Flink 在唯品會的實踐
唯品會自 2017 年開始基于 k8s 深入打造高性能、穩(wěn)定、可靠、易用的實時計算平臺,支持唯品會內(nèi)部業(yè)務(wù)在平時以及大促的平穩(wěn)運行。現(xiàn)平臺支持 Flink、Spark、Storm 等主流框架。本文主要分享 Flink 的容器化實踐應(yīng)用以及產(chǎn)品化經(jīng)驗。內(nèi)容包括:1.發(fā)展概覽2.Flink 容器化實踐3.Flink SQL 平臺化建設(shè)4.應(yīng)用案例5.未來規(guī)劃
一 、發(fā)展概覽
平臺支持公司內(nèi)部所有部門的實時計算應(yīng)用。主要的業(yè)務(wù)包括實時大屏、推薦、實驗平臺、實時監(jiān)控和實時數(shù)據(jù)清洗等。
1.1 集群規(guī)模

平臺現(xiàn)有異地雙機房雙集群,具有 2000 多的物理機節(jié)點,利用 k8s 的 namespaces,labels 和 taints 等,實現(xiàn)業(yè)務(wù)隔離以及初步的計算負載隔離。目前線上實時應(yīng)用有大概 1000 個,平臺最近主要支持 Flink SQL 任務(wù)的上線。
1.2 平臺架構(gòu)
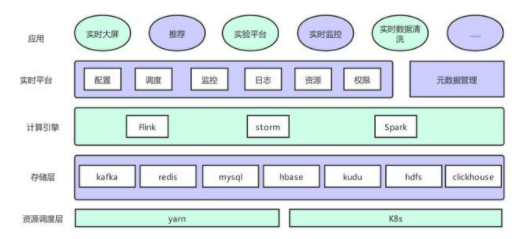
上圖是唯品會實時計算平臺的整體架構(gòu)。最底層是計算任務(wù)節(jié)點的資源調(diào)度層,實際是以 deployment 的模式運行在 k8s 上,平臺雖然支持 yarn 調(diào)度,但是 yarn 調(diào)度是與批任務(wù)共享資源,所以主流任務(wù)還是運行在 k8s 上。存儲層這一層,支持公司內(nèi)部基于 kafka 實時數(shù)據(jù) vms,基于 binlog 的 vdp 數(shù)據(jù)和原生 kafka 作為消息總線,狀態(tài)存儲在 hdfs 上,數(shù)據(jù)主要存入 redis,mysql,hbase,kudu,clickhouse 等。計算引擎層,平臺支持 Flink,Spark,Storm 主流框架容器化,提供了一些框架的封裝和組件等。每個框架會都會支持幾個版本的鏡像滿足不同的業(yè)務(wù)需求。平臺層提供作業(yè)配置、調(diào)度、版本管理、容器監(jiān)控、job 監(jiān)控、告警、日志等功能,提供多租戶的資源管理(quota,label 管理),提供 kafka 監(jiān)控。在 Flink 1.11 版本之前,平臺自建元數(shù)據(jù)管理系統(tǒng)為 Flink SQL 管理 schema,1.11 版本開始,通過 hive metastore 與公司元數(shù)據(jù)管理系統(tǒng)融合。
最上層就是各個業(yè)務(wù)的應(yīng)用層。
二、Flink 容器化實踐
2.1 容器化實踐
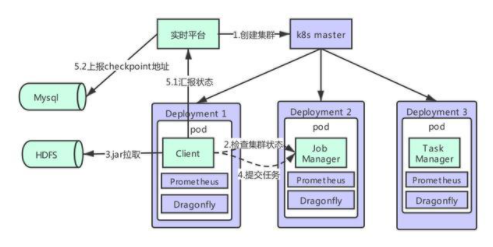
上圖是實時平臺 Flink 容器化的架構(gòu)。Flink 容器化是基于 standalone 模式部署的。
部署模式共有 client,jobmanager 和 taskmanager 三個角色,每一個角色都由一個 deployment 控制。用戶通過平臺上傳任務(wù) jar 包,配置等,存儲于 hdfs 上。同時由平臺維護的配置,依賴等也存儲在 hdfs 上,當(dāng) pod 啟動時,會進行拉取等初始化操作。client 中主進程是一個由 go 開發(fā)的 agent,當(dāng) client 啟動時,會首先檢查集群狀態(tài),當(dāng)集群 ready 后,從 hdfs 上拉取 jar 包向 Flink 集群提交任務(wù)。同時,client 的主要功能還有監(jiān)控任務(wù)狀態(tài),做 savepoint 等操作。通過部署在每臺物理機上的 smart - agent 采集容器的指標(biāo)寫入 m3,以及通過 Flink 暴漏的接口將 metrics 寫入 prometheus,結(jié)合 grafana 展示。同樣通過部署在每臺物理機上的 vfilebeat 采集掛載出來的相關(guān)日志寫入 es,在 dragonfly 可以實現(xiàn)日志檢索。
Flink 平臺化
在實踐過程中,結(jié)合具體場景以及易用性考慮,做了平臺化工作。
平臺的任務(wù)配置與鏡像,F(xiàn)link 配置,自定義組件等解耦合,現(xiàn)階段平臺支持 1.7、1.9、1.11、1.12 等版本。平臺支持流水線編譯或上傳 jar、作業(yè)配置、告警配置、生命周期管理等,從而減少用戶的開發(fā)成本。平臺開發(fā)了容器級別的如火焰圖等調(diào)優(yōu)診斷的頁面化功能,以及登陸容器的功能,支持用戶進行作業(yè)診斷。
Flink 穩(wěn)定性
在應(yīng)用部署和運行過程中,不可避免的會出現(xiàn)異常。以下是平臺保證任務(wù)在出現(xiàn)異常狀況后的穩(wěn)定性做的策略。
pod 的健康和可用,由 livenessProbe 和 readinessProbe 檢測,同時指定 pod 的重啟策略。Flink 任務(wù)異常時:1.Flink 原生的 restart 策略和 failover 機制,作為第一層的保證。2.在 client 中會定時監(jiān)控 Flink 狀態(tài),同時將最新的 checkpoint 地址更新到自己的緩存中,并匯報到平臺,固化到 MySQL 中。當(dāng) Flink 無法再重啟時,由 client 重新從最新的成功 checkpoint 提交任務(wù)。作為第二層保證。這一層將 checkpoint 固化到 MySQL 中后,就不再使用 Flink HA 機制了,少了 zk 的組件依賴。3.當(dāng)前兩層無法重啟時或集群出現(xiàn)異常時,由平臺自動從固化到 MySQL 中的最新 chekcpoint 重新拉起一個集群,提交任務(wù),作為第三層保證。機房容災(zāi):用戶的 jar 包,checkpoint 都做了異地雙 HDFS 存儲異地雙機房雙集群
2.2 kafka 監(jiān)控方案
kafka 監(jiān)控是我們的任務(wù)監(jiān)控里相對重要的一部分,整體監(jiān)控流程如下所示
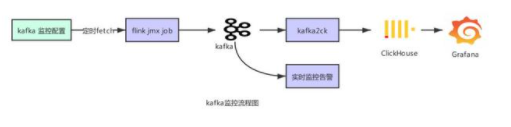
平臺提供監(jiān)控 kafka 堆積,消費 message 等配置信息,從 MySQL 中將用戶 kafka 監(jiān)控配置提取后,通過 jmx 監(jiān)控 kafka,寫入下游 kafka,再通過另一個 Flink 任務(wù)實時監(jiān)控,同時將這些數(shù)據(jù)寫入 ck,從而展示給用戶。
三、Flink SQL 平臺化建設(shè)
基于 k8s 的 Flink 容器化實現(xiàn)以后,方便了 Flink api 應(yīng)用的發(fā)布,但是對于 Flink SQL 的任務(wù)仍然不夠便捷。于是平臺提供了更加方便的在線編輯發(fā)布、SQL 管理等一棧式開發(fā)平臺。
3.1 Flink SQL 方案
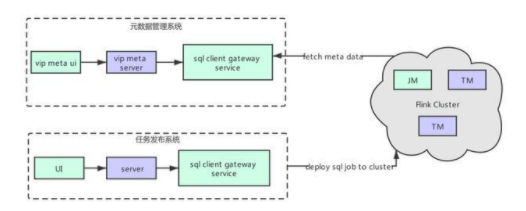
平臺的 Flink SQL 方案如上圖所示,任務(wù)發(fā)布系統(tǒng)與元數(shù)據(jù)管理系統(tǒng)完全解耦。
Flink SQL 任務(wù)發(fā)布平臺化
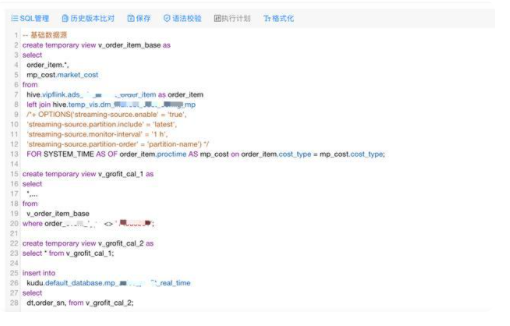
在實踐過程中,結(jié)合易用性考慮,做了平臺化工作,主操作界面如下圖所示:
Flink SQL 的版本管理,語法校驗,拓撲圖管理等;UDF 通用和任務(wù)級別的管理,支持用戶自定義 UDF;提供參數(shù)化的配置界面,方便用戶上線任務(wù)。
元數(shù)據(jù)管理
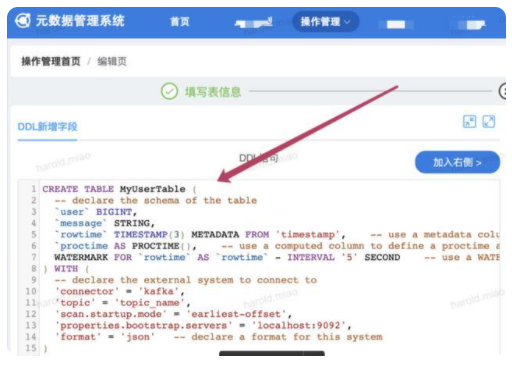
平臺在 1.11 之前通過構(gòu)建自己的元數(shù)據(jù)管理系統(tǒng) UDM,MySQL 存儲 kafka,redis 等 schema,通過自定義 catalog 打通 Flink 與 UDM,從而實現(xiàn)元數(shù)據(jù)管理。1.11 之后,F(xiàn)link 集成 hive 逐漸完善,平臺重構(gòu)了 FlinkSQL 框架,通過部署一個 SQL - gateway service 服務(wù),中間調(diào)用自己維護的 SQL - client jar 包,從而與離線元數(shù)據(jù)打通,實現(xiàn)了實時離線元數(shù)據(jù)統(tǒng)一,為之后的流批一體做好工作。在元數(shù)據(jù)管理系統(tǒng)創(chuàng)建的 Flink 表操作界面如下所示,創(chuàng)建 Flink 表的元數(shù)據(jù),持久化到 hive里,F(xiàn)link SQL 啟動時從 hive 里讀取對應(yīng)表的 table schema 信息。
3.2 Flink SQL 相關(guān)實踐
平臺對于官方原生支持或者不支持的 connector 進行整合和開發(fā),鏡像和 connector,format 等相關(guān)依賴進行解耦,可以快捷的進行更新與迭代。
FLINK SQL 相關(guān)實踐

connector 層,現(xiàn)階段平臺支持官方支持的 connector,并且構(gòu)建了 redis,kudu,clickhouse,vms,vdp 等平臺內(nèi)部的 connector。平臺構(gòu)建了內(nèi)部的 pb format,支持 protobuf 實時清洗數(shù)據(jù)的讀取。平臺構(gòu)建了 kudu,vdp 等內(nèi)部 catalog,支持直接讀取相關(guān)的 schema,不用再創(chuàng)建 ddl。平臺層主要是在 UDF、常用運行參數(shù)調(diào)整、以及升級 hadoop3。runntime 層主要是支持拓撲圖執(zhí)行計劃修改、維表關(guān)聯(lián) keyBy cache 優(yōu)化等
拓撲圖執(zhí)行計劃修改
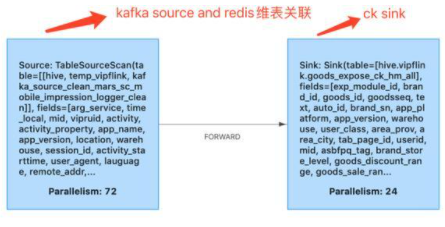
針對現(xiàn)階段 SQL 生成的 stream graph 并行度無法修改等問題,平臺提供可修改的拓撲預(yù)覽修改相關(guān)參數(shù)。平臺會將解析后的 FlinkSQL 的 excution plan json 提供給用戶,利用 uid 保證算子的唯一性,修改每個算子的并行度,chain 策略等,也為用戶解決反壓問題提供方法。例如針對 clickhouse sink 小并發(fā)大批次的場景,我們支持修改 clickhouse sink 并行度,source 并行度 = 72,sink 并行度 = 24,提高 clickhouse sink tps。
維表關(guān)聯(lián) keyBy 優(yōu)化 cache
針對維表關(guān)聯(lián)的情況,為了降低 IO 請求次數(shù),降低維表數(shù)據(jù)庫讀壓力,從而降低延遲,提高吞吐,有以下幾種措施:
當(dāng)維表數(shù)據(jù)量不大時,通過全量維表數(shù)據(jù)緩存在本地,同時 ttl 控制緩存刷新的時候,這可以極大的降低 IO 請求次數(shù),但會要求更多的內(nèi)存空間。當(dāng)維表數(shù)據(jù)量很大時,通過 async 和 LRU cache 策略,同時 ttl 和 size 來控制緩存數(shù)據(jù)的失效時間和緩存大小,可以提高吞吐率并降低數(shù)據(jù)庫的讀壓力。當(dāng)維表數(shù)據(jù)量很大同時主流 qps 很高時,可以開啟把維表 join 的 key 作為 hash 的條件,將數(shù)據(jù)進行分區(qū),即在 calc 節(jié)點的分區(qū)策略是 hash,這樣下游算子的 subtask 的維表數(shù)據(jù)是獨立的,不僅可以提高命中率,也可降低內(nèi)存使用空間。
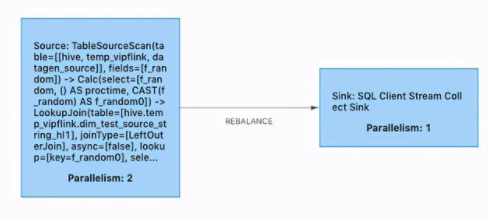
優(yōu)化之前維表關(guān)聯(lián) LookupJoin 算子和正常算子 chain 在一起。

優(yōu)化之間維表關(guān)聯(lián) LookupJoin 算子和正常算子不 chain 在一起,將 join key 作為 hash 策略的 key。采用這種方式優(yōu)化之后,例如原先 3000W 數(shù)據(jù)量的維表,10 個 TM 節(jié)點,每個節(jié)點都要緩存 3000W 的數(shù)據(jù),總共需要緩存 3000W * 10 = 3 億的量。而經(jīng)過 keyBy 優(yōu)化之后,每個 TM 節(jié)點只需要緩存 3000W / 10 = 300W 的數(shù)據(jù)量,總共緩存的數(shù)據(jù)量只有 3000W,大大減少緩存數(shù)據(jù)量。
維表關(guān)聯(lián)延遲 join
維表關(guān)聯(lián)中,有很多業(yè)務(wù)場景,在維表數(shù)據(jù)新增數(shù)據(jù)之前,主流數(shù)據(jù)已經(jīng)發(fā)生 join 操作,會出現(xiàn)關(guān)聯(lián)不上的情況。因此,為了保證數(shù)據(jù)的正確,將關(guān)聯(lián)不上的數(shù)據(jù)進行緩存,進行延遲 join。
最簡單的做法是,在維表關(guān)聯(lián)的 function 里設(shè)置重試次數(shù)和重試間隔,這個方法會增大整個流的延遲,但主流 qps 不高的情況下,可以解決問題。
增加延遲 join 的算子,當(dāng) join 維表未關(guān)聯(lián)時,先緩存起來,根據(jù)設(shè)置重試次數(shù)和重試間隔從而進行延遲的 join。
四、應(yīng)用案例
4.1 實時數(shù)倉
實時數(shù)據(jù)入倉
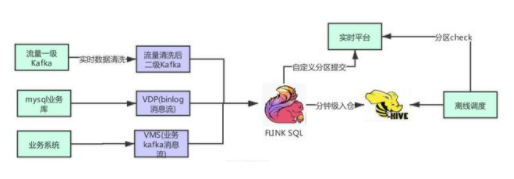
流量數(shù)據(jù)一級 kafka 通過實時清洗之后,寫到二級清洗 kafka,主要是 protobuf 格式,再通過 Flink SQL 寫入 hive 5min 表,以便做后續(xù)的準實時 ETL,加速 ods 層數(shù)據(jù)源的準備時間。MySQL 業(yè)務(wù)庫的數(shù)據(jù),通過 VDP 解析形成 binlog cdc 消息流,再通過 Flink SQL 寫入 hive 5min 表。業(yè)務(wù)系統(tǒng)通過 VMS API 產(chǎn)生業(yè)務(wù) kafka 消息流,通過 Flink SQL 解析之后寫入 hive 5min 表。支持 string、json、csv 等消息格式。使用 Flink SQL 做流式數(shù)據(jù)入倉,非常的方便,而且 1.12 版本已經(jīng)支持了小文件的自動合并,解決了小文件的痛點。我們自定義分區(qū)提交策略,當(dāng)前分區(qū) ready 時候會調(diào)一下實時平臺的分區(qū)提交 api,在離線調(diào)度定時調(diào)度通過這個 api 檢查分區(qū)是否 ready。
采用 Flink SQL 統(tǒng)一入倉方案以后,我們可以獲得的收益:可解決以前 Flume 方案不穩(wěn)定的問題,而且用戶可自助入倉,大大降低入倉任務(wù)的維護成本。提升了離線數(shù)倉的時效性,從小時級降低至 5min 粒度入倉。
實時指標(biāo)計算
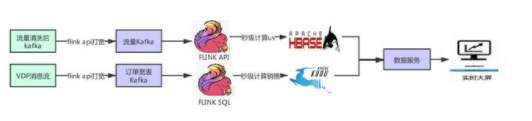
實時應(yīng)用消費清洗后 kafka,通過 redis 維表、api 等方式關(guān)聯(lián),再通過 Flink window 增量計算 UV,持久化寫到 Hbase 里。實時應(yīng)用消費 VDP 消息流之后,通過 redis 維表、api 等方式關(guān)聯(lián),再通過 Flink SQL 計算出銷售額等相關(guān)指標(biāo),增量 upsert 到 kudu 里,方便根據(jù) range 分區(qū)批量查詢,最終通過數(shù)據(jù)服務(wù)對實時大屏提供最終服務(wù)。
以往指標(biāo)計算通常采用 Storm 方式,需要通過 api 定制化開發(fā),采用這樣 Flink 方案以后,我們可以獲得的收益:將計算邏輯切到 Flink SQL 上,降低計算任務(wù)口徑變化快,修改上線周期慢等問題。切換至 Flink SQL 可以做到快速修改,快速上線,降低維護成本。
實時離線一體化 ETL 數(shù)據(jù)集成
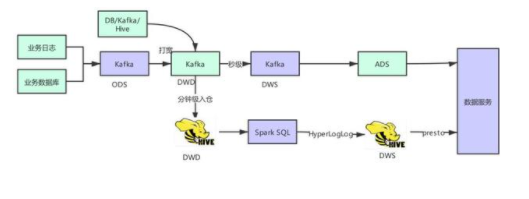
Flink SQL 在最近的版本中持續(xù)強化了維表 join 的能力,不僅可以實時關(guān)聯(lián)數(shù)據(jù)庫中的維表數(shù)據(jù),現(xiàn)在還能關(guān)聯(lián) Hive 和 Kafka 中的維表數(shù)據(jù),能靈活滿足不同工作負載和時效性的需求。
基于 Flink 強大的流式 ETL 的能力,我們可以統(tǒng)一在實時層做數(shù)據(jù)接入和數(shù)據(jù)轉(zhuǎn)換,然后將明細層的數(shù)據(jù)回流到離線數(shù)倉中。
我們通過將 presto 內(nèi)部使用的 HyperLogLog ( 后面簡稱 HLL ) 實現(xiàn)引入到 Spark UDAF 函數(shù)里,打通 HLL 對象在 Spark SQL 與 presto 引擎之間的互通,如 Spark SQL 通過 prepare 函數(shù)生成的 HLL 對象,不僅可以在 Spark SQL 里 merge 查詢而且可以在 presto 里進行 merge 查詢。具體流程如下:
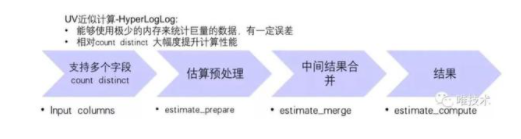
UV 近似計算示例:
Step 1: Spark SQL 生成 HLL 對象
insert overwrite dws_goods_uv partition (dt='${dt}',hm='${hm}') AS select goods_id, estimate_prepare(mid) as pre_hll from dwd_table_goods group by goods_id where dt = ${dt} and hm = ${hm}
Step 2: Spark SQL 通過 goods_id 維度的 HLL 對象 merge 成品牌維度
insert overwrite dws_brand_uv partition (dt='${dt}',hm='${hm}') AS select b.brand_id, estimate_merge(pre_hll) as merge_hll from dws_table_brand A left join dim_table_brand_goods B on A.goods_id = B.goods_id where dt = ${dt} and hm = ${hm}
Step 3: Spark SQL 查詢品牌維度的 UV
select brand_id, estimate_compute(merge_hll ) as uv from dws_brand_uv where dt = ${dt}
Step 4: presto merge 查詢 park 生成的 HLL 對象
select brand_id,cardinality(merge(cast(merge_hll AS HyperLogLog))) uv from dws_brand_uv group by brand_id
所以基于實時離線一體化ETL數(shù)據(jù)集成的架構(gòu),我們能獲得的收益:
統(tǒng)一了基礎(chǔ)公共數(shù)據(jù)源;提升了離線數(shù)倉的時效性;減少了組件和鏈路的維護成本。
4.2 實驗平臺(Flink 實時數(shù)據(jù)入 OLAP)
唯品會實驗平臺是通過配置多維度分析和下鉆分析,提供海量數(shù)據(jù)的 A / B - test 實驗效果分析的一體化平臺。一個實驗是由一股流量(比如用戶請求)和在這股流量上進行的相對對比實驗的修改組成。實驗平臺對于海量數(shù)據(jù)查詢有著低延遲、低響應(yīng)、超大規(guī)模數(shù)據(jù)(百億級)的需求。整體數(shù)據(jù)架構(gòu)如下:
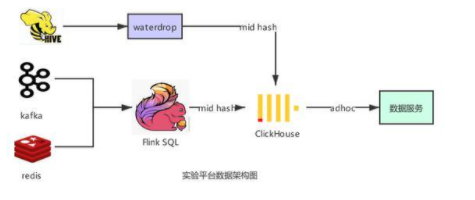
通過 Flink SQL 將 kafka 里的數(shù)據(jù)清洗解析展開等操作之后,通過 redis 維表關(guān)聯(lián)商品屬性,通過分布式表寫入到 clickhouse,然后通過數(shù)據(jù)服務(wù) adhoc 查詢。業(yè)務(wù)數(shù)據(jù)流如下:
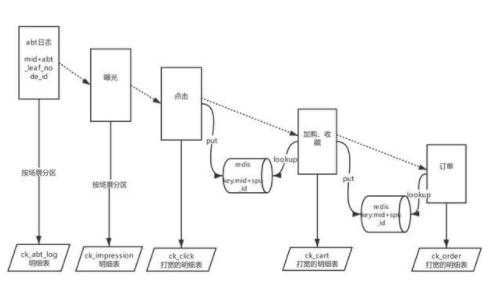
我們通過 Flink SQL redis connector,支持 redis 的 sink 、source 維表關(guān)聯(lián)等操作,可以很方便的讀寫 redis,實現(xiàn)維表關(guān)聯(lián),維表關(guān)聯(lián)內(nèi)可配置 cache ,極大提高應(yīng)用的 TPS。通過 Flink SQL 實現(xiàn)實時數(shù)據(jù)流的 pipeline,最終將大寬表 sink 到 CK 里,并按照某個字段粒度做 murmurHash3_64 存儲,保證相同用戶的數(shù)據(jù)都存在同一 shard 節(jié)點組內(nèi),從而使得 ck 大表之間的 join 變成 local 本地表之間的 join,減少數(shù)據(jù) shuffle 操作,提升 join 查詢效率。
五、未來規(guī)劃
5.1 提高 Flink SQL 易用性
當(dāng)前我們的 Flink SQL 調(diào)試起來很有很多不方便的地方,對于做離線 hive 用戶來說還有一定的使用門檻,例如手動配置 kafka 監(jiān)控、任務(wù)的壓測調(diào)優(yōu),如何能讓用戶的使用門檻降低至最低,是一個比較大的挑戰(zhàn)。將來我們考慮做一些智能監(jiān)控告訴用戶當(dāng)前任務(wù)存在的問題,盡可能自動化并給用戶一些優(yōu)化建議。
5.2 數(shù)據(jù)湖 CDC 分析方案落地
目前我們的 VDP binlog 消息流,通過 Flink SQL 寫入到 hive ods 層,以加速 ods 層數(shù)據(jù)源的準備時間,但是會產(chǎn)生大量重復(fù)消息去重合并。我們會考慮 Flink + 數(shù)據(jù)湖的 cdc 入倉方案來做增量入倉。此外,像訂單打?qū)捴蟮?kafka 消息流、以及聚合結(jié)果都需要非常強的實時 upsert 能力,目前我們主要是用 kudu,但是 kudu 集群,比較獨立小眾,維護成本高,我們會調(diào)研數(shù)據(jù)湖的增量 upsert 能力來替換 kudu 增量 upsert 場景。