關于Java內(nèi)存模型(JMM)的那些事
一、為什么要有內(nèi)存模型
- 在現(xiàn)代多核處理器中,每個處理器都有自己的緩存,需要定期的與主內(nèi)存進行協(xié)調。
- 想要確保每個處理器在任意時刻知道其他處理器正在進行的工作,將需要很大的開銷,且通常是沒必要的。
1.1 硬件的效率與一致性
1、 由于計算機的存儲設備與處理器的運算能力之間有幾個數(shù)量級的差距,所以現(xiàn)代計算機系統(tǒng)都不得不加入一層讀寫速度盡可能接近處理器運算速度的高速緩存(cache)來作為內(nèi)存與處理器之間的緩沖:將運算需要使用到的數(shù)據(jù)復制到緩存中,讓運算能快速進行,當運算結束后再從緩存同步回內(nèi)存之中沒這樣處理器就無需等待緩慢的內(nèi)存讀寫了。
2、多個處理器運算任務都涉及同一塊主存,需要一種協(xié)議可以保障數(shù)據(jù)的一致性,這類協(xié)議有MSI、MESI、MOSI及Dragon Protocol等。Java虛擬機內(nèi)存模型中定義的內(nèi)存訪問操作與硬件的緩存訪問操作是具有可比性的。
3、基于高速緩存的存儲交互很好地解決了處理器與內(nèi)存的速度矛盾,但是引入了一個新的問題:
緩存一致性(Cache Coherence)。在多處理器系統(tǒng)中,每個處理器都有自己的高速緩存,而他們又共享同一主存,下面會介紹這個問題
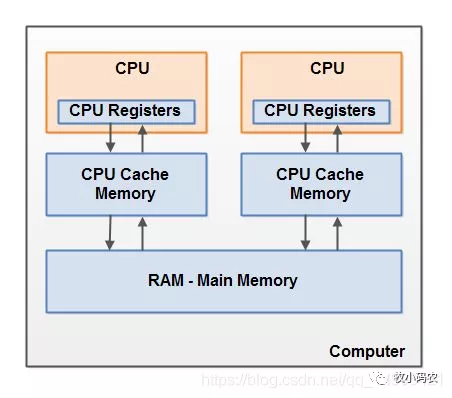
二、CPU和緩存一致性
2.1 為什么需要CPU cache
因為CPU的頻率太快了,快到主存跟不上,這樣在處理器時鐘周期內(nèi),CPU常常需要等待主存,浪費資源。CPU往往需要重復處理相同的數(shù)據(jù)、重復執(zhí)行相同的指令,如果這部分數(shù)據(jù)、指令CPU能在CPU緩存中找到,CPU就不需要從內(nèi)存或硬盤中再讀取數(shù)據(jù)、指令,從而減少了整機的響應時間,所以cache的出現(xiàn),是為了緩解CPU和內(nèi)存之間速度的不匹配問題(結構:cpu -> cache -> memory)
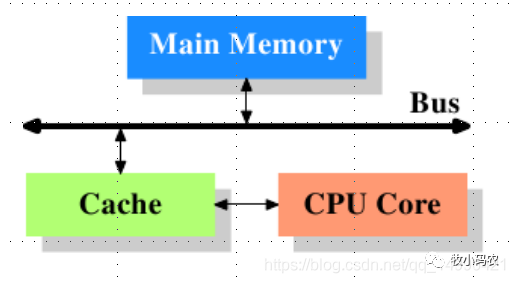
在程序執(zhí)行的過程中就變成了:
當程序在運行過程中,會將運算需要的數(shù)據(jù)從主存復制一份到CPU的高速緩存當中,那么CPU進行計算時就可以直接從它的高速緩存讀取數(shù)據(jù)和向其中寫入數(shù)據(jù),當運算結束之后,再將高速緩存中的數(shù)據(jù)刷新到主存當中。
在Intel官網(wǎng)上產(chǎn)品-處理器界面內(nèi)對緩存的定義為:CPU高速緩存是處理器上的一個快速記憶區(qū)域。英特爾智能高速緩存(SmartCache)是指可讓所有內(nèi)核動態(tài)共享最后一級高速緩存的架構。這里就提及到了最后一級高速緩存的概念,即為CPU緩存中的L3(三級緩存),那么我們繼續(xù)來解釋一下什么叫三級緩存,分別又是指哪三級緩存。
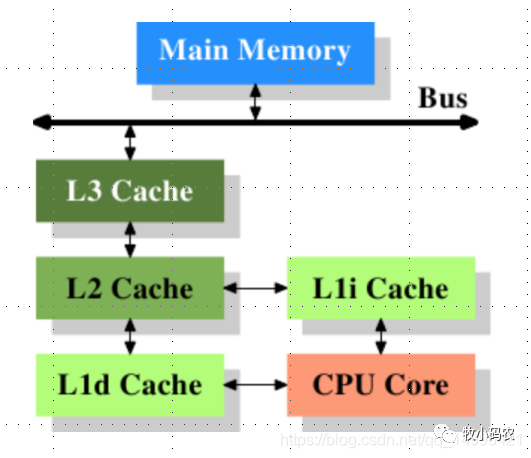
2.2 三級緩存(L1、L2、L3)
1) 三級緩存(L1一級緩存、L2二級緩存、L3三級緩存)都是集成在CPU內(nèi)的緩存 2) 它們的作用都是作為CPU與主內(nèi)存之間的高速數(shù)據(jù)緩沖區(qū) 3) L1最靠近CPU核心,L2其次,L3再次 運行速度方面:L1最快、L2次快、L3最慢
容量大小方面:L1最小、L2較大、L3最大
4) CPU會先在最快的L1中尋找需要的數(shù)據(jù),找不到再去找次快的L2,還找不到再去找L3,L3都沒有那就只能去內(nèi)存找了。
5) 單核CPU只含有一套L1,L2,L3緩存;如果CPU含有多個核心,即多核CPU,則每個核心都含有一套L1(甚至和L2)緩存,而共享L3(或者和L2)緩存。
單CPU雙核的緩存結構:
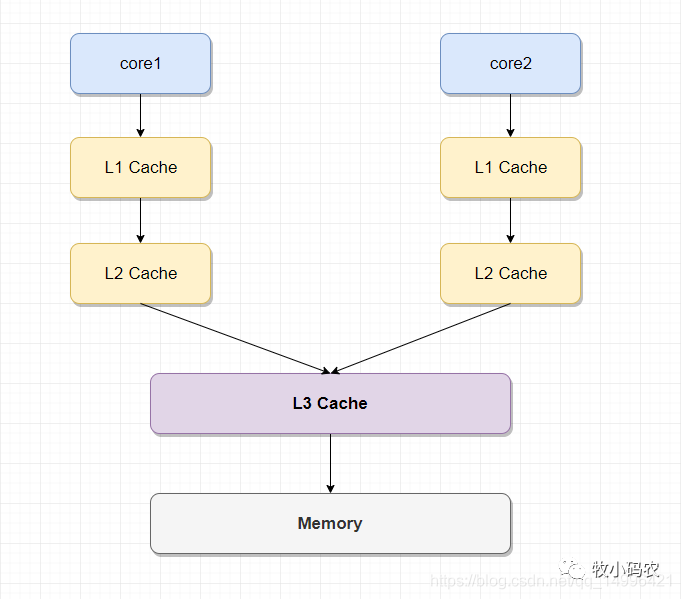
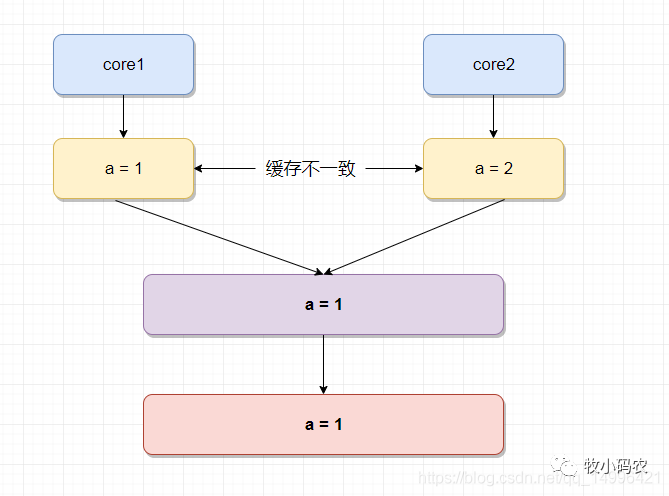
在單線程環(huán)境下,cpu核心的緩存只被一個線程訪問。緩存獨占,不會出現(xiàn)訪問沖突等問題在多線程場景下,在CPU和主存之間增加緩存,就可能存在緩存一致性問題,也就是說,在多核CPU中,每個核的自己的緩存中,關于同一個數(shù)據(jù)的緩存內(nèi)容可能不一致,這也就是我們上面提到的緩存一致性的問題
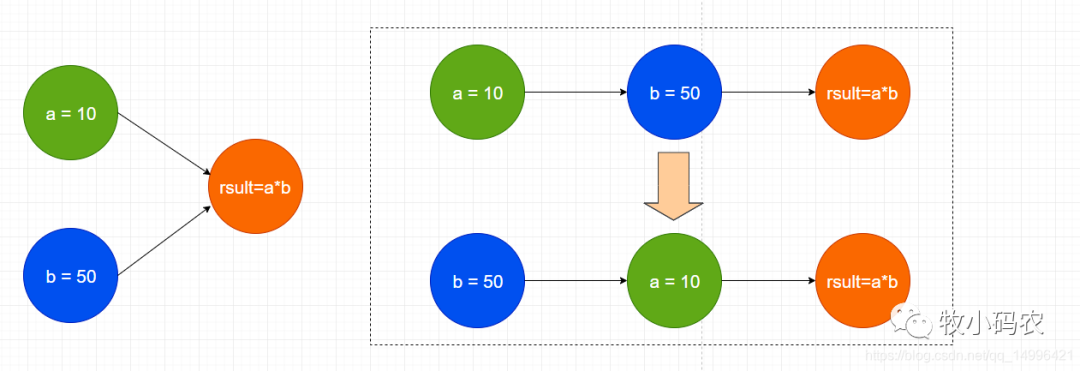
2.3 亂序執(zhí)行優(yōu)化
從java源碼到最終實際執(zhí)行的指令序列,會經(jīng)歷下面3種重排序:

重排序的現(xiàn)象:
- a=10,b=a 這一組 b依賴a,不會重排序
- a=10,b=50 這一組 a和b 沒有關系,那么就有可能被重排序執(zhí)行 b=50,a=10
- cpu和編譯器為了提高程序的執(zhí)行效率會按照一定的規(guī)則允許指令優(yōu)化,不影響單線程程序執(zhí)行結果,但是多線程就會影響程序結果
三、java內(nèi)存模型
Java內(nèi)存模型即Java Memory Model,簡稱JMM。JMM定義了Java 虛擬機(JVM)在計算機內(nèi)存(RAM)中的工作方式。JVM是整個計算機虛擬模型,所以JMM是隸屬于JVM的。
Java內(nèi)存模型(Java Memory Model ,JMM)就是一種符合內(nèi)存模型規(guī)范的,屏蔽了各種硬件和操作系統(tǒng)的訪問差異的,保證了Java程序在各種平臺下對內(nèi)存的訪問都能保證效果一致的機制及規(guī)范。可以避免像c++等直接使用物理硬件和操作系統(tǒng)的內(nèi)存模型在不同操作系統(tǒng)和硬件平臺下表現(xiàn)不同,比如有些c/c++程序可能在windows平臺運行正常,而在linux平臺卻運行有問題。
注意JMM與JVM內(nèi)存區(qū)域劃分的區(qū)別: JMM描述的是一組規(guī)則,圍繞原子性、有序性和可見性展開; 相似點:存在共享區(qū)域和私有區(qū)域
Java線程之間的通信采用的是過共享內(nèi)存模型,這里提到的共享內(nèi)存模型指的就是Java內(nèi)存模型(簡稱JMM),JMM決定一個線程對共享變量的寫入何時對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內(nèi)存之間的抽象關系:線程之間的共享變量存儲在主內(nèi)存(main memory)中,每個線程都有一個私有的本地內(nèi)存(local memory),本地內(nèi)存中存儲了該線程以讀/寫共享變量的副本。本地內(nèi)存是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存,寫緩沖區(qū),寄存器以及其他的硬件和編譯器優(yōu)化。
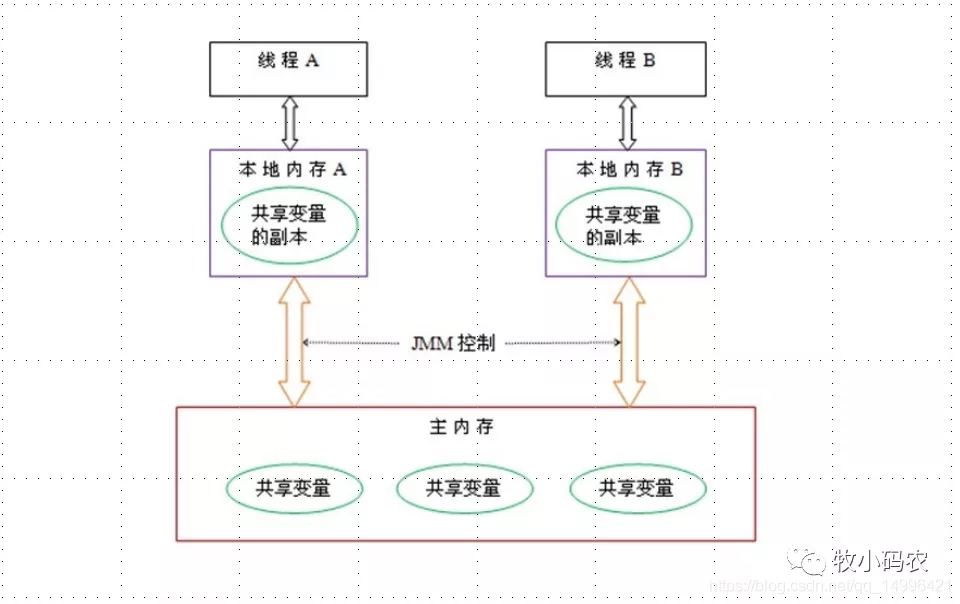
從上圖來看,線程A與線程B之間如要通信的話,必須要經(jīng)歷下面2個步驟:
- 線程A把本地內(nèi)存A中更新過的共享變量刷新到主內(nèi)存中去。
- 線程B到主內(nèi)存中去讀取線程A之前已更新過的共享變量。具體示意圖:
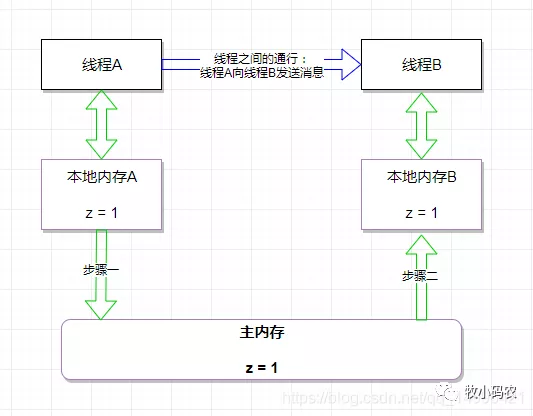
如上圖所示,本地內(nèi)存A和B有主內(nèi)存中共享變量z的副本。假設初始時,這三個內(nèi)存中的z值都為0。線程A在執(zhí)行時,把更新后的z值(假設值為1)臨時存放在自己的本地內(nèi)存A中。當線程A和線程B需要通信時,線程A首先會把自己本地內(nèi)存中修改后的z值刷新到主內(nèi)存中,此時主內(nèi)存中的z值變?yōu)榱?。隨后,線程B到主內(nèi)存中去讀取線程A更新后的z值,此時線程B的本地內(nèi)存的z值也變?yōu)榱?。
從整體來看,這兩個步驟實質上是線程A在向線程B發(fā)送消息,而且這個通信過程必須要經(jīng)過主內(nèi)存。JMM通過控制主內(nèi)存與每個線程的本地內(nèi)存之間的交互,來為java程序員提供內(nèi)存可見性保證。
3.1 JVM對Java內(nèi)存模型的實現(xiàn)
在JVM內(nèi)部,Java 內(nèi)存模型把 Java 虛擬機內(nèi)部劃分為:線程棧和堆
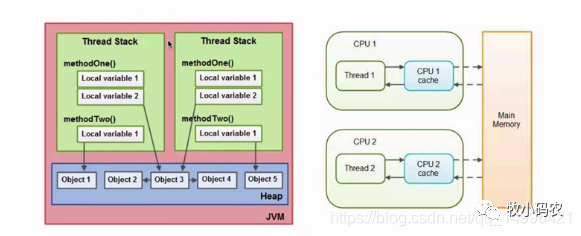
線程棧:
每一個運行在 Java 虛擬機里的線程都擁有自己的線程棧。這個線程棧包含了這個線程調用的方法當前執(zhí)行點相關的信息。一個線程僅能訪問自己的線程棧。一個線程創(chuàng)建的本地變量對其它線程不可見,僅自己可見。即使兩個線程執(zhí)行同樣的代碼,這兩個線程任然在在自己的線程棧中的代碼來創(chuàng)建本地變量。因此,每個線程擁有每個本地變量的獨有版本。
線程堆:
堆上包含在 Java 程序中創(chuàng)建的所有對象,無論是哪一個對象創(chuàng)建的。這包括原始類型的對象版本。如果一個對象被創(chuàng)建然后賦值給一個局部變量,或者用來作為另一個對象的成員變量,這個對象任然是存放在堆上。
- 一個本地變量如果是原始類型,那么它會被完全存儲到棧區(qū)
- 一個本地變量也有可能是一個對象的引用,這種情況下,這個本地引用會被存儲到棧中,但是對象本身仍然存儲在堆區(qū)
- 對于一個對象的成員方法,這些方法中包含本地變量,仍需要存儲在棧區(qū),即使它們所屬的對象在堆區(qū)
- 對于一個對象的成員變量,不管它是原始類型還是包裝類型,都會被存儲到堆區(qū)
- Static類型的變量以及類本身相關信息都會隨著類本身存儲在堆區(qū)
- 堆中的對象可以被多線程共享。如果一個線程獲得一個對象的應用,它便可訪問這個對象的成員變量。如果兩個線程同時調用了同一個對象的同一個方法,那么這兩個線程便可同時訪問這個對象的成員變量,但是對于本地變量,每個線程都會拷貝一份到自己的線程棧中
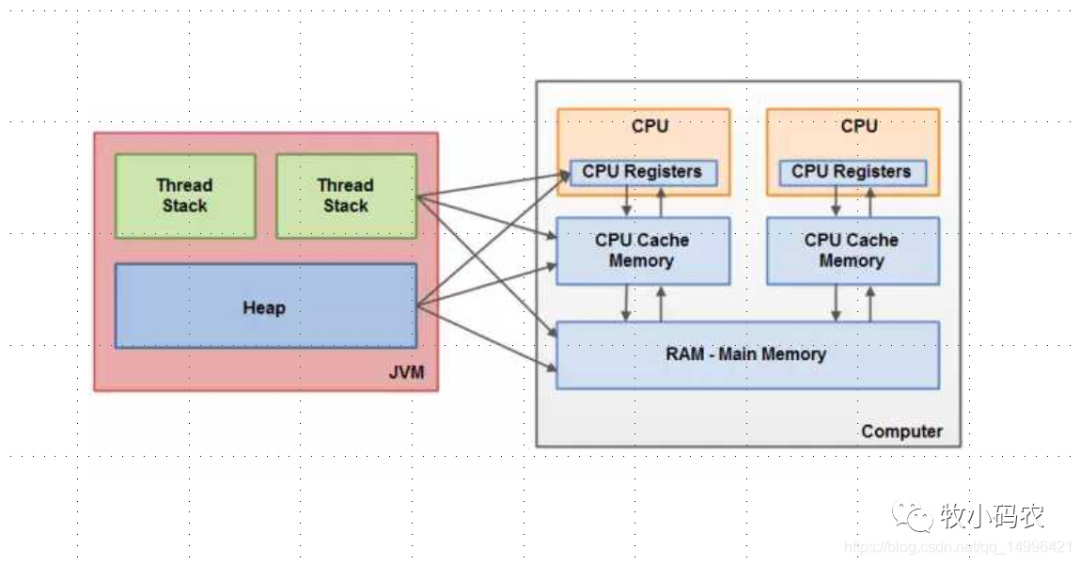
3.2 Java內(nèi)存模型和硬件架構之間的橋接
Java內(nèi)存模型和硬件內(nèi)存架構并不一致。硬件內(nèi)存架構中并沒有區(qū)分棧和堆,從硬件上看,不管是棧還是堆,大部分數(shù)據(jù)都會存到主存中,當然一部分棧和堆的數(shù)據(jù)也有可能會存到CPU寄存器中,如下圖所示,Java內(nèi)存模型和計算機硬件內(nèi)存架構是一個交叉關系:
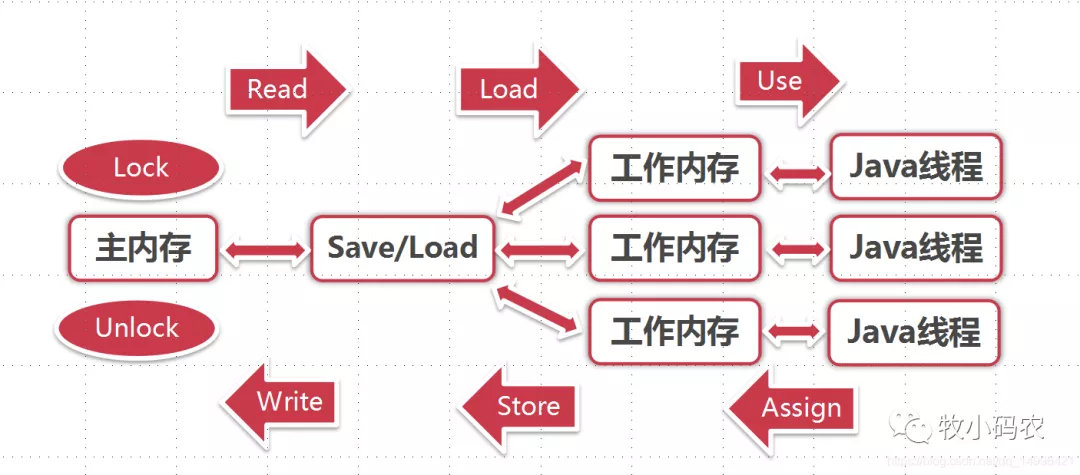
3.3 Java內(nèi)存模型 - 同步八種操作
1) lock(鎖定):作用于主內(nèi)存的變量,把一個變量標識為一條線程獨占狀態(tài)
2) unock(解鎖):作用于主內(nèi)存的變量,把一個處于鎖定狀態(tài)的變量釋放出來,釋放后的變量才可以被其他線程鎖定
3) read(讀取):作用于主內(nèi)存的變量,把一個變量值從主內(nèi)存?zhèn)鬏數(shù)骄€程的工作內(nèi)存中,以便隨后的load動作使用
4) load(載入):作用于工作內(nèi)存的變量,它把read操作從主內(nèi)存中得到的變量值放入工作內(nèi)存的變量副本中
5) use(使用):作用于工作內(nèi)存的變量,把工作內(nèi)存中的一個變量值傳遞給執(zhí)行引擎
6) assign(賦值):作用于工作內(nèi)存的變量,它把一個從執(zhí)行引擎接收到的值賦值給工作內(nèi)存的變量
7) store(存儲):作用于工作內(nèi)存的變量,把工作內(nèi)存中的一個變量的值傳送到內(nèi)存中,以便隨后的write的操作
8) write(寫入):作用于工作內(nèi)存的變量,它把store操作從工作內(nèi)存中一個變量的值傳送到主內(nèi)存的變量中
3.4 Java內(nèi)存模型 - 同步規(guī)則
- 如果要把一個變量從主內(nèi)存中復制到工作內(nèi)存,就需要按順序地執(zhí)行read和load操作,如果把變量從工作內(nèi)存中同步回主內(nèi)存中,就要按順序地執(zhí)行store和write操作。但Java內(nèi)存模型只要求上訴操作必須按順序執(zhí)行,而沒有保證必須是連續(xù)執(zhí)行
- 不允許read和load、store和write操作之一單獨出現(xiàn)
- 不允許一個線程丟棄它的最近assign的操作,即變量在工作內(nèi)存中改變了之后必須同步到主內(nèi)存中
- 不允許一個線程無原因的(沒有發(fā)生過任何assign操作)把數(shù)據(jù)從工作內(nèi)存同步回主內(nèi)存中
- 一個新的變量只能在主內(nèi)存中誕生,不允許在工作內(nèi)存中直接使用一個未被初始化(load或assign)的變量。即就是對一個變量實施use和store操作之前,必須先執(zhí)行過了assign和load操作
- 一個變量在同一時刻只允許一條線程對其進行l(wèi)ock操作,但lock操作可以被同一條線程重復執(zhí)行多次,多次執(zhí)行l(wèi)ock后,只有執(zhí)行相同次數(shù)的unlock操作,變量才會解鎖。lock和unlock必須成對出現(xiàn)
- 如果對一個變量執(zhí)行l(wèi)ock操作,將會清空工作內(nèi)存中此變量的值,在執(zhí)行引擎使用這個變量前需要重新執(zhí)行l(wèi)oad或assign操作初始化變量的值
- 如果一個變量事先沒有被lock操作鎖定,則不允許對它執(zhí)行unlock操作,也不允許去unlock一個被其他線程鎖定的變量
- 對一個變量執(zhí)行unlock操作之前,必須先把此變量同步到主內(nèi)存中(執(zhí)行store和write操作)
原子性、可見性、有序性:可以查看我上一篇文章:線程安全性詳解(原子性、可見性、有序性)
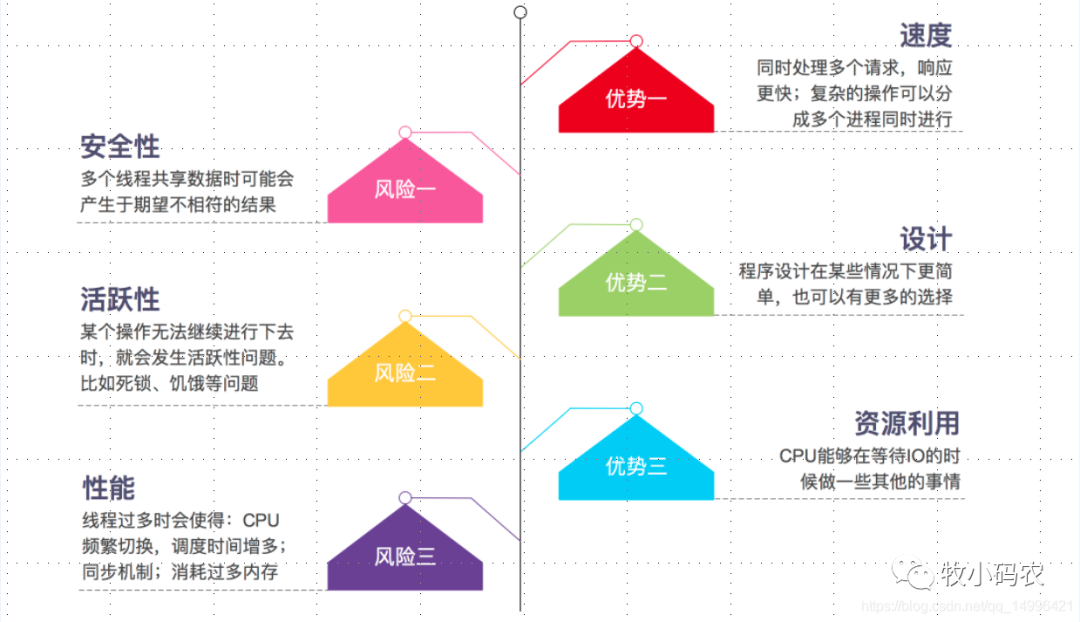
四、并發(fā)的優(yōu)勢與風險
優(yōu)勢:1) 速度:使用處理多個請求,響應更快,復雜的操作可以分成多個進程同時執(zhí)行 2) 設計:程序設計在某些情況下更簡單,也可以有更多的選擇 3) 資源利用:CPU能夠在等待IO的時候做一些其他的事情
風險:1) 安全性:多個線程共享數(shù)據(jù)時可能會產(chǎn)生于期望不相符的結果 2) 活躍性:某個操作無法繼續(xù)進行下去時,就會發(fā)生活躍性問題。比如死鎖、饑餓等問題 3) 性能:線程過多時會使得:CPU頻繁切換,調度時間增多;同步機制;消耗過多內(nèi)存
五、總結
CPU多級緩存:緩存一致性、亂序執(zhí)行優(yōu)化 Java內(nèi)存模型:JMM規(guī)定、抽象結構、同步八種操作及規(guī)則 Java并發(fā)的優(yōu)勢與風險