聊聊Hive常見(jiàn)的分析函數(shù)
本文轉(zhuǎn)載自微信公眾號(hào)「大數(shù)據(jù)技術(shù)與數(shù)倉(cāng)」,作者西貝。轉(zhuǎn)載本文請(qǐng)聯(lián)系大數(shù)據(jù)技術(shù)與數(shù)倉(cāng)公眾號(hào)。
1.基本語(yǔ)法
- Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>]
- [<window_expression>])
Function (arg1,..., argn) 可以是下面的四類函數(shù):
- Aggregate Functions: 聚合函數(shù),比如:sum(...)、 max(...)、min(...)、avg(...)等
- Sort Functions: 數(shù)據(jù)排序函數(shù), 比如 :rank(...)、row_number(...)等
- Analytics Functions: 統(tǒng)計(jì)和比較函數(shù), 比如:lead(...)、lag(...)、 first_value(...)等
2.數(shù)據(jù)準(zhǔn)備
樣例數(shù)據(jù)
- [職工姓名|部門編號(hào)|職工ID|工資|崗位類型|入職時(shí)間]
- Michael|1000|100|5000|full|2014-01-29
- Will|1000|101|4000|full|2013-10-02
- Wendy|1000|101|4000|part|2014-10-02
- Steven|1000|102|6400|part|2012-11-03
- Lucy|1000|103|5500|full|2010-01-03
- Lily|1001|104|5000|part|2014-11-29
- Jess|1001|105|6000|part|2014-12-02
- Mike|1001|106|6400|part|2013-11-03
- Wei|1002|107|7000|part|2010-04-03
- Yun|1002|108|5500|full|2014-01-29
- Richard|1002|109|8000|full|2013-09-01
建表語(yǔ)句:
- CREATE TABLE IF NOT EXISTS employee (
- name string,
- dept_num int,
- employee_id int,
- salary int,
- type string,
- start_date date
- )
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '|'
- STORED as TEXTFILE;
加載數(shù)據(jù)
- load data local inpath '/opt/datas/data/employee_contract.txt' into table employee;
3.窗口聚合函數(shù)
(1)查詢姓名、部門編號(hào)、工資以及部門人數(shù)
- select
- name,
- dept_num as deptno ,
- salary,
- count(*) over (partition by dept_num) as cnt
- from employee ;
結(jié)果輸出:
- name deptno salary cnt
- Lucy 1000 5500 5
- Steven 1000 6400 5
- Wendy 1000 4000 5
- Will 1000 4000 5
- Michael 1000 5000 5
- Mike 1001 6400 3
- Jess 1001 6000 3
- Lily 1001 5000 3
- Richard 1002 8000 3
- Yun 1002 5500 3
- Wei 1002 7000 3
(2)查詢姓名、部門編號(hào)、工資以及每個(gè)部門的總工資,部門總工資按照降序輸出
- select
- name ,
- dept_num as deptno,
- salary,
- sum(salary) over (partition by dept_num order by dept_num) as sum_dept_salary
- from employee
- order by sum_dept_salary desc;
結(jié)果輸出:
- name deptno salary sum_dept_salary
- Michael 1000 5000 24900
- Will 1000 4000 24900
- Wendy 1000 4000 24900
- Steven 1000 6400 24900
- Lucy 1000 5500 24900
- Wei 1002 7000 20500
- Yun 1002 5500 20500
- Richard 1002 8000 20500
- Lily 1001 5000 17400
- Jess 1001 6000 17400
- Mike 1001 6400 17400
4.窗口排序函數(shù)
簡(jiǎn)介
窗口排序函數(shù)提供了數(shù)據(jù)的排序信息,比如行號(hào)和排名。在一個(gè)分組的內(nèi)部將行號(hào)或者排名作為數(shù)據(jù)的一部分進(jìn)行返回,最常用的排序函數(shù)主要包括:
row_number:根據(jù)具體的分組和排序,為每行數(shù)據(jù)生成一個(gè)起始值等于1的唯一序列數(shù)
rank:對(duì)組中的數(shù)據(jù)進(jìn)行排名,如果名次相同,則排名也相同,但是下一個(gè)名次的排名序號(hào)會(huì)出現(xiàn)不連續(xù)。比如查找具體條件的topN行
dense_rank:dense_rank函數(shù)的功能與rank函數(shù)類似,dense_rank函數(shù)在生成序號(hào)時(shí)是連續(xù)的,而rank函數(shù)生成的序號(hào)有可能不連續(xù)。當(dāng)出現(xiàn)名次相同時(shí),則排名序號(hào)也相同。而下一個(gè)排名的序號(hào)與上一個(gè)排名序號(hào)是連續(xù)的。
percent_rank:排名計(jì)算公式為:(current rank - 1)/(total number of rows - 1)
ntile:將一個(gè)有序的數(shù)據(jù)集劃分為多個(gè)桶(bucket),并為每行分配一個(gè)適當(dāng)?shù)耐皵?shù)。它可用于將數(shù)據(jù)劃分為相等的小切片,為每一行分配該小切片的數(shù)字序號(hào)。
(1)查詢姓名、部門編號(hào)、工資、排名編號(hào)(按工資的多少排名)
- select
- name ,
- dept_num as dept_no ,
- salary,
- row_number() over (order by salary desc ) rnum
- from employee;
結(jié)果輸出:
- name dept_no salary rnum
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 4
- Jess 1001 6000 5
- Yun 1002 5500 6
- Lucy 1000 5500 7
- Lily 1001 5000 8
- Michael 1000 5000 9
- Wendy 1000 4000 10
- Will 1000 4000 11
(2)查詢每個(gè)部門工資最高的兩個(gè)人的信息(姓名、部門、薪水)
- select
- name,
- dept_num,
- salary
- from
- (
- select name ,
- dept_num ,
- salary,
- row_number() over (partition by dept_num order by salary desc ) rnum
- from employee) t1
- where rnum <= 2;
結(jié)果輸出:
- name dept_num salary
- Steven 1000 6400
- Lucy 1000 5500
- Mike 1001 6400
- Jess 1001 6000
- Richard 1002 8000
- Wei 1002 7000
(3)查詢每個(gè)部門的員工工資排名信息
- select
- name ,
- dept_num as dept_no ,
- salary,row_number() over (partition by dept_num order by salary desc ) rnum
- from employee;
結(jié)果輸出:
- name dept_no salary rnum
- Steven 1000 6400 1
- Lucy 1000 5500 2
- Michael 1000 5000 3
- Wendy 1000 4000 4
- Will 1000 4000 5
- Mike 1001 6400 1
- Jess 1001 6000 2
- Lily 1001 5000 3
- Richard 1002 8000 1
- Wei 1002 7000 2
- Yun 1002 5500 3
(4)使用rank函數(shù)進(jìn)行排名
- select
- name,
- dept_num,
- salary,
- rank() over (order by salary desc) rank
- from employee;
結(jié)果輸出:
- name dept_num salary rank
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 3
- Jess 1001 6000 5
- Yun 1002 5500 6
- Lucy 1000 5500 6
- Lily 1001 5000 8
- Michael 1000 5000 8
- Wendy 1000 4000 10
- Will 1000 4000 10
(5)使用dense_rank進(jìn)行排名
- select
- name,
- dept_num,
- salary,
- dense_rank() over (order by salary desc) rank
- from employee;
結(jié)果輸出:
- name dept_num salary rank
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 3
- Jess 1001 6000 4
- Yun 1002 5500 5
- Lucy 1000 5500 5
- Lily 1001 5000 6
- Michael 1000 5000 6
- Wendy 1000 4000 7
- Will 1000 4000 7
(6)使用percent_rank()進(jìn)行排名
- select
- name,
- dept_num,
- salary,
- percent_rank() over (order by salary desc) rank
- from employee;
結(jié)果輸出:
- name dept_num salary rank
- Richard 1002 8000 0.0
- Wei 1002 7000 0.1
- Mike 1001 6400 0.2
- Steven 1000 6400 0.2
- Jess 1001 6000 0.4
- Yun 1002 5500 0.5
- Lucy 1000 5500 0.5
- Lily 1001 5000 0.7
- Michael 1000 5000 0.7
- Wendy 1000 4000 0.9
- Will 1000 4000 0.9
(7)使用ntile進(jìn)行數(shù)據(jù)分片排名
- SELECT
- name,
- dept_num as deptno,
- salary,
- ntile(4) OVER(ORDER BY salary desc) as ntile
- FROM employee;
結(jié)果輸出:
- name deptno salary ntile
- Richard 1002 8000 1
- Wei 1002 7000 1
- Mike 1001 6400 1
- Steven 1000 6400 2
- Jess 1001 6000 2
- Yun 1002 5500 2
- Lucy 1000 5500 3
- Lily 1001 5000 3
- Michael 1000 5000 3
- Wendy 1000 4000 4
- Will 1000 4000 4
從 Hive v2.1.0開(kāi)始, 支持在OVER語(yǔ)句里使用聚集函數(shù),比如
- SELECT
- dept_num,
- row_number() OVER (PARTITION BY dept_num ORDER BY sum(salary)) as rk
- FROM employee
- GROUP BY dept_num;
結(jié)果輸出:
- dept_num rk
- 1000 1
- 1001 1
- 1002 1
5.窗口分析函數(shù)
常用的分析函數(shù)主要包括:
- cume_dist
如果按升序排列,則統(tǒng)計(jì):小于等于當(dāng)前值的行數(shù)/總行數(shù)(number of rows ≤ current row)/(total number of rows)。如果是降序排列,則統(tǒng)計(jì):大于等于當(dāng)前值的行數(shù)/總行數(shù)。比如,統(tǒng)計(jì)小于等于當(dāng)前工資的人數(shù)占總?cè)藬?shù)的比例 ,用于累計(jì)統(tǒng)計(jì)。
- lead(value_expr[,offset[,default]])
用于統(tǒng)計(jì)窗口內(nèi)往下第n行值。第一個(gè)參數(shù)為列名,第二個(gè)參數(shù)為往下第n行(可選,默認(rèn)為1),第三個(gè)參數(shù)為默認(rèn)值(當(dāng)往下第n行為NULL時(shí)候,取默認(rèn)值,如不指定,則為NULL
- lag(value_expr[,offset[,default]]):
與lead相反,用于統(tǒng)計(jì)窗口內(nèi)往上第n行值。第一個(gè)參數(shù)為列名,第二個(gè)參數(shù)為往上第n行(可選,默認(rèn)為1),第三個(gè)參數(shù)為默認(rèn)值(當(dāng)往上第n行為NULL時(shí)候,取默認(rèn)值,如不指定,則為NULL)
- first_value: 取分組內(nèi)排序后,截止到當(dāng)前行,第一個(gè)值
- last_value
取分組內(nèi)排序后,截止到當(dāng)前行,最后一個(gè)值
- (1)統(tǒng)計(jì)小于等于當(dāng)前工資的人數(shù)占總?cè)藬?shù)的比例
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (ORDER BY salary) as cume
- FROM employee;
結(jié)果輸出:
- name deptno salary cume
- Wendy 1000 4000 0.18181818181818182
- Will 1000 4000 0.18181818181818182
- Lily 1001 5000 0.36363636363636365
- Michael 1000 5000 0.36363636363636365
- Yun 1002 5500 0.5454545454545454
- Lucy 1000 5500 0.5454545454545454
- Jess 1001 6000 0.6363636363636364
- Mike 1001 6400 0.8181818181818182
- Steven 1000 6400 0.8181818181818182
- Wei 1002 7000 0.9090909090909091
- Richard 1002 8000 1.0
(2)統(tǒng)計(jì)大于等于當(dāng)前工資的人數(shù)占總?cè)藬?shù)的比例
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (ORDER BY salary desc) as cume
- FROM employee;
結(jié)果輸出:
- name deptno salary cume
- Richard 1002 8000 0.09090909090909091
- Wei 1002 7000 0.18181818181818182
- Mike 1001 6400 0.36363636363636365
- Steven 1000 6400 0.36363636363636365
- Jess 1001 6000 0.45454545454545453
- Yun 1002 5500 0.6363636363636364
- Lucy 1000 5500 0.6363636363636364
- Lily 1001 5000 0.8181818181818182
- Michael 1000 5000 0.8181818181818182
- Wendy 1000 4000 1.0
- Will 1000 4000 1.0
(3)按照部門統(tǒng)計(jì)小于等于當(dāng)前工資的人數(shù)占部門總?cè)藬?shù)的比例
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (PARTITION BY dept_num ORDER BY salary) as cume
- FROM employee;
結(jié)果輸出:
- name deptno salary cume
- Wendy 1000 4000 0.4
- Will 1000 4000 0.4
- Michael 1000 5000 0.6
- Lucy 1000 5500 0.8
- Steven 1000 6400 1.0
- Lily 1001 5000 0.3333333333333333
- Jess 1001 6000 0.6666666666666666
- Mike 1001 6400 1.0
- Yun 1002 5500 0.3333333333333333
- Wei 1002 7000 0.6666666666666666
- Richard 1002 8000 1.0
(4)按部門分組,統(tǒng)計(jì)每個(gè)部門員工的工資以及大于等于該員工工資的下一個(gè)員工的工資
- SELECT
- name,
- dept_num as deptno,
- salary,
- lead(salary,1) OVER (PARTITION BY dept_num ORDER BY salary) as lead
- FROM employee;
結(jié)果輸出:
- name deptno salary lead
- Wendy 1000 4000 4000
- Will 1000 4000 5000
- Michael 1000 5000 5500
- Lucy 1000 5500 6400
- Steven 1000 6400 NULL
- Lily 1001 5000 6000
- Jess 1001 6000 6400
- Mike 1001 6400 NULL
- Yun 1002 5500 7000
- Wei 1002 7000 8000
- Richard 1002 8000 NULL
(5)按部門分組,統(tǒng)計(jì)每個(gè)部門員工的工資以及小于等于該員工工資的上一個(gè)員工的工資
- SELECT
- name,
- dept_num as deptno,
- salary,
- lag(salary,1) OVER (PARTITION BY dept_num ORDER BY salary) as lead
- FROM employee;
結(jié)果輸出:
- name deptno salary lead
- Wendy 1000 4000 NULL
- Will 1000 4000 4000
- Michael 1000 5000 4000
- Lucy 1000 5500 5000
- Steven 1000 6400 5500
- Lily 1001 5000 NULL
- Jess 1001 6000 5000
- Mike 1001 6400 6000
- Yun 1002 5500 NULL
- Wei 1002 7000 5500
- Richard 1002 8000 7000
(6)按部門分組,統(tǒng)計(jì)每個(gè)部門員工工資以及該部門最低的員工工資
- SELECT
- name,
- dept_num as deptno,
- salary,
- first_value(salary) OVER (PARTITION BY dept_num ORDER BY salary) as fval
- FROM employee;
結(jié)果輸出:
- name deptno salary fval
- Wendy 1000 4000 4000
- Will 1000 4000 4000
- Michael 1000 5000 4000
- Lucy 1000 5500 4000
- Steven 1000 6400 4000
- Lily 1001 5000 5000
- Jess 1001 6000 5000
- Mike 1001 6400 5000
- Yun 1002 5500 5500
- Wei 1002 7000 5500
- Richard 1002 8000 5500
(7)按部門分組,統(tǒng)計(jì)每個(gè)部門員工工資以及該部門最高的員工工資
- SELECT
- name,
- dept_num as deptno,
- salary,
- last_value(salary) OVER (PARTITION BY dept_num ORDER BY salary RANGE
- BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lval
- FROM employee;
結(jié)果輸出:
- name deptno salary lval
- Wendy 1000 4000 6400
- Will 1000 4000 6400
- Michael 1000 5000 6400
- Lucy 1000 5500 6400
- Steven 1000 6400 6400
- Lily 1001 5000 6400
- Jess 1001 6000 6400
- Mike 1001 6400 6400
- Yun 1002 5500 8000
- Wei 1002 7000 8000
- Richard 1002 8000 8000
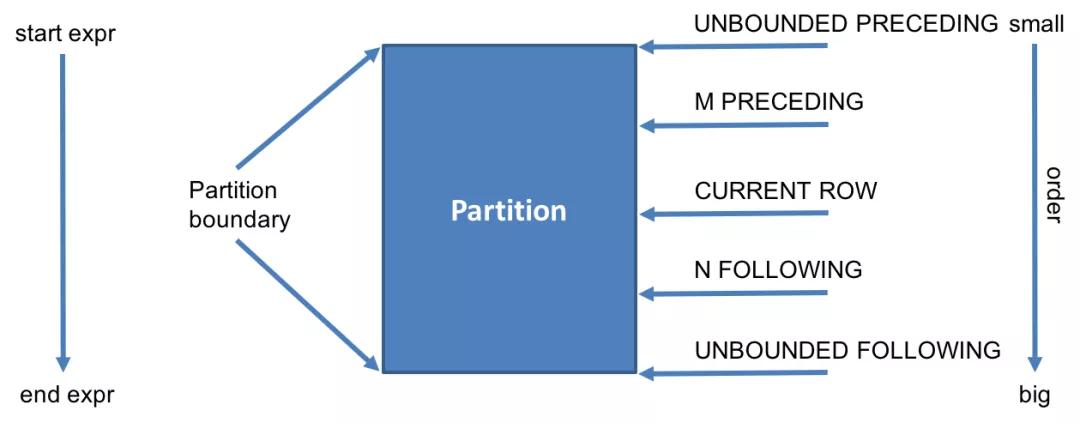
注意:last_value默認(rèn)的窗口是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示當(dāng)前行永遠(yuǎn)是最后一個(gè)值,需改成RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
img
- RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
為默認(rèn)值,即當(dāng)指定了ORDER BY從句,而省略了window從句 ,表示從開(kāi)始到當(dāng)前行。
- RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
表示從當(dāng)前行到最后一行
- RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
表示所有行
- n PRECEDING m FOLLOWING
表示窗口的范圍是:[(當(dāng)前行的行數(shù))- n, (當(dāng)前行的行數(shù))+m]