動態圖上的深度學習-時間圖網絡建模
內容整理自網絡
許多涉及各種性質的交易網絡以及社連接邊動,以及與現實世界問題相關問題都是動態的,可以建模為圖結構,其中節點和邊隨著時間的推移而變化。在這篇文章中,我們描述了時間圖網絡,這是用于在動態圖上進行深度學習建模的通用框架。
圖神經網絡(GNN)相關的研究逐年激增,已成為今年機器學習研究中最熱門的主題之一。GNN最近在生物學,化學,社會科學,物理學等領域的問題上取得了一系列成功。到目前為止,GNN模型主要建模和處理不隨時間變化的靜態網絡。但是,許多現實世界中的圖網絡卻是動態的,并且隨時間變化,典型的例子如社交網絡,金融交易和推薦系統。在許多情況下,正是這種系統的動態行為傳達了重要的信息,否則,如果人們僅考慮靜態圖,則會丟掉這些信息。
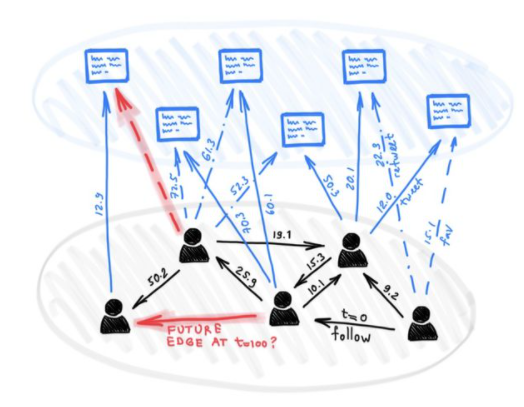
Twitter用戶的動態網絡,與推文進行連接邊并互相關注。所有邊都有時間戳。給定這樣的動態圖,我們希望預測未來的連接邊,例如,用戶將喜歡哪些推文或他們將關注誰。
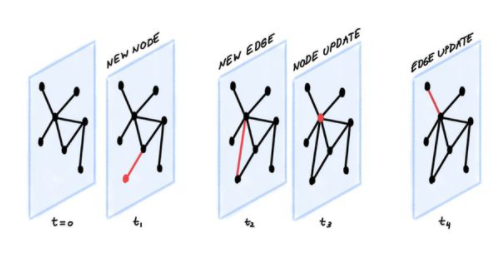
動態圖可以表示為定時事件的有序列表或異步“流”,例如節點和邊的添加或刪除[1]。像Twitter這樣的社交網絡是一個典型的例子:當一個人加入平臺時,會創建一個新節點。當他們關注另一個用戶時,將創建一條新的關注邊。當他們更改配置文件時,將更新該節點。
該事件流由編碼器神經網絡編碼,該編碼器神經網絡為圖的每個節點生成時間相關的embedding。然后可以將embedding的內容饋送到為特定任務設計的解碼器中。比如說,可以通過嘗試回答這么一個問題,來預測未來的連接邊作用,問題是:在時間t處節點i和j之間具有邊的概率是多少?回答此問題的能力對于推薦系統至關重要,例如,給社交網絡用戶推薦什么內容或預測該用戶喜歡關注什么內容。下圖說明了這種情況:
一個TGN編碼器的例子,擁有七條可見邊(時間戳為t?至t?)的動態圖,目的是預測在時間t?(灰色邊)時,節點2和4之間的未來存在連接關系的概率。為此,TGN在時間t1時,計算節點2和4embedding表示。然后將這些embedding連接起來并輸入解碼器(例如MLP),該解碼器輸出存在連接邊的概率。
上述場景中的關鍵部分是編碼器,它可以與任何解碼器同時訓練。在前述的連接邊預測任務上,可以以自監督的方式進行訓練:在每個時期,編碼器均按時間順序處理事件,并根據先前的事件預測下一次連接邊[2]。
時間圖網絡(TGN)是我們在Twitter上與Fabrizio Frasca,Davide Eynard,Ben Chamberlain和Federico Monti等同事共同開發的一種通用編碼器體系結構[3]。該模型可以應用于以事件流表示的動態圖上的各種學習問題。簡而言之,TGN編碼器通過基于節點的連接邊創建節點的壓縮表示并在每次事件發生時時更新它們的表示。為此,TGN具有以下主要組成部分:
Memory單元。Memory存儲所有節點的狀態,充當節點過去連接邊的壓縮表示。它類似于RNN的隱藏狀態。然而,我們對每個節點i用一個獨立的狀態向量si(t)表示。當出現新節點時,我們添加一個初始化為零的新的狀態向量。而且,由于每個節點的Memory只是狀態向量(而不是參數),因此當模型吸收新的連接邊時,也可以在測試時進行更新。
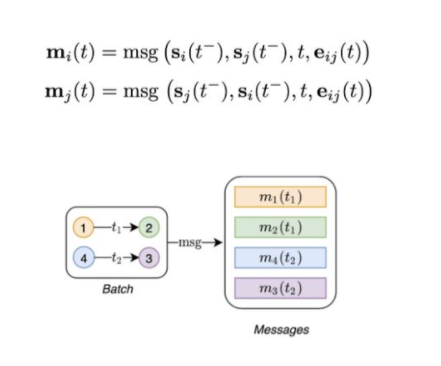
消息功能函數:更新Memory的主要機制。給定節點i和j在時間t的連接邊,消息函數計算兩條消息(一條用于i,一條用于j),用于更新Memory。這類似于在消息傳遞圖神經網絡中計算的消息[4]。該消息是在連接邊之前的時間t?,連接邊時間t和邊緣特征[5] 的情況下節點i和j的Memory的函數:
Memory更新組件:用于使用新消息更新Memory。該模塊通常實現為RNN。
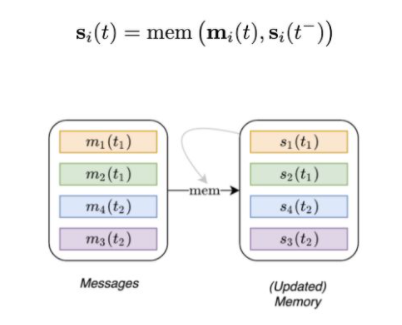
鑒于節點的Memory是隨時間更新的向量,最直接的方法是直接將其用作節點embedding。但是,在實踐中,由于陳舊性(同步更新時間不一致導致的狀態漂移)問題,這并不合適:鑒于僅當節點參與連接邊時才更新Memory,因此節點長時間不活動會導致其Memory過時。舉個例子,想想一個用戶離開Twitter幾個月。當用戶返回時,他們可能已經在此期間產生了新的興趣,因此對他們過去活動的Memory不再重要。因此,我們需要一種更好的方法來計算embedding。
embedding。一種解決方案是查看其節點鄰居。為了解決陳舊性問題,embedding模塊通過在該節點的時空鄰居上執行圖聚合來計算該節點的時間embedding。即使節點已處于非活動狀態一段時間,它的某些鄰居也可能處于活動狀態,并且通過聚合其Memory,TGN可以為該節點計算最新的embedding。在我們的例子中,即使用戶不使用Twitter,他們的朋友仍會保持活動狀態,因此當他們返回時,朋友的最近活動可能比用戶自己的歷史記錄更具相關性。
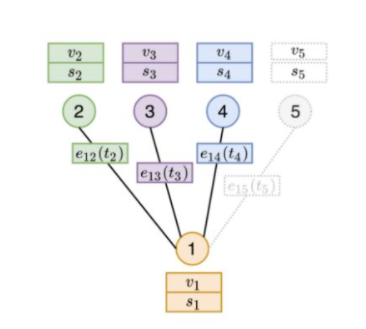
圖embedding模塊通過在其時間鄰域上執行聚合來計算目標節點的embedding。另外,在上述圖中,在某一時間t大于計算節點1的embedding時間節點t?,t?和t? ,但小于t?,時間鄰域將僅包括時間t之前發生的邊。因此,節點5的邊不參與計算,因為將來會發生這種情況。相反,embedding模塊會根據鄰居2、3和4的特征(v)和Memory(s)以及邊上的特征進行聚合,以計算節點1的表示形式。實驗是圖注意力,它能夠根據鄰居的Memory,特征和互動時間來了解哪個鄰居最重要。
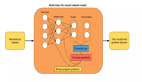
下圖總結了TGN對一批訓練數據執行的總體計算過程:
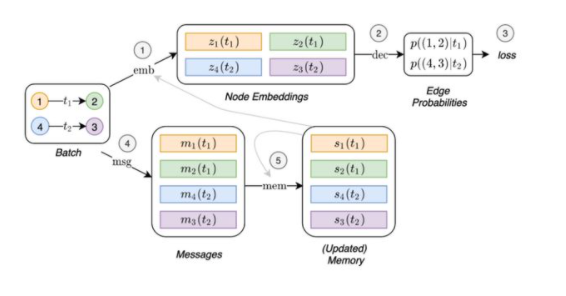
TGN對一批訓練數據執行的計算。一方面,embedding由embedding模塊使用時間圖和節點的Memory(1)生成。然后將embedding用于預測批處理相互作用并計算損失(2、3)。另一方面,這些相同的連接邊也用于更新Memory(4、5)。
通過查看上圖,你可能想知道如何訓練與Memory相關的模塊(消息功能函數,消息聚合器和Memory更新組件),因為它們似乎并不直接影響損失函數,因此不會進行梯度更新。為了使這些模塊能夠影響損失函數,我們需要在預測批處理連接邊之前更新Memory。但是,這將導致泄漏,因為Memory已經包含有關我們要預測的信息。我們提出的解決此問題的策略是使用來自先前的消息來更新Memory批處理,然后預測連接邊。下圖展示了TGN的操作流程,這是訓練與Memory相關的模塊所必需的:
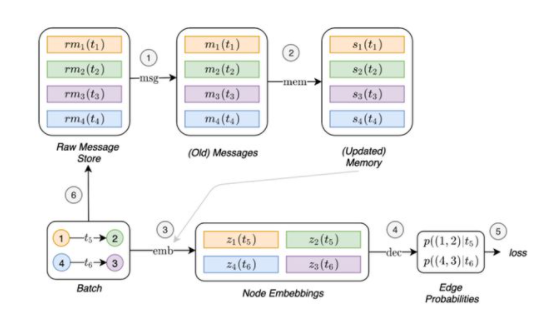
訓練與Memory相關的模塊所需的TGN操作流程。引入了一個新的組件,即原始消息存儲庫,該存儲庫存儲了必要的信息以計算消息(我們稱為原始消息),以處理模型過去處理過的連接邊。這允許模型將連接邊帶來的Memory更新延遲到以后的batch數據。首先,使用從先前batch數據(1和2)中存儲的原始消息計算出的消息來更新Memory。然后可以使用剛更新的Memory(灰色連接邊)來計算embedding(3)。這樣,與Memory相關的模塊的計算將直接影響損失函數(4、5),并且它們會收到一個梯度。最后,此批處理連接邊的原始消息存儲在原始消息存儲庫(6)中,以供將來的batch數據使用。
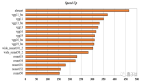
在各種動態圖上進行了廣泛的實驗驗證后,在精度和速度方面,TGN在鏈接預測和動態節點分類的任務上明顯優于競爭方法[6]。一種這樣的動態圖是Wikipedia,其中用戶和頁面是節點,并且連接邊表示用戶正在編輯頁面。編輯文本的編碼用作連接邊功能。在這種情況下,任務是預測用戶將在給定時間編輯哪個頁面。我們將TGN的不同變體與基準方法進行了比較:
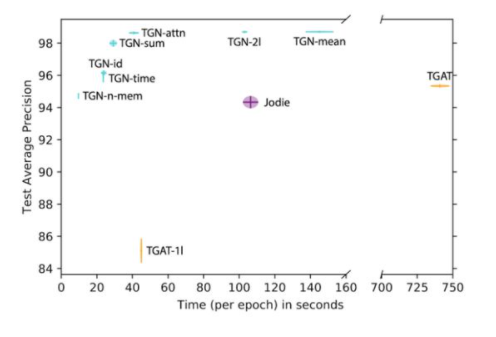
在預測準確性和時間方面,比較Wikipedia數據集上TGN的各種配置和已有的方法(TGAT和Jodie)對將來在Wikipedia數據集上的連接邊進行預測。我們希望有更多的論文嚴格地報告這兩個重要標準。
該拆分研究證明不同TGN模塊的重要性,并使我們可以得出一些一般性結論。首先,Memory很重要:Memory的缺乏會導致性能大幅下降[7]。其次,embedding模塊的使用(與直接輸出Memory狀態相反)很重要。基于圖注意力的embedding似乎表現最佳。第三,擁有Memory使得僅使用一個圖關注層就足夠了(這大大減少了計算時間),因為1跳鄰居的Memory使模型可以間接訪問2跳鄰居信息。
最后,我們認為在動態圖上學習是一個幾乎原始的研究領域,具有許多重要應用場景,并且具有巨大的潛在影響。我們認為,我們的TGN模型是提高動態圖學習能力的重要一步,以鞏固和擴展先前的結果。隨著這一研究領域的發展,更好,更大的基準將變得至關重要。現在,我們正在努力創建新的動態圖數據集和任務,作為“ 開放圖基準”的一部分。