Go可用性(七) 總結: 一張圖串聯可用性知識點
在前面的幾篇文章當中我們聊到了 隔離設計、令牌桶算法、漏桶算法、自適應限流和熔斷,可用性的建設遠不止這些,這一部分的內容在進階訓練營中也講了 7 個小時,其他部分如果感興趣的話推薦購買源課程觀看。
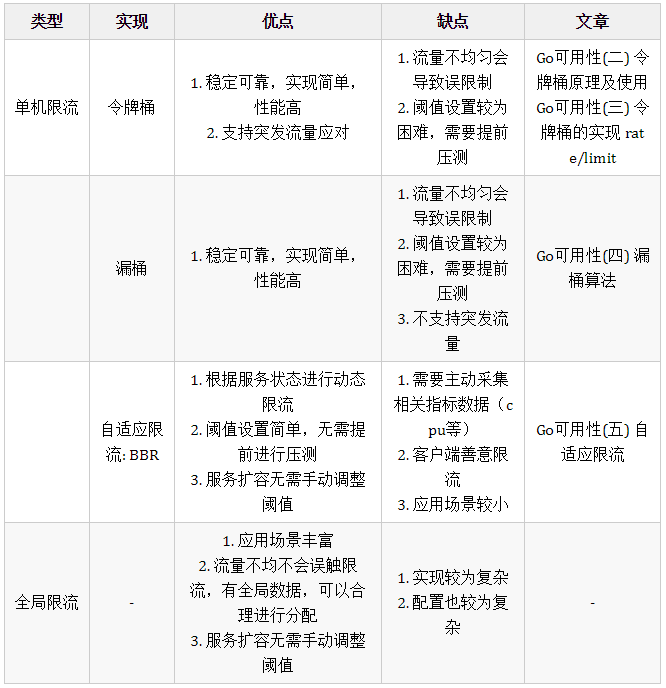
由于前面的文章大部分都在講限流相關的內容,所以我們先看一下不同的限流方式的對比
限流對比
微服務可用性設計總結
接下來我們就一起來串聯我們之前講到的和課程上講到的一些內容總結一下可用性應該怎么做。
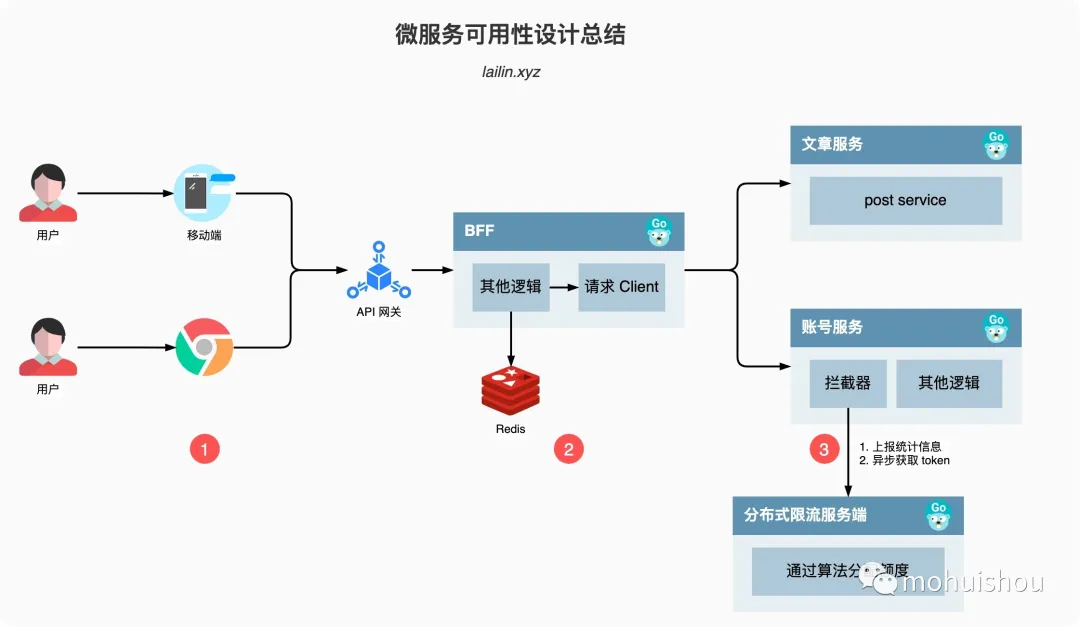
微服務可用性設計總結
如上圖所示,我們從一個簡單的用戶訪問出發,用戶訪問到我們的服務一般是先通過我們的移動客戶端或者是瀏覽器,然后請求再依次通過 CDN、防火墻、API網關、BFF以及各個后端服務,整條鏈路還是比較長的。
我們上圖其實已經一部分體現了隔離設計,所以后面我就不再提了。
1. 移動客戶端/瀏覽器
客戶端是觸及用戶的第一線,所以這一層做的可用性優化尤為的重要
降級: 降級的本質是提供給用戶有損服務,所以在觸及用戶的第一線如何安撫好或者說如何騙過用戶的眼睛尤為重要
- 本地緩存,客戶端需要有一些本地緩存數據,不僅可以加速用戶首屏的加載時間,還可以在后端服務出現故障的時候起到一定的緩沖作用
- 降級數據兼容,服務端有時為了降級會返回一些 mock 數據或者是空數據,這些數據一定要和客戶端的對接好,如果沒有對接好很容易就會出現異常或者是白屏
流控: 在服務出現問題的時候,用戶總是會不斷的主動嘗試重試,如果不加以限制會讓我們本就不堪重負的后端服務雪上加霜
- 所以在客戶端需要做類似熔斷的流控措施,常見的思路有指數級退讓,或者是通過服務端的返回獲取冷卻的時間
2. BFF/Client
BFF 是我們后端服務的橋頭堡,當請求來到 BFF 層的時候,BFF 既是服務端,又是客戶端,因為它一般需要請求很多其他的后端服務來完成數據的編排,提供客戶端想要的數據
超時控制: 超時控制需要注意的兩點是默認值和超時傳遞
- 默認值,基礎庫需要有一些默認值,避免客戶端用戶漏填,錯填,舉個例子,如果開發填寫一個明顯過大的值 100s 才超時,這時候我們基礎庫可以直接拋出錯誤,或者是警告只有手動忽略才可以正常啟動。我之前有一個應用就是因為忘記配置超時時間,依賴的服務 hang 住導致我的服務也無法正常服務了,即使我之前做了緩存也沒有用,因為之前的邏輯是只有請求報錯才會降級使用緩存數據。
- 超時傳遞,例如我們上圖,假設我們整個請求的超時時間配置的 500ms,BFF 里面首先經過一些邏輯判斷消耗了 100ms,然后去請求 redis,我們給 redis 配置的超時時間 max_con 是 500ms,這時候就不能用 500ms 作為超時時間,得用 min(請求剩余的超時時間,max_con)也就是 400ms 作為我們的超時時間,同樣我們請求下游的服務也需要將超時時間攜帶到 header 信息里面,這樣下游服務就可以繼承上游的超時時間來進行超時判斷。
負載均衡: 一般我們比較常用的負載均衡策略就是輪訓,或者說加個權重,這個比較大的問題就是,我們的服務性能并不是每個實例都一樣,收到宿主機的型號,當前機器上服務的數量等等因素的影響,并且由于我們的服務是在隨時漂移和變化的,所以我們沒有辦法為每個實例配上合適的權重。
- 所以我們可以根據一些統計數據,例如 cpu、load 等信息獲取當前服務的負載情況,然后根據不同的負載情況進行打分,然后來進行流量的分配,這樣就可以將我們的流量比較合理的分配到各個實例上了。
重試: 重試一定要注意避免雪崩
- 當我們的服務出現一些錯誤的時候,我們可以通過重試來解決,例如如果部分實例過載導致請求很慢,我們通過重試,加上面的負載均衡可以將請求發送到正常的實例,這樣可以提高我們的 SLA
- 但是需要的注意的是,重試只能在錯誤發生的地方進行重試,不能級聯重試,級聯重試很容易造成雪崩,一般的做法就是約定一個 code 只要出現這個 code 我們就知道下游已經嘗試過重試了,我們就不要再重試了
熔斷: 一般來說如果只是部分實例出現了問題,我們通過負載均衡階段+重試一般就可以解決,但如果服務整體出現了問題,作為客戶端就需要使用熔斷的措施了。
- 熔斷常見的有開啟,關閉,半開啟的狀態,例如 hystrix-go 的實現,但是這種方式比較死板,只要觸發了熔斷就一個請求都無法放過,所以就又學習了 Google SRE 的做法,同構計算概率來進行判斷,沒有了半開啟的狀態,開啟的時候也不會說是一刀切。
降級: 當我們請求一些不那么重要的服務出現錯誤時,我們可以通過降級的方式來返回請求,降級一般在 BFF 層做,可以有效的防止污染其他服務的緩存。常見的討論有返回 mock 數據,緩存數據,空數據等
3. Server
BFF 其實也是服務端,但是為了流暢的講解,主要將其作為了客戶端的角色。服務端主要的是限流的措施,當流量從 BFF 來到我們的服務之后,我們會使用令牌桶算法嘗試獲取 token,如果 token 不夠就丟棄,如果 token 足夠就完成請求邏輯。
我們的 token 是從哪里來的呢?
攔截器會定時的向 Token Server 上報心跳數據,包含了一些統計信息,同時從 Token Server 獲取一定數量的 Token,當 Token Server 接收到請求之后會通過最大最小公平分享的算法,根據每個服務實例上報的統計信息進行 Token 的分配。
這個其實就是之前沒有講到的分布式限流的思路,在單個服務實例上又使用了單機限流的算法
總結
到這里我們的可用性相關的知識點就算是告一段落了,前面的文章主要講解了限流的相關知識點,雖然其他的沒有細說,但是這一篇總結也算是都涉及到了,包括隔離設計、限流(單機限流、自適應限流、分布式限流)、超時控制、降級、熔斷、負載均衡、重試。OK,話不多說,我們下篇文章見。
本文轉載自微信公眾號「mohuishou」,可以通過以下二維碼關注。轉載本文請聯系mohuishou公眾號。