企業微信萬億級日志檢索系統
作者:datonli,騰訊 WXG 后臺開發工程師
背景
開發在定位問題時需要查找日志,但企業微信業務模塊日志存儲在本機磁盤,這會造成以下問題:
- 日志查找效率低下:一次用戶請求涉及近十個模塊,幾十臺機器,查找日志需要登錄機器 grep 日志文件。這一過程通常需要耗費 10 分鐘以上,非常低效;
- 日志保存時間短:單機磁盤存儲容量有限,為保存最新日志,清理腳本周期清理舊日志文件騰出磁盤空間,比如:現網一核心存儲 7 天日志占用了 90%的磁盤空間,7 天前日志都會被清理,用戶投訴因日志被清理而得不到解決;
- 日志缺失:雖然現網保留 7 天最新日志,但是由于某些模塊請求量大或日志打印不合理,我們也會限制一個小時日志打印量,超過閾值后不再保存,比如:現網一核心存儲前 10 分鐘打了 10G 日志達到閾值,后 50 分鐘日志不再保存了,用戶投訴因日志缺失無法得到解決。
我們希望有這樣一個日志系統:
- 存儲全量日志:由于 To B 業務的特殊性,至少需要保存 30 天的全量日志(數 PB 日志量,日志達數萬億條),方便回查日志定位問題;
- 日志快速定位:根據模塊+時間段+關鍵字或用戶請求信息快速定位日志;
- 實時性:日志峰值達數億條每秒,需要做到秒級入庫、秒級可查;
- 支持日志模糊匹配和統計:單機日志查詢常用到模糊匹配以及 awk/uniq/sort 等復雜統計,在新日志系統同樣希望能夠支持;
- 支持模塊級全量日志查詢:日常運營中有些用戶投訴的問題并不確定具體發生時間,需要對模塊進行全量日志(日志量達 TB 級別)查詢。
業界方案對比
公司內外有很多日志系統方案,根據是否對日志做全文檢索可以分為兩類:
- 全文檢索的日志系統:對日志內容切分詞和建倒排,通過查詢關鍵詞的倒排取交集支持模糊匹配,這類系統一般入庫資源消耗較多,也不支持日志統計,典型實現有:ELK、Hermes 以及騰訊云日志服務(Cloud Log Service, CLS)等系統;
- 部分字段檢索的日志系統:只對部分字段建索引,支持特定字段的快速檢索,入庫資源消耗較低,但是這類系統對模糊匹配未能很好支持,也不支持日志統計,不支持模塊級全量日志查詢,如 wxlog、LogTrace 等系統。
我們新設計的檢索系統在資源消耗較小的前提下,很好滿足背景所提的所有檢索需求。
方案設計的考慮
保存時間短和日志缺失的問題
單機存儲空間的限制導致日志丟失,日志也沒法長時間保存,如何突破單機存儲空間限制呢?
嗯,是的,使用分布式文件系統替換單機文件系統就可以了!在可水平擴展的分布式文件系統支撐下,存儲空間無限大,日志不再因存儲空間而丟失了。
日志查找效率低下問題
日志查找效率低下,其根源是日志散落到多臺機器,需要登錄到機器做日志 grep。引入了分布式文件系統存儲全網日志后,我們看到的仍然是一個一個不相關的日志文件,快速定位日志仍然困難。如何提高日志定位的效率呢?
索引!就像是利用索引提升數據庫表查詢效率一樣,我們對日志數據建立索引,快速定位到所需日志。那么,需要構建怎樣的索引呢?先看看面臨的兩種問題定位場景:
- 開發收到模塊告警,通過告警信息結合代碼找到關鍵字,使用關鍵字查找模塊告警時間段內的日志;
- 根據用戶投訴找到用戶請求信息,使用用戶請求信息查找所有關聯模塊的日志。從以上場景看出,我們通常根據模塊+時間段+關鍵字或者用戶請求信息查找日志。所以,對模塊、時間、用戶請求信息建索引提升日志查找效率。
入庫資源消耗問題
為了支持模糊查詢,業界方案一般都會對日志內容分詞建索引,這會消耗大量資源。日志查詢系統有兩個特點:每天只有數百次查詢請求,日志存儲模塊(分布式文件系統)IO 密集、CPU 利用率低。為了支持用戶模糊查詢請求,入庫時不對日志內容分詞建索引。用戶查詢時,日志存儲模塊使用關鍵字對日志內容正則匹配過濾(利用本機空閑 CPU)。這樣既解決了入庫資源消耗高的問題,又解決了存儲機 CPU 低利用率的問題。
面臨的挑戰
我們通過分布式文件系統和索引解決了目前的問題,同時也帶來了新的挑戰:
高性能:目前企業微信日志量月級數 PB,日志數萬億條,天級數百 TB,面對如此海量日志,如何做到入庫和查詢的高性能?
可靠性:引入了分布式文件系統以及索引帶來更大的復雜性,如何保證整個日志系統可靠性?
支持靈活多變的用戶查詢需求:通過調研發現,用戶主要有以下 4 種日志查詢使用場景:a) 一次用戶請求關聯的所有模塊日志查詢;b) 模塊一段時間內日志模糊查詢;c) 模塊全量日志模糊查詢;d) 查詢日志統計(如:awk/uniq/sort 指令等)。如何支持如此靈活多變的用戶查詢需求?
名詞解釋
在介紹系統前,先對使用的名詞進行解釋:
callid:唯一標識一次用戶請求,每條日志中都會攜帶 callid 信息;
模糊查詢:根據用戶輸入模塊、時間段和關鍵字查詢日志;
全鏈路查詢:根據 callid 查詢一次用戶請求所有關聯的模塊日志。
系統架構
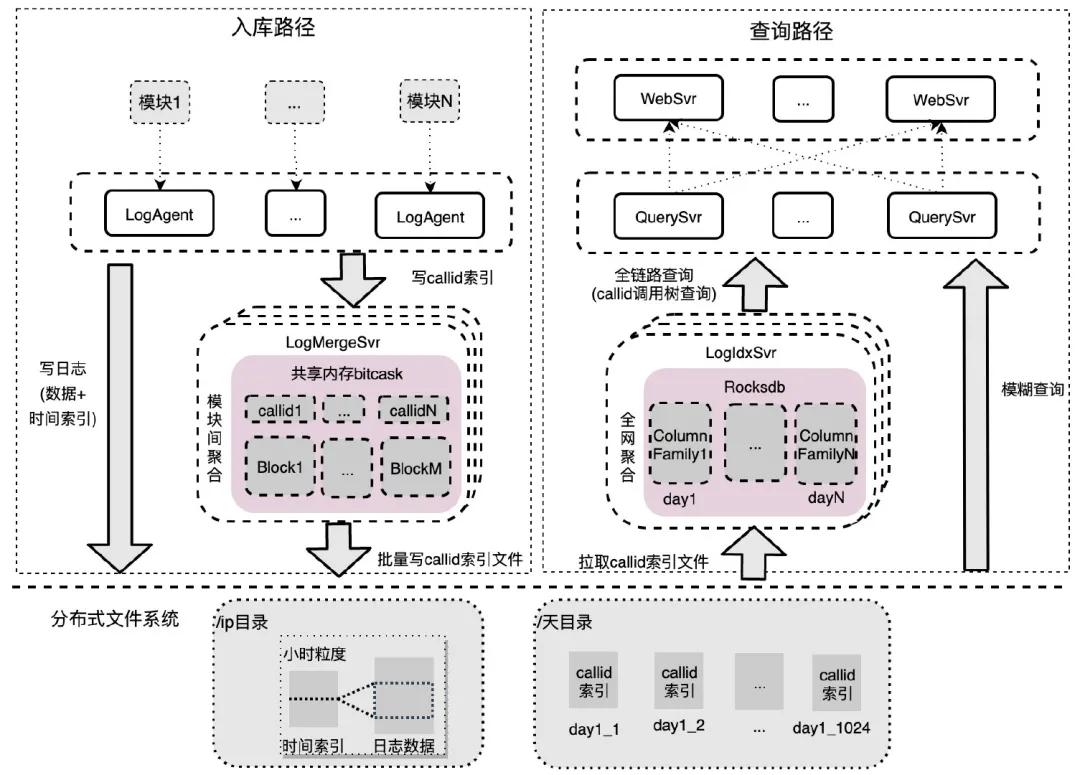
企業微信日志檢索系統主要分為 6 個模塊:
- LogAgent:和業務模塊同機部署,對模塊內日志進行聚集,數據批量寫分布式文件系統,callid 索引批量發送到 LogMergeSvr 聚集;
- LogMergeSvr:對一段時間內的 callid 索引進行模塊間聚集,批量寫分布式文件系統;
- 存儲模塊(分布式文件系統):存儲原始日志數據、時間索引和 callid 索引數據;
- LogIdxSvr:對 callid 索引進行全網聚合,底層存儲用的是 Rocksdb;
- WebSvr:接收用戶網頁請求,并發查詢 QuerySvr。
- QuerySvr:查詢執行模塊,支持全鏈路查詢、模糊查詢、awk 統計等。
接下來分別闡述系統設計和實現中面臨的挑戰點以及解決辦法。
如何實現系統高性能
日志入庫高性能
目前,企業微信全網日志入庫峰值 qps 數億條每秒,而分布式文件系統數據節點僅僅 20 臺(單臺 12 塊 SATA 盤,單盤 IOPS 約 100 左右),我們如何使用少量數據節點支撐如此高峰值的日志秒級入庫呢?
數據入庫高性能
在模糊查詢場景下,用戶使用模塊/機器+時間段+關鍵字進行查詢。為提升數據入庫性能,我們以每臺機器的 IP 作為分布式文件系統的目錄,機器上模塊打印的日志寫入小時粒度的日志文件,這樣不同機器寫入自己獨占的日志數據文件,相互間數據寫入無競爭,入庫性能最佳。與此同時,目錄結構就相當于一個快速區分不同模塊/機器的索引,這也能提升日志查詢效率。
為了進一步提升數據入庫性能,LogAgent 使用緩沖隊列緩存日志數據,累積 8MB 數據后批量順序寫入日志文件中,寫 qps 降低為原本的 4 萬分之一。同時為了快速查找日志數據,對 8MB 日志數據的時間戳采樣,批量寫入同目錄下的時間索引文件中。
callid 索引入庫高性能
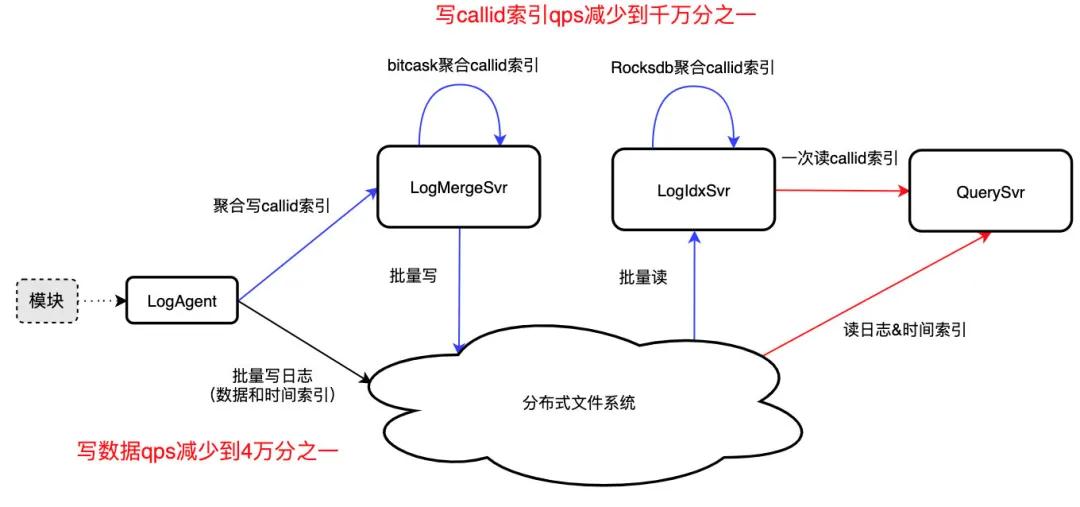
同一 callid 索引散落在不同模塊不同機器,為了全鏈路查詢,需要對數億條/秒的 callid 索引做秒級聚合,以支持秒級入庫、秒級可查,這無疑是一個技術難題。
為了解決這一難題,我們通過三重聚合減少 callid 索引寫入壓力,最終達到 qps 減少到千萬分之一、一次 IO 讀取 callid 所有日志位置的效果:
- 模塊內聚合:LogAgent 聚合模塊內 callid 索引,批量寫入 LogMergeSvr,qps 約減少到萬分之一;
- 模塊間聚合:LogMergeSvr 聚合模塊間一段時間內的 callid 索引,批量寫分布式文件系統,qps 約減少到千分之一;
- 全網聚合:callid 索引文件不利于高效讀取,LogIdxSvr 利用 Rocksdb 的 Merge 聚合全網的 callid 索引,一次 IO 可讀取 callid 所有日志位置。
日志查詢高性能
增加索引提升查詢性能
開發通常依據模塊、時間段、callid 這 3 個維度查詢日志,為了加快查詢性能也對這 3 個維度分別增加索引:
- 模塊:一個模塊包含若干機器,每臺機器在分布式文件系統中擁有獨占的日志目錄(用 IP 區分),用于保存機器小時粒度日志文件。通過模塊找到所有機器 IP 后,可快速找到該模塊的日志在分布式文件系統中的日志目錄。
- 時間段:日志數據保存在機器目錄的小時粒度文件中,通過對日志時間采樣保存為相應時間索引文件。當按照時間段查找日志時,可根據時間索引文件快速找到該時間段的日志位置范圍。
- callid:解析日志建立 callid 到日志位置的索引,散落在多個模塊的 callid 索引通過 LogAgent、LogMergeSvr 以及 LogIdxSvr 三重聚合后,最終存儲在 LogIdxSvr 的 Rocksdb 中。全鏈路日志查詢可通過讀取一次 Rocksdb 獲取所有相關日志位置,快速讀取到所需日志。
模糊查詢高性能
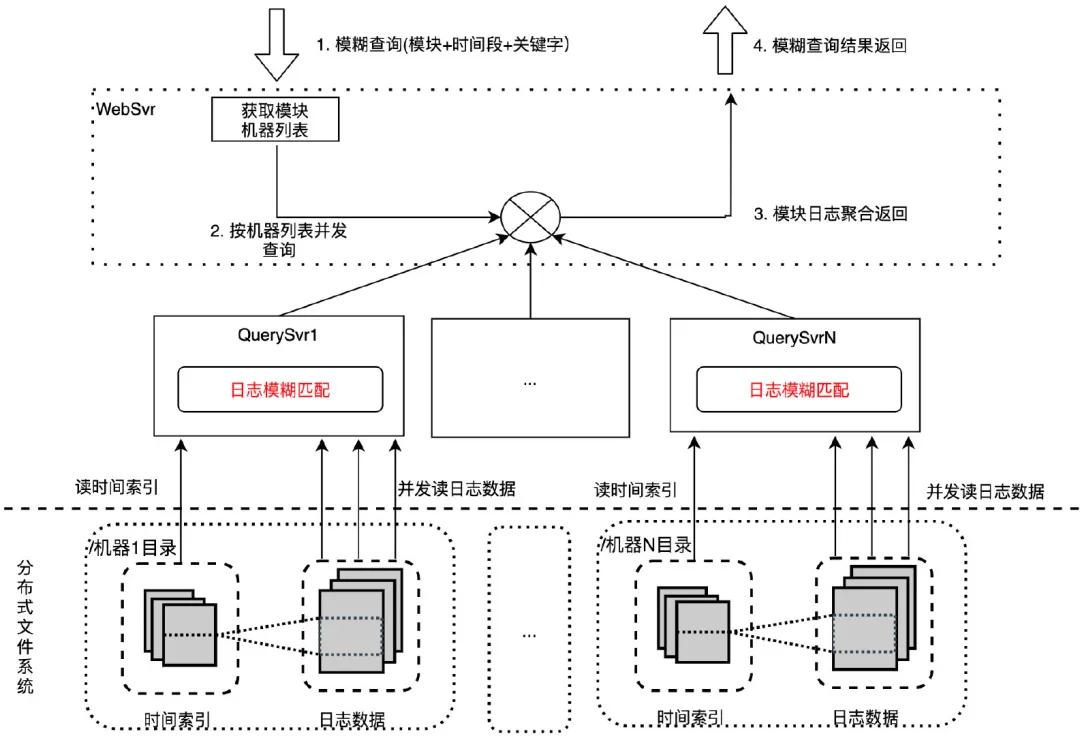
原始版本:并發檢索 WebSvr 接收用戶模糊查詢請求(模塊+時間段+關鍵字),依據模塊獲取機器列表后,按機器列表并發請求到多臺 QuerySvr 執行機器粒度日志查詢:通過機器 IP 找到機器日志目錄,根據時間段拉取時間索引文件,確定日志數據范圍,并發拉取日志到本機用關鍵字做模糊匹配。最終將匹配后的日志返回給 WebSvr 聚合展示給用戶。
通過并發檢索的優化手段,模糊查詢一個模塊一小時日志(12 臺機器,7.95GB 日志量)耗時從 1 分鐘降到 5.6 秒。
優化版本:模糊匹配下沉分布式文件系統 在系統壓測時我們發現 QuerySvr 帶寬和 cpu 存在性能瓶頸,原因是 QuerySvr 讀取大量未模糊匹配的日志數據,打滿了網絡帶寬,并且在 QuerySvr 做模糊匹配也會消耗大量 cpu 資源。我們需要進行性能優化。考慮到分布式文件系統是重 IO 操作,cpu 利用率很低,將模糊匹配邏輯下沉到分布式文件系統,這樣既解決了 QuerySvr 帶寬和 cpu 性能瓶頸問題,又充分利用了文件系統的 cpu,避免資源浪費。通過模糊匹配下沉的優化手段,模糊查詢一個模塊一小時日志(12 臺機器,7.95GB 日志量)耗時從 5.6 秒降到 2.5 秒。
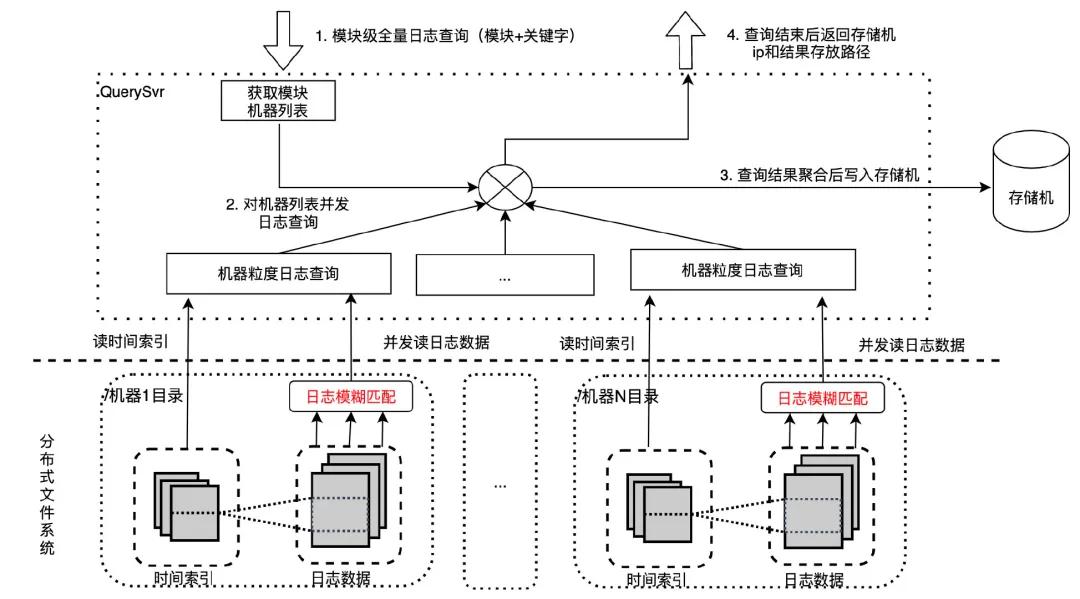
全鏈路查詢高性能
全鏈路查詢和模糊查詢類似,同樣利用了并發提升查詢性能,稍有不同的是全鏈路查詢根據 callid 讀取 LogIdxSvr 確定日志位置列表,按照位置列表并發讀取日志數據,聚合后將日志返回給用戶。
如何保證系統可靠性
我們通過引入了分布式文件系統和索引服務解決了日志丟失、保存時間短和快速定位問題,但系統復雜性導致的可靠性問題,是我們面臨的第二大挑戰。
數據可靠性保證
日志數據緩沖隊列(共享內存+本機磁盤文件)
LogAgent 負責將日志數據和時間索引寫入分布式文件系統,當分布式文件系統抖動時,為了不丟棄待寫日志數據,LogAgent 使用緩沖隊列(共享內存+本機磁盤文件)緩存日志數據,待抖動恢復后讀出緩存數據寫入文件系統。
索引可靠性保證
服務抖動 LogIdxSvr 使用 Rocksdb 作為底層存儲聚合全網 callid 索引,但是 Rocksdb 在高并發寫入時容易出現寫入抖動進而導致索引丟失,為了保證 callid 索引可靠性,LogMergeSvr 先將 callid 索引寫入分布式文件系統保存,LogIdxSvr 從分布式文件系統拉,分布式文件系統當做 queue 使用起到削峰填谷作用,保證 callid 索引可靠性。
機器壞盤 LogIdxSvr 出現壞盤會導致已聚合到本機的 callid 索引數據丟失,新起的 LogIdxSvr 重新拉取分布式文件系統的 callid 索引文件,可以重建 Rocksdb 的 callid 索引,保證系統可靠性。
如何支持靈活多變的用戶查詢請求
通過前面的設計,目前可以根據模塊+時間段+關鍵字或者 callid 查找到日志了,但是還不夠,用戶往往還需要對日志做任意維度模糊匹配、日志統計(如:uniq/sort/awk 等)以及模塊級全量日志查詢。
支持任意維度模糊匹配
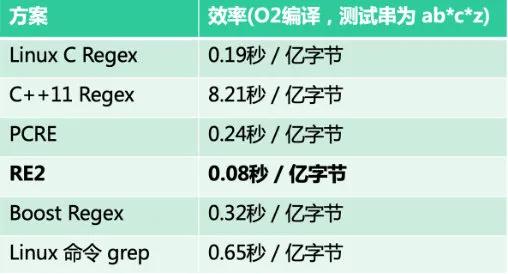
如前所述,通過在分布式文件系統實現模糊匹配邏輯,系統支持對日志做任意維度模糊匹配的需求。通過對比,選擇性能最優的 RE2 正則匹配庫實現模糊匹配邏輯。
支持 awk/uniq/sort 等統計指令
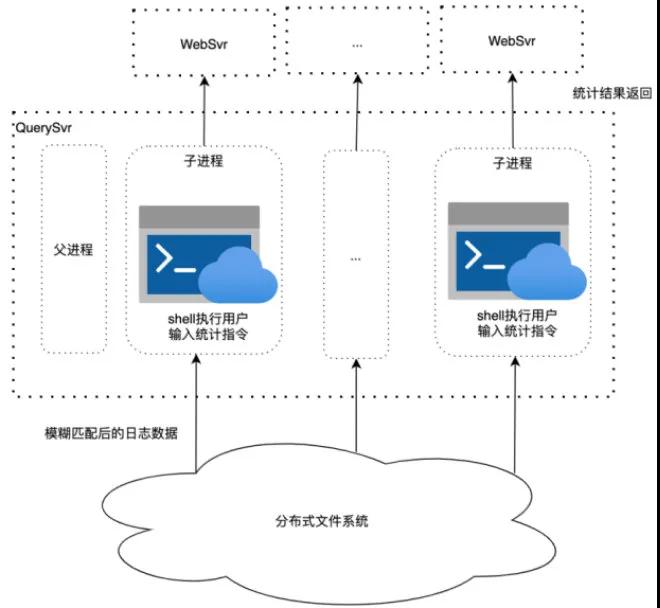
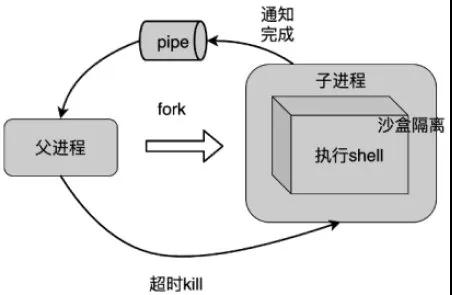
支持統計指令 用戶不僅需要對日志做模糊匹配,還需要對匹配后的日志執行 awk/uniq/sort 等統計指令,其中涉及到指令相互嵌套執行,非常復雜,難以調用相關庫實現。我們通過子進程調用系統 shell 支持這一需求。QuerySvr 從分布式文件系統拉取日志數據到本機后,子進程 shell 調用用戶傳入統計指令處理日志數據,最終結果返回給 WebSvr。子進程處理超時父進程將 kill 掉子進程,防止用戶統計任務耗光 QuerySvr 資源。
安全考慮 由于用戶指令可由用戶自定義輸入,指令執行的安全問題需要重點考慮。通過兩個方法確保執行指令的安全:
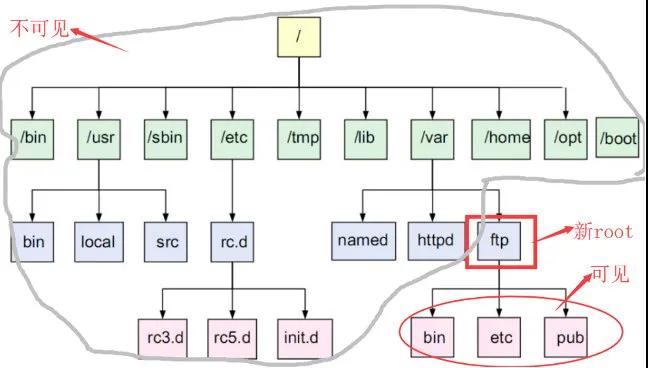
changeroot:使用 Linux 的 changeroot 避免用戶指令操作系統重要目錄;
沙盒限制:使用 Linux 支持的沙盒隔離技術,只允許執行特定指令。
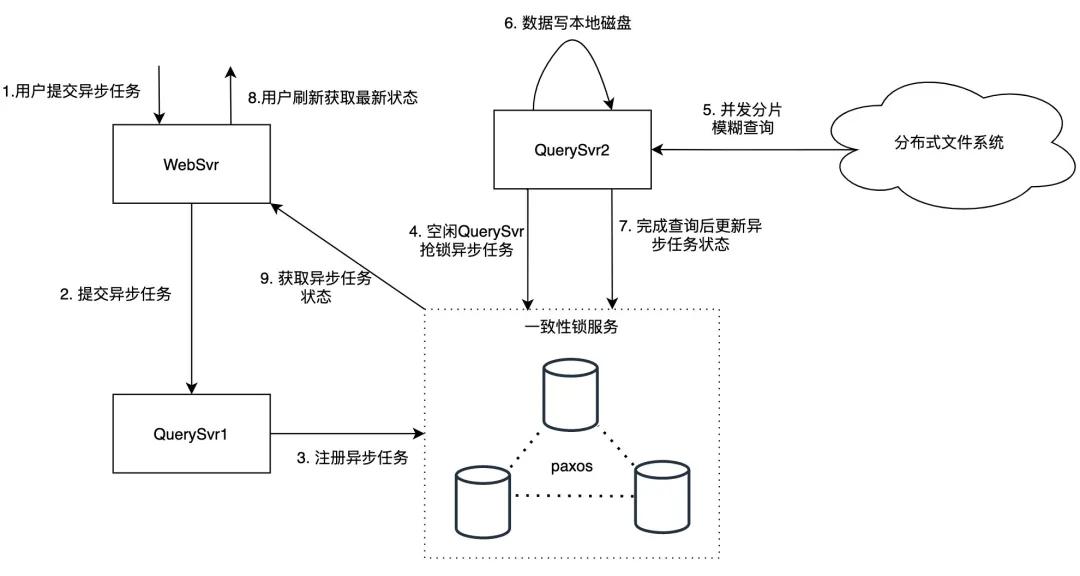
支持模塊級全量日志查詢——異步任務
模塊級全量日志查詢通常涉及 TB 級別日志量,因為涉及的數據量過大,查詢耗時一般較長,無法給用戶提供實時返回,我們通過提供異步任務功能支持這一需求。
用戶異步任務請求通過 WebSvr 轉發到 QuerySvr,為避免 QuerySvr 宕機導致異步任務丟失,QuerySvr 會將異步任務寫入一致性鎖服務中存儲,空閑的 QuerySvr 會從一致性鎖服務搶鎖,搶鎖成功后執行該異步任務。
QuerySvr 根據異步任務的模塊信息讀取機器列表,按照機器列表并發讀取匹配的日志數據,按順序寫入本機磁盤中,在查詢結束后更新一致性鎖服務狀態(存儲機 ip 和路徑),用戶頁面刷新會拉取到異步任務最新狀態。