













字典樹,不就有點(diǎn)不一樣的一顆樹
本文轉(zhuǎn)載自微信公眾號(hào)「bigsai」,作者bigsai。轉(zhuǎn)載本文請(qǐng)聯(lián)系bigsai公眾號(hào)。
什么是字典樹
字典樹,是一種空間換時(shí)間的數(shù)據(jù)結(jié)構(gòu),又稱Trie樹、前綴樹,是一種樹形結(jié)構(gòu)(字典樹是一種數(shù)據(jù)結(jié)構(gòu)),典型用于統(tǒng)計(jì)、排序、和保存大量字符串。所以經(jīng)常被搜索引擎系統(tǒng)用于文本詞頻統(tǒng)計(jì)。它的優(yōu)點(diǎn)是:利用字符串的公共前綴來減少查詢時(shí)間,最大限度地減少無謂的字符串比較,查詢效率比哈希樹高。
可能大部分情況你很難直觀或者有接觸的體驗(yàn),可能對(duì)前綴這個(gè)玩意沒啥概念,可能做題遇到前綴問題也是暴力匹配蒙混過關(guān),如果字符串比較少使用哈希表等結(jié)構(gòu)可能也能蒙混過關(guān),但如果字符串比較長(zhǎng)、相同前綴較多那么使用字典樹可以大大減少內(nèi)存的使用和效率。一個(gè)字典樹的應(yīng)用場(chǎng)景:在搜索框輸入部分單詞下面會(huì)有一些神關(guān)聯(lián)的搜索內(nèi)容,你有時(shí)候都很神奇是怎么做到的,這其實(shí)就是字典樹的一個(gè)思想。

圖片真假可自行驗(yàn)證
對(duì)于字典樹,有三個(gè)重要性質(zhì):
1:根節(jié)點(diǎn)不包含字符,除了根節(jié)點(diǎn)每個(gè)節(jié)點(diǎn)都只包含一個(gè)字符。root節(jié)點(diǎn)不含字符這樣做的目的是為了能夠包括所有字符串。
2:從根節(jié)點(diǎn)到某一個(gè)節(jié)點(diǎn),路過字符串起來就是該節(jié)點(diǎn)對(duì)應(yīng)的字符串。
3:每個(gè)節(jié)點(diǎn)的子節(jié)點(diǎn)字符不同,也就是找到對(duì)應(yīng)單詞、字符是唯一的。
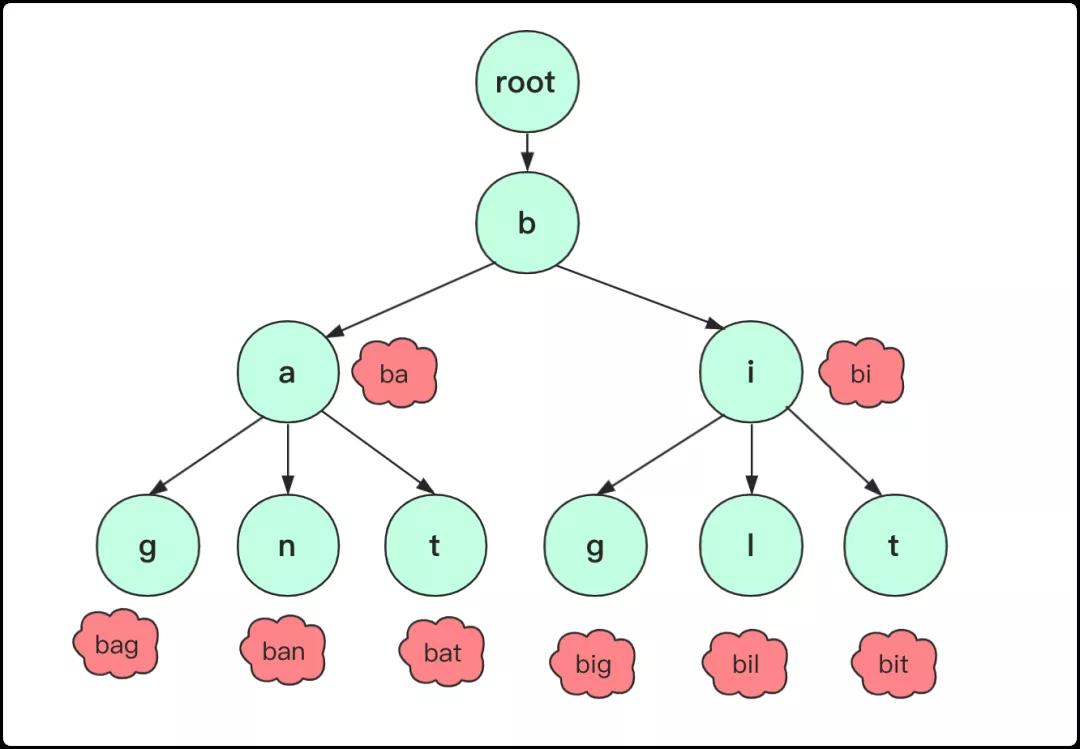
一個(gè)字典樹
設(shè)計(jì)實(shí)現(xiàn)字典樹
上面已經(jīng)介紹了什么是字典樹,那么我們開始設(shè)計(jì)一個(gè)字典樹吧!
對(duì)于字典樹,可能不同的場(chǎng)景或者需求設(shè)計(jì)上有一些細(xì)致的區(qū)別,但整體來說一般的字典樹有插入、查詢(指定字符串)、查詢(前綴)。
我們首先來分析一下簡(jiǎn)單情況吧,就是字符串中全部是26個(gè)小寫字母,剛好力扣208實(shí)現(xiàn)Trie樹可以作為一個(gè)實(shí)現(xiàn)的模板。
實(shí)現(xiàn) Trie 類:
- Trie() 初始化前綴樹對(duì)象。
- void insert(String word) 向前綴樹中插入字符串 word 。
- boolean search(String word) 如果字符串 word 在前綴樹中,返回 true(即,在檢索之前已經(jīng)插入);否則,返回 false 。
- boolean startsWith(String prefix) 如果之前已經(jīng)插入的字符串 word 的前綴之一為 prefix ,返回 true ;否則,返回 false 。
怎么設(shè)計(jì)這個(gè)字典樹呢?
對(duì)于一個(gè)字典樹Trie類,肯定是要有一個(gè)根節(jié)點(diǎn)root的,而這個(gè)節(jié)點(diǎn)類型TrieNode也有很多設(shè)計(jì)方式,在這里我們?yōu)榱撕?jiǎn)單放一個(gè)26個(gè)大小的TrieNode類型數(shù)組,分別對(duì)應(yīng)'a'-'z'的字符,同時(shí)用一個(gè)boolean類型變量isEnd表示是否為字符串末尾結(jié)束(如果為true說明)。
- class TrieNode {
- TrieNode son[];
- boolean isEnd;//結(jié)束標(biāo)志
- public TrieNode()//初始化
- {
- son=new TrieNode[26];
- }
- }
用數(shù)組的話如果字符比較多的話可能會(huì)消耗一些內(nèi)存空間,但是這里26個(gè)連續(xù)字符還好的,如果向一個(gè)字典樹中添加big,bit,bz 那么它其實(shí)是這樣的:
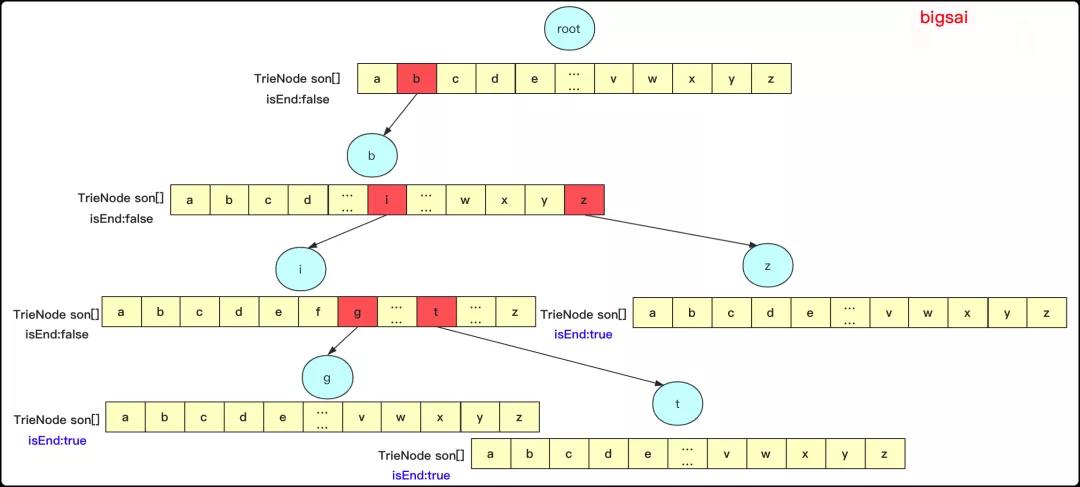
那么再分析一下具體操作:
插入操作:遍歷字符串,同時(shí)從字典樹root節(jié)點(diǎn)開始遍歷,找到每個(gè)字符對(duì)應(yīng)的位置首先判斷是否為空,如果為空需要?jiǎng)?chuàng)建一個(gè)新的Trie。比如插入big的枚舉第一個(gè)b時(shí)候創(chuàng)建TrieNode,后面也是同理。不過重要的是要在停止的那個(gè)TrieNode將isEnd設(shè)為true表明這個(gè)節(jié)點(diǎn)是構(gòu)成字符串的末尾節(jié)點(diǎn)。
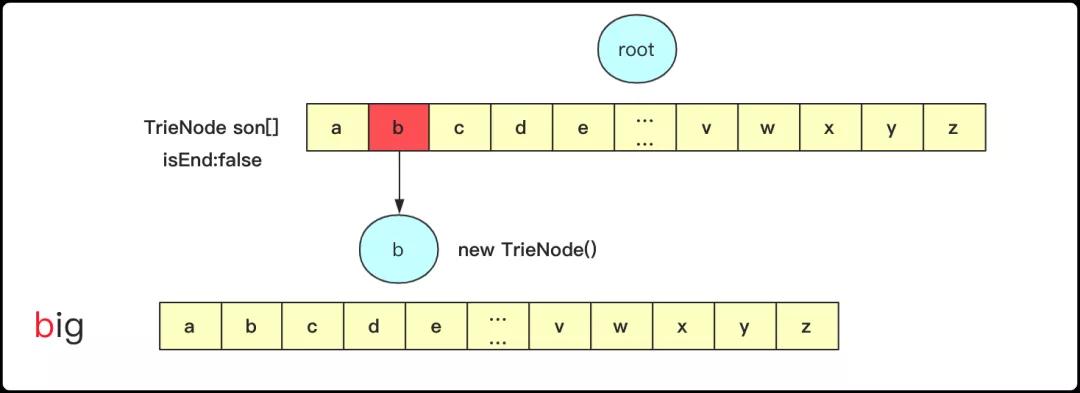
這部分對(duì)應(yīng)的關(guān)鍵代碼為:
- TrieNode root;
- /** 初始化 */
- public Trie() {
- root=new TrieNode();
- }
- /** Inserts a word into the trie. */
- public void insert(String word) {
- TrieNode node=root;//臨時(shí)節(jié)點(diǎn)用來枚舉
- for(int i=0;i<word.length();i++)//枚舉字符串
- {
- int index=word.charAt(i)-'a';//找到26個(gè)對(duì)應(yīng)位置
- if(node.son[index]==null)//如果為空需要?jiǎng)?chuàng)建
- {
- node.son[index]=new TrieNode();
- }
- node=node.son[index];
- }
- node.isEnd=true;//最后一個(gè)節(jié)點(diǎn)
- }
查詢操作:查詢是建立在字典樹已經(jīng)建好的情況下,這個(gè)過程和查詢有些類似但不需要?jiǎng)?chuàng)建TrieNode,如果枚舉的過程一旦發(fā)現(xiàn)該TrieNode未被初始化(即為空)則返回false,如果順利到最后看看該節(jié)點(diǎn)的isEnd是否為true(是否已插入已改字符結(jié)尾的字符串),如果為true則返回true。
這里用一個(gè)例子可能更好懂。插入big串,如果查找ba會(huì)因?yàn)榈诙蝍對(duì)應(yīng)TrieNode為null為為空。如果查找bi也會(huì)返回失敗,因?yàn)橹安迦氲腷ig只在g字符對(duì)應(yīng)TrieNode標(biāo)識(shí)isEnd=true,但i字符下面的isEnd為false,即不存在bi字符串。
該部分對(duì)應(yīng)的核心代碼為:
- public boolean search(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- int index=word.charAt(i)-'a';
- if(node.son[index]==null)//為null直接返回false
- {
- return false;
- }
- node=node.son[index];
- }
- return node.isEnd==true;
- }
前綴查找:和查詢很相似但是有點(diǎn)區(qū)別,查找失敗的話返回false,但是如果能進(jìn)行到最后一步那么返回true。上面例子插入big查找bi同樣返回true,因?yàn)榇嬖谝运鼮榍熬Y的字符串。
該對(duì)應(yīng)對(duì)應(yīng)的核心代碼為:
- public boolean startsWith(String prefix) {
- TrieNode node=root;
- for(int i=0;i<prefix.length();i++)
- {
- int index=prefix.charAt(i)-'a';
- if(node.son[index]==null)
- {
- return false;
- }
- node=node.son[index];
- }
- //能執(zhí)行到最后即返回true
- return true;
- }
上面代碼合在一起就是完整的字典樹了,最基礎(chǔ)的版本。完整版為:
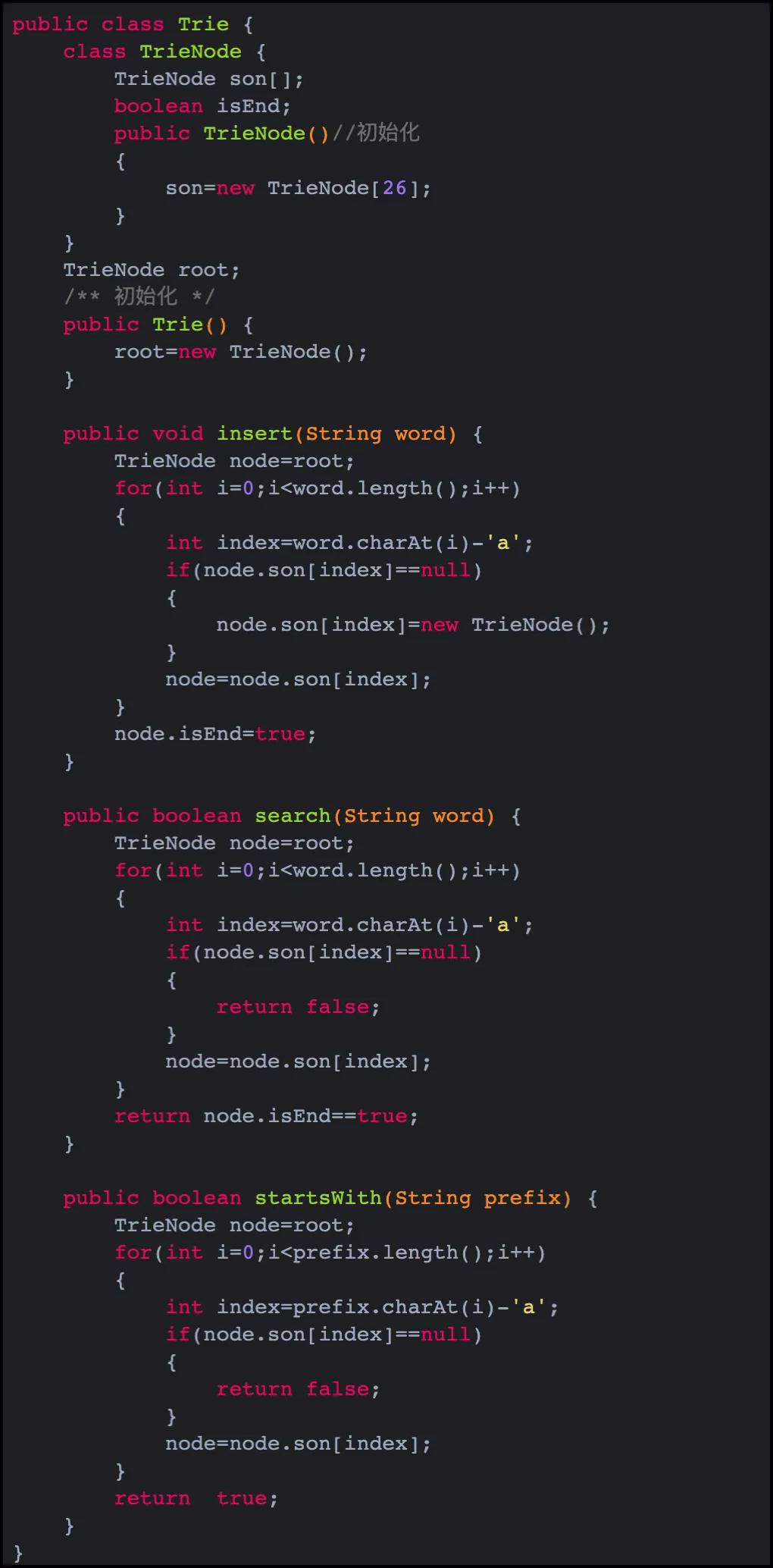
代碼
字典樹小思考
字典樹基礎(chǔ)班很容易,但很可能會(huì)出現(xiàn)一些延伸。
對(duì)于上面是26個(gè)字符的,我們很容易用ASCII找到對(duì)應(yīng)索引,如果字符可能性比較多,用數(shù)組可能浪費(fèi)的空間比較大,那我們也可以用HashMap或者List來存儲(chǔ)元素啊,用List的話就需要順序枚舉,用HashMap就可以直接查詢,這里就講解一個(gè)使用HashMap()實(shí)現(xiàn)的字典樹。
使用HashMap替代數(shù)組(不過使用哈希就不自帶排序功能了),其實(shí)邏輯是一樣的,只需要判斷時(shí)候用HashMap判斷是否存在對(duì)應(yīng)的key即可,HashMap的類型為:
Map
使用HashMap實(shí)現(xiàn)的字典樹完整代碼為:
- import java.util.HashMap;
- import java.util.Map;
- public class Trie{
- class TrieNode{
- Map<Character,TrieNode> sonMap;
- boolean idEnd;
- public TrieNode()
- {
- sonMap=new HashMap<>();
- }
- }
- TrieNode root;
- public Trie()
- {
- root=new TrieNode();
- }
- public void insert(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- char ch=word.charAt(i);
- if(!node.sonMap.containsKey(ch))//不存在插入
- {
- node.sonMap.put(ch,new TrieNode());
- }
- node=node.sonMap.get(ch);
- }
- node.idEnd=true;
- }
- public boolean search(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- char ch=word.charAt(i);
- if(!node.sonMap.containsKey(ch))
- {
- return false;
- }
- node=node.sonMap.get(ch);
- }
- return node.idEnd==true;//必須標(biāo)記為true證明有該字符串
- }
- public boolean startsWith(String prefix) {
- TrieNode node=root;
- for(int i=0;i<prefix.length();i++)
- {
- char ch=prefix.charAt(i);
- if(!node.sonMap.containsKey(ch))
- {
- return false;
- }
- node=node.sonMap.get(ch);
- }
- return true;//執(zhí)行到最后一步即可
- }
- }
前面講了,字典樹用于大量字符的統(tǒng)計(jì)、排序、儲(chǔ)存,其實(shí)排序就是和采用數(shù)組的方式可以進(jìn)行排序,因?yàn)樽址腁SCII有序,在讀取時(shí)候可以按照這個(gè)規(guī)則讀取,這個(gè)思想就和基數(shù)排序有點(diǎn)像了。
而統(tǒng)計(jì)的話可能會(huì)面臨數(shù)量上統(tǒng)計(jì),可能是出現(xiàn)過次數(shù)或者前綴單詞數(shù)量統(tǒng)計(jì),如果每次都枚舉可能有點(diǎn)浪費(fèi)時(shí)間,但你可以TrieNode中添加一個(gè)變量,每次插入的時(shí)候可以統(tǒng)計(jì)次數(shù)。如果字符串有重復(fù)那可以直接添加,如果字符串要去重那可以確定插入成功再給路徑上前綴單詞總數(shù)分別自增。這個(gè)的話就要具體問題具體分析了。
此外,字典樹還有一個(gè)在ACM中用于解決求異或最值的問題,我們稱之為:01字典樹,大家感興趣也可以自行了解(后面可能會(huì)介紹)。
總結(jié)
通過本文,想必你對(duì)字典樹有了一個(gè)較好的認(rèn)識(shí),本篇的話目的還是在于讓讀者能夠認(rèn)識(shí)和學(xué)會(huì)基礎(chǔ)的字典樹,對(duì)其它變形優(yōu)化能有個(gè)初步的認(rèn)識(shí)。
字典樹可以最大限度地減少無謂的字符串比較,用于詞頻統(tǒng)計(jì)和大量字符串排序。自帶排序功能,使用中序遍歷序列即可得到排序序列。但是如果字符很多相同前綴很少的話那字典樹就沒啥效率優(yōu)勢(shì)的(因?yàn)橐粋€(gè)一個(gè)訪問節(jié)點(diǎn))。
字典樹的真實(shí)應(yīng)用有很多,例如字符串檢索、文本預(yù)測(cè)、自動(dòng)完成,see also,拼寫檢查、詞頻統(tǒng)計(jì)、排序、字符串最長(zhǎng)公共前綴、字符串搜索的前綴匹配、作為其他數(shù)據(jù)結(jié)構(gòu)和算法的輔助結(jié)構(gòu)等等,這里就不再介紹啦。













