以打通,無需寫任何業(yè)務(wù)代碼。
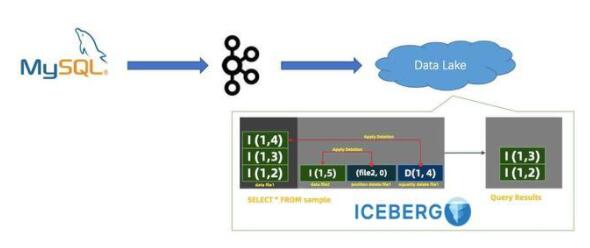
最后是存儲層面如何支持近實(shí)時的 CDC 數(shù)據(jù)分析。
四、社區(qū) Roadmap

上圖為 Iceberg 的 Roadmap,可以看到 Iceberg 在 2019 年只發(fā)了一個版本, 卻在 2020 年直接發(fā)了三個版本,并在 0.9.0 版本就成為頂級項目。

上圖為 Flink 與 Iceberg 的 Roadmap,可以分為 4 個階段。
第一個階段是 Flink 與 Iceberg 建立連接。
第二階段是 Iceberg 替換 Hive 場景。在這個場景下,有很多公司已經(jīng)開始上線,落地自己的場景。
第三個階段是通過 Flink 與 Iceberg 解決更復(fù)雜的技術(shù)問題。
第四個階段是把這一套從單純的技術(shù)方案,到面向更完善的產(chǎn)品方案角度去做。