













用定租問題學(xué)透K近鄰算法
k近鄰思想是我覺得最純粹最清晰的一個(gè)思想,k近鄰算法(KNN)只是這個(gè)思想在數(shù)據(jù)領(lǐng)域都一個(gè)應(yīng)用。
你的工資由你周圍的人決定。
你的水平由你身邊最接近的人的水平?jīng)Q定。
你所看到的世界,由你身邊的人決定。
思想歸思想,不能被編碼那也無法應(yīng)用于數(shù)據(jù)科學(xué)領(lǐng)域。
我們提出問題,然后應(yīng)用該方法加以解決,以此加深我們對方法的理解。
問題: 假設(shè)你是airbnb平臺的房東,怎么給自己的房子定租金呢?
分析: 租客根據(jù)airbnb平臺上的租房信息,主要包括價(jià)格、臥室數(shù)量、房屋類型、位置等等挑選自己滿意的房子。給房子定租金是跟市場動態(tài)息息相關(guān)的,同樣類型的房子我們收費(fèi)太高租客肯定不租,收費(fèi)太低收益又不好。
解答: 收集跟我們房子條件差不多的一些房子信息,確定跟我們房子最相近的幾個(gè),然后求其定價(jià)的平均值,以此作為我們房子的租金。
這就是K-Nearest Neighbors(KNN),k近鄰算法。KNN的核心思想是未標(biāo)記樣本的類別,由距離其最近的k個(gè)鄰居投票決定。
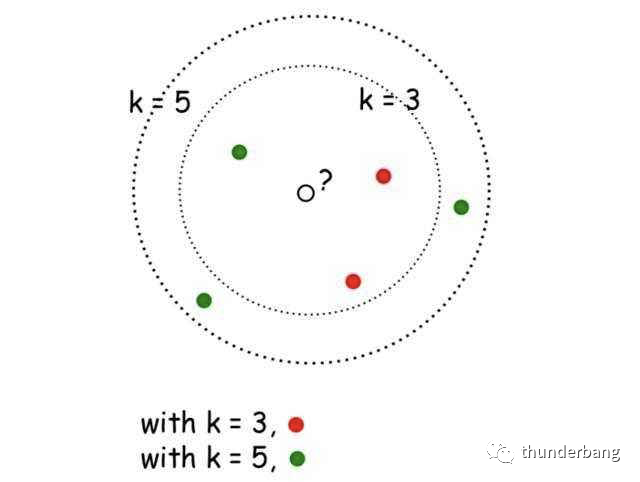
本文就基于房租定價(jià)問題梳理下該算法應(yīng)用的全流程,包含如下部分。
- 讀入數(shù)據(jù)
- 數(shù)據(jù)處理
- 手寫算法代碼預(yù)測
- 利用sklearn作模型預(yù)測
- 超參優(yōu)化
- 交叉驗(yàn)證
- 總結(jié)
提前聲明,本數(shù)據(jù)集是公開的,你可以在網(wǎng)上找到很多相關(guān)主題的材料,本文力圖解釋地完整且精準(zhǔn),如果你找到了更詳實(shí)的學(xué)習(xí)材料,那再好不過了。
1.讀入數(shù)據(jù)
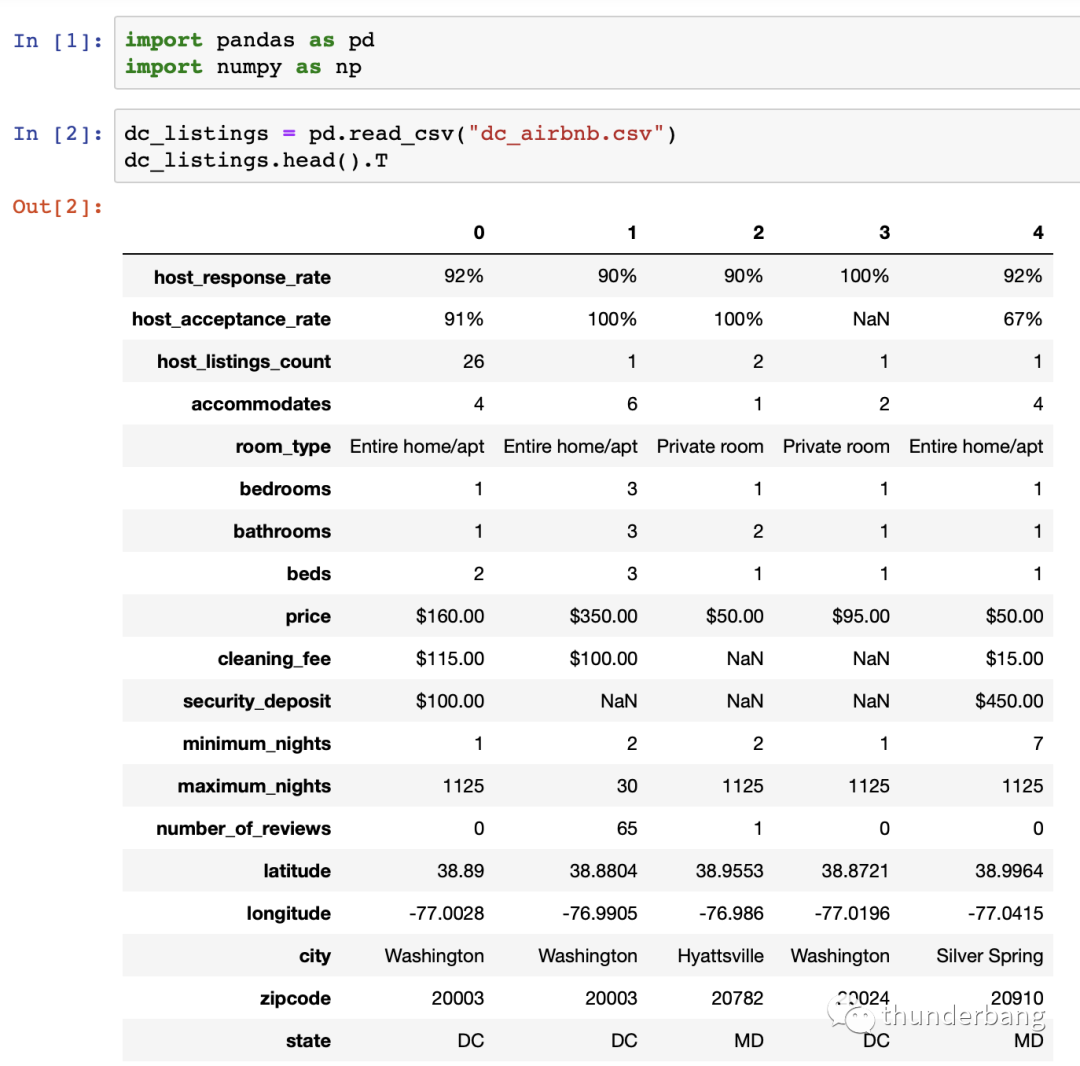
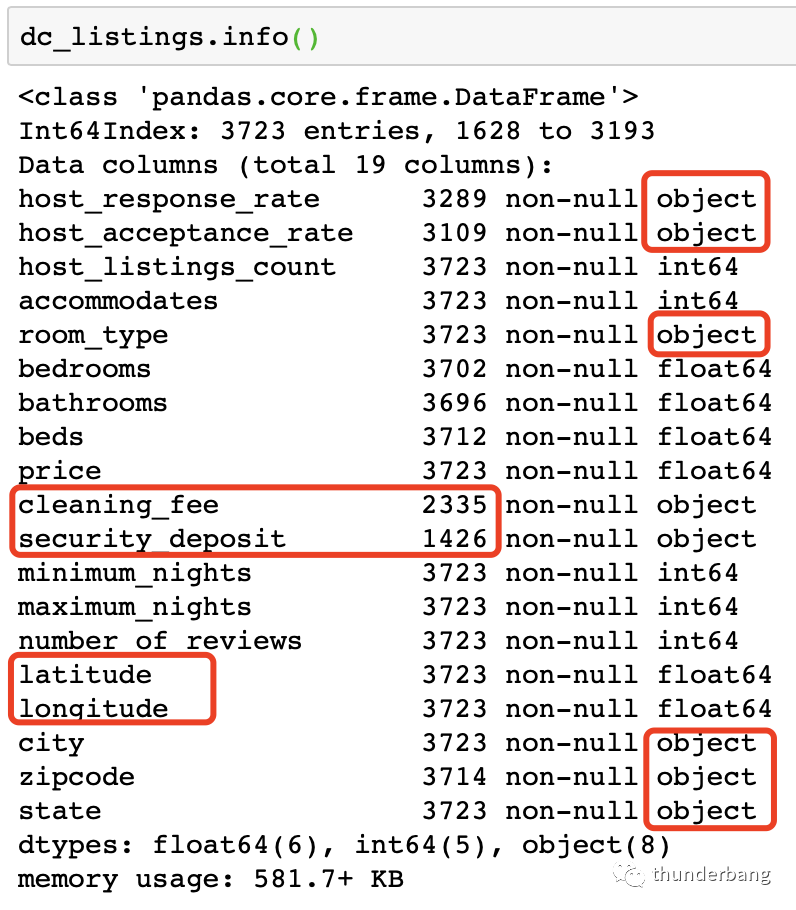
先讀入數(shù)據(jù),了解下數(shù)據(jù)情況,發(fā)現(xiàn)目標(biāo)變量price,以及cleaning_fee和security_deposit的格式有點(diǎn)問題,另有一些變量是字符型,都需要處理。我對dataframe進(jìn)行了轉(zhuǎn)置顯示,方便查看。
2.數(shù)據(jù)處理
我們先只處理price,盡量集中在算法思想本身上面去。
- # 處理下目標(biāo)變量price,并轉(zhuǎn)換成數(shù)值型
- stripped_commas = dc_listings['price'].str.replace(',', '')
- stripped_dollars = stripped_commas.str.replace('$', '')
- dc_listings['price'] = stripped_dollars.astype('float')
- # k近鄰算法也是模型,需要劃分訓(xùn)練集和測試集
- sample_num = len(dc_listings)
- # 在這我們先把數(shù)據(jù)隨機(jī)打散,保證數(shù)據(jù)集的切分隨機(jī)有效
- dc_listings = dc_listings.loc[np.random.permutation(len(sample_num))]
- train_df = dc_listings.iloc[0:int(0.7*sample_num)]
- test_df = dc_listings.iloc[int(0.7*sample_num):]
3.手寫算法代碼預(yù)測
根據(jù)k近鄰算法的定義直接編寫代碼,從簡單高效上考慮,我們僅針對單變量作預(yù)測。
入住人數(shù)應(yīng)該是和租金關(guān)聯(lián)度很高的信息,面積應(yīng)該也是。我們這里采用前者。
我們的目標(biāo)是理解算法邏輯。實(shí)際操作中一般不會只考慮單一變量。
- # 注意,這兒是train_df
- def predict_price(new_listing):
- temp_df = train_df.copy()
- temp_df['distance'] = temp_df['accommodates'].apply(lambda x: np.abs(x - new_listing))
- temp_df = temp_df.sort_values('distance')
- nearest_neighbor_prices = temp_df.iloc[0:5]['price']
- predicted_price = nearest_neighbor_prices.mean()
- return(predicted_price)
- # 這兒是test_df
- test_df['predicted_price'] = test_df['accommodates'].apply(predict_price)
- # MAE(mean absolute error), MSE(mean squared error), RMSE(root mean squared error)
- test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
- mse = test_df['squared_error'].mean()
- rmse = mse ** (1/2)
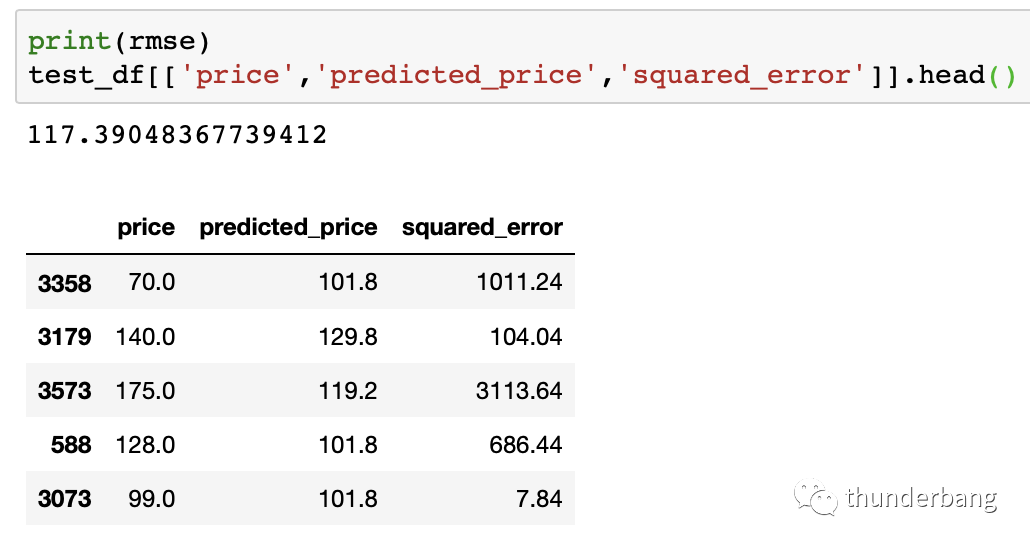
值得強(qiáng)調(diào)的是,模型算法的構(gòu)建都是基于訓(xùn)練集的,預(yù)測評估基于測試集。應(yīng)用評估嚴(yán)格上還有一類樣本,oot:跨時(shí)間樣本。
從結(jié)果來看,即使我們只用了入住人數(shù)accommodates這一個(gè)變量去做近鄰選擇,預(yù)測結(jié)果也是很有效的。
4.利用sklearn作模型預(yù)測
這次我們要用更多的變量,只剔掉字符串和不可解釋的變量,剩下能用的變量都用上。
當(dāng)用了多個(gè)變量的時(shí)候,這些不變量綱是不一樣的,我們需要進(jìn)行標(biāo)準(zhǔn)化處理。保證了各自變量的分布差異,同時(shí)又保證變量之間可疊加。
- # 剔掉非數(shù)值型變量和不合適的變量
- drop_columns = ['room_type', 'city', 'state', 'latitude', 'longitude', 'zipcode', 'host_response_rate', 'host_acceptance_rate', 'host_listings_count']
- dc_listings = dc_listings.drop(drop_columns, axis=1)
- # 剔掉缺失比例過高的列(變量)
- dc_listings = dc_listings.drop(['cleaning_fee', 'security_deposit'], axis=1)
- # 剔掉有缺失值的行(樣本)
- dc_listings = dc_listings.dropna(axis=0)
- # 多個(gè)變量的量綱不一樣,需要標(biāo)準(zhǔn)化
- normalized_listings = (dc_listings - dc_listings.mean())/(dc_listings.std())
- normalized_listings['price'] = dc_listings['price']
- # 于是我們得到了可用于建模的數(shù)據(jù)集,7:3劃分訓(xùn)練集測試集
- train_df = normalized_listings.iloc[0:int(0.7*len(normalized_listings))]
- test_df = normalized_listings.iloc[int(0.7*len(normalized_listings)):]
- # price是y,其余變量都是X
- features = train_df.columns.tolist()
- features.remove('price')
處理后的數(shù)據(jù)集如下,其中price是我們要預(yù)測的目標(biāo),其余是可用的變量。
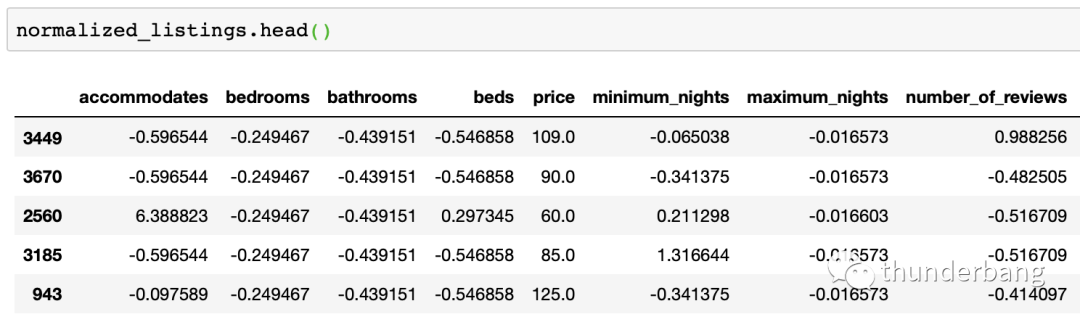
- from sklearn.neighbors import KNeighborsRegressor
- from sklearn.metrics import mean_squared_error
- knn = KNeighborsRegressor(n_neighbors=5, algorithm='brute')
- knn.fit(train_df[features], train_df['price'])
- predictions = knn.predict(test_df[features])
- mse = mean_squared_error(test_df['price'], predictions)
- rmse = mse ** (1/2)
最后得到的rmse=111.9,相比單變量knn的117.4要小,結(jié)果得到優(yōu)化。嚴(yán)格來說,這個(gè)對比不完全公平,因?yàn)槲覀儊G掉了少量的特征缺失樣本。
5.超參優(yōu)化
在第3和第4部分,我們預(yù)設(shè)了k=5,但這個(gè)拍腦袋確定的。該取值合不合理,是不是最優(yōu),都需要進(jìn)一步確定。
其中,這個(gè)k就是一個(gè)超參數(shù)。對于任何一個(gè)數(shù)據(jù)集,只要你用knn,就需要確定這個(gè)k值。
k值不是通過模型基于數(shù)據(jù)去學(xué)習(xí)得到的,而是通過預(yù)設(shè),然后根據(jù)結(jié)果反選確定的。任何一個(gè)超參數(shù)都是這樣確定的,其他算法也如此。
- import matplotlib.pyplot as plt
- %matplotlib inline
- hyper_params = [x for x in range(1,21)]
- rmse_values = []
- features = train_df.columns.tolist()
- features.remove('price')
- for hp in hyper_params:
- knn = KNeighborsRegressor(n_neighbors=hp, algorithm='brute')
- knn.fit(train_df[features], train_df['price'])
- predictions = knn.predict(test_df[features])
- mse = mean_squared_error(test_df['price'], predictions)
- rmse = mse**(1/2)
- rmse_values.append(rmse)
- plt.plot(hyper_params, rmse_values,c='r',linestyle='-',marker='+')
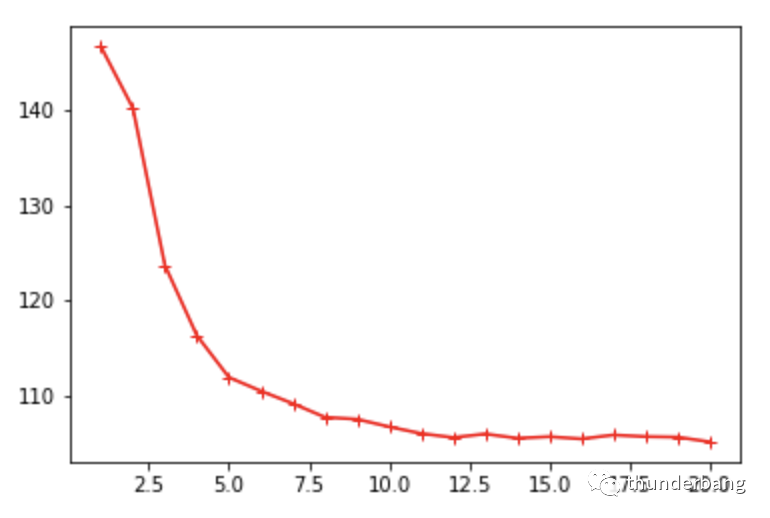
我們發(fā)現(xiàn),k越大,預(yù)測價(jià)格和真實(shí)價(jià)格的偏差從趨勢看會更準(zhǔn)確。但要注意,k越大計(jì)算量就越大。
我們在確定k值時(shí),可以用albow法,也就是看上圖的拐點(diǎn),形象上就是手肘的肘部。
相比k=5,k=7或10可能是更好的結(jié)果。
6.交叉驗(yàn)證
上面我們的計(jì)算結(jié)果完全依賴訓(xùn)練集和測試集,雖然對它們的劃分我們已經(jīng)考慮了隨機(jī)性。但一次結(jié)果仍然具備偶爾性,尤其是當(dāng)樣本量不夠大時(shí)。
交叉驗(yàn)證就是為了解決這個(gè)問題。我們可以對同一個(gè)樣本集進(jìn)行不同的訓(xùn)練集測試集劃分。每次劃分后都重新進(jìn)行訓(xùn)練和預(yù)測,然后綜合去看待這些結(jié)果。
應(yīng)用最廣泛的是n折交叉驗(yàn)證,其過程是隨機(jī)將數(shù)據(jù)集切分成n份,用其中n-1個(gè)子集做訓(xùn)練集,剩余1個(gè)子集做測試集。這樣一共可以進(jìn)行n次訓(xùn)練和預(yù)測。
我們可以直接手寫該邏輯,如下。
- sample_num = len(normalized_listings)
- normalized_listings.loc[normalized_listings.index[0:int(0.2*sample_num)], "fold"] = 1
- normalized_listings.loc[normalized_listings.index[int(0.2*sample_num):int(0.4*sample_num)], "fold"] = 2
- normalized_listings.loc[normalized_listings.index[int(0.4*sample_num):int(0.6*sample_num)], "fold"] = 3
- normalized_listings.loc[normalized_listings.index[int(0.6*sample_num):int(0.8*sample_num)], "fold"] = 4
- normalized_listings.loc[normalized_listings.index[int(0.8*sample_num):], "fold"] = 5
- fold_ids = [1,2,3,4,5]
- def train_and_validate(df, folds):
- fold_rmses = []
- for fold in folds:
- # Train
- model = KNeighborsRegressor()
- train = df[df["fold"] != fold]
- test = df[df["fold"] == fold].copy()
- model.fit(train[features], train["price"])
- # Predict
- labels = model.predict(test[features])
- test["predicted_price"] = labels
- mse = mean_squared_error(test["price"], test["predicted_price"])
- rmse = mse**(1/2)
- fold_rmses.append(rmse)
- return(fold_rmses)
- rmses = train_and_validate(normalized_listings, fold_ids)
- avg_rmse = np.mean(rmses)

工程上,我們要充分利用工具和資源。sklearn庫就包含了我們常用的機(jī)器學(xué)習(xí)算法實(shí)現(xiàn),可以直接用來驗(yàn)證。
- from sklearn.model_selection import cross_val_score, KFold
- kf = KFold(5, shuffle=True, random_state=1)
- model = KNeighborsRegressor()
- mses = cross_val_score(model, normalized_listings[features], normalized_listings["price"], scoring="neg_mean_squared_error", cv=kf)
- rmses = np.sqrt(np.absolute(mses))
- avg_rmse = np.mean(rmses)

交叉驗(yàn)證的結(jié)果置信度會更高,尤其是在小數(shù)據(jù)集上。因?yàn)樗軌蛞欢ǔ潭鹊販p輕偶然性誤差。
結(jié)合交叉驗(yàn)證和超參優(yōu)化,我們一般就得到了該數(shù)據(jù)集下用knn算法預(yù)測的最優(yōu)結(jié)果。
- # 超參優(yōu)化
- num_folds = [x for x in range(2,50,2)]
- rmse_values = []
- for fold in num_folds:
- kf = KFold(fold, shuffle=True, random_state=1)
- model = KNeighborsRegressor()
- mses = cross_val_score(model, normalized_listings[features], normalized_listings["price"], scoring="neg_mean_squared_error", cv=kf)
- rmses = np.sqrt(np.absolute(mses))
- avg_rmse = np.mean(rmses)
- std_rmse = np.std(rmses)
- rmse_values.append(avg_rmse)
- plt.plot(num_folds, rmse_values,c='r',linestyle='-',marker='+')
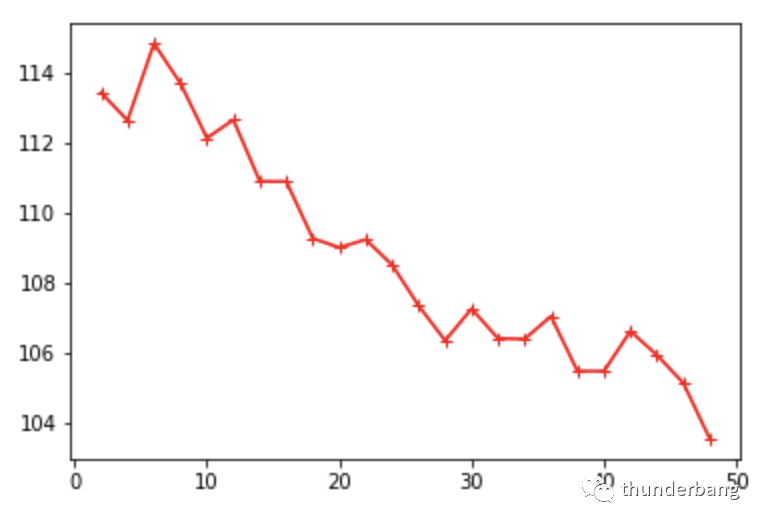
我們得到了相同的趨勢,k越大,效果趨勢上更好。同時(shí)因?yàn)榻徊骝?yàn)證一定程度上解決了過擬合問題,理想的k值越大,模型可以更復(fù)雜些。
7.總結(jié)
從k-近鄰算法的核心思想以及以上編碼過程可以看出,該算法是基于實(shí)例的學(xué)習(xí)方法,因?yàn)樗耆揽坑?xùn)練集里的實(shí)例。
該算法不需什么數(shù)學(xué)方法,很容易理解。但是非常不適合應(yīng)用在大數(shù)據(jù)集上,因?yàn)閗-近鄰算法每一次預(yù)測都需要計(jì)算整個(gè)訓(xùn)練集的數(shù)據(jù)到待預(yù)測數(shù)據(jù)的距離,然后增序排列,計(jì)算量巨大。
如果能用數(shù)學(xué)函數(shù)來描述數(shù)據(jù)集的特征變量與目標(biāo)變量的關(guān)系,那么一旦用訓(xùn)練集獲得了該函數(shù)表示,預(yù)測就是簡簡單單的數(shù)學(xué)計(jì)算問題了。計(jì)算復(fù)雜度大大降低。
其他的經(jīng)典機(jī)器學(xué)習(xí)算法基本都是一個(gè)函數(shù)表達(dá)問題。后面我們再看。
本文轉(zhuǎn)載自微信公眾號「 thunderbang」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系 thunderbang公眾號。


























