大數(shù)據(jù)框架exactly-once底層原理,看這篇文章就夠了
一、大數(shù)據(jù)框架三種語義
在分布式系統(tǒng)中,如kafka、spark、flink等構成系統(tǒng)的任何節(jié)點都是被定義為可以彼此獨立失敗的。比如在 Kafka 中,broker 可能會 crash,在 producer 推送數(shù)據(jù)至 topic 的過程中也可能會遇到網(wǎng)絡問題。根據(jù) producer 處理此類故障所采取的提交策略類型,有如下三種(以kafka為例):
at-least-once:如果 producer 收到來自 Kafka broker 的確認(ack)或者 acks = all,則表示該消息已經(jīng)寫入到 Kafka。但如果 producer ack 超時或收到錯誤,則可能會重試發(fā)送消息,客戶端會認為該消息未寫入 Kafka。如果 broker 在發(fā)送 Ack 之前失敗,但在消息成功寫入 Kafka 之后,此重試將導致該消息被寫入兩次,因此消息會被不止一次地傳遞給最終 consumer,這種策略可能導致重復的工作和不正確的結果。
at-most-once:如果在 ack 超時或返回錯誤時 producer 不重試,則該消息可能最終不會寫入 Kafka,因此不會傳遞給 consumer。在大多數(shù)情況下,這樣做是為了避免重復的可能性,業(yè)務上必須接收數(shù)據(jù)傳遞可能的丟失。
exactly-once:即使 producer 重試發(fā)送消息,消息也會保證最多一次地傳遞給最終consumer。該語義是最理想的,但也難以實現(xiàn),因為它需要消息系統(tǒng)本身與生產和消費消息的應用程序進行協(xié)作。
二、大數(shù)據(jù)框架故障階段(kafka為例)
理想狀況,網(wǎng)絡良好,代碼沒有錯誤,則 Kafka 可以保證 exactly-once,但生產環(huán)境錯綜復雜,故障幾乎無法避免,主要有:
1 框架自身故障(Broker):Kafka 作為一個高可用、持久化系統(tǒng),保證每條消息被持久化并且冗余多份(假設是 n 份),所以 Kafka 可以容忍 n-1 個 broker 故障,意味著一個分區(qū)只要至少有一個 broker 可用,分區(qū)就可用。Kafka 的副本協(xié)議保證了只要消息被成功寫入了主副本,它就會被復制到其他所有的可用副本(ISR)。
2 客戶端發(fā)送框架失敗(Producer 到 Broker 的 RPC):Kafka 的持久性依賴于生產者接收broker 的 ack 。沒有接收成功 ack 不代表生產請求本身失敗了。broker 可能在寫入消息后,發(fā)送 ack 給生產者的時候掛了,甚至 broker 也可能在寫入消息前就掛了。由于生產者沒有辦法知道錯誤是什么造成的,所以它就只能認為消息沒寫入成功,并且會重試發(fā)送。在一些情況下,這會造成同樣的消息在 Kafka 分區(qū)日志中重復,進而造成消費端多次收到這條消息。
3 客戶端也失敗(Producer):Exactly-once delivery 也必須考慮客戶端失敗的情況。但是如何去區(qū)分客戶端是真的掛了(永久性宕機)還是說只是暫時丟失心跳?追求正確性的話,broker 應該丟棄由 zombie producer 發(fā)送的消息。 consumer 也是如此,一旦新的客戶端實例已經(jīng)啟動,它必須能夠從失敗實例的任何狀態(tài)中恢復,并從安全點( safe checkpoint )開始處理,這意味著消費的偏移量必須始終與生成的輸出保持同步。
4 框架發(fā)送消費端失敗(Broker到 Consumer 的 RPC)
三、Exactly-once底層實現(xiàn)原理
3.1、依賴業(yè)務控制
- 對生產者:
每個分區(qū)只有一個生產者寫入消息,當出現(xiàn)異常或超時,生產者查詢此分區(qū)最后一個消息,用于決定后續(xù)操作時重傳還是繼續(xù)發(fā)送。
為每個消息增加唯一主鍵,生產者不做處理,由消費者根據(jù)主鍵去重。
- 對消費者:
關閉自動提交 offset 的功能,不使用 Offsets Topic 這個內部 Topic 記錄其 offset,而是由消費者自動保存 offset。將 offset 和消息處理放在一個事務里面,事務執(zhí)行成功認為消息被消費,否則事務回滾需要重新處理。當出現(xiàn)消費者重啟或者 Rebalance 操作,可以從數(shù)據(jù)庫找到對應的 offset,然后調用 KafkaConsumer.seek() 設置消費者位置,從此 offset 開始消費。
3.2、依賴 Kafka
3.2.1、冪等性:每個分區(qū)中精確一次且有序(Idempotence: Exactly-once in order semantics per partition)
Kafka 在0.11.0.0之前的版本中只支持 At Least Once 和 At Most Once 語義,尚不支持 Exactly Once 語義。
Kafka 0.11.0.0版本引入了冪等語義。 一個冪等性的操作就是一種被執(zhí)行多次造成的影響和只執(zhí)行一次造成的影響一樣的操作。
如果出現(xiàn)導致生產者重試的錯誤,同樣的消息,仍由同樣的生產者發(fā)送多次,將只被寫到 Kafka broker 的日志中一次。
對于單個分區(qū),冪等生產者不會因為生產者或 broker 故障而產生多條重復消息。
想要開啟這個特性,獲得每個分區(qū)內的精確一次語義,也就是說沒有重復,沒有丟失,并且有序的語義,只需要 producer 配置 enable.idempotence=true。
這個特性是怎么實現(xiàn)的呢?每個新的 Producer 在初始化的時候會被分配一個唯一的 PID,該PID對用戶完全透明而不會暴露給用戶。在底層,它和 TCP 的工作原理有點像,每一批發(fā)送到 Kafka 的消息都將包含 PID 和一個從 0 開始單調遞增序列號。
Broker 將使用這個序列號來刪除重復的發(fā)送。和只能在瞬態(tài)內存中的連接中保證不重復的 TCP 不同,這個序列號被持久化到副本日志,所以,即使分區(qū)的 leader 掛了,其他的 broker 接管了leader,新 leader 仍可以判斷重新發(fā)送的是否重復了。這種機制的開銷非常低:每批消息只有幾個額外的字段。這種特性比非冪等的生產者只增加了可忽略的性能開銷。
如果消息序號比 Broker 維護的序號大 1 以上,說明中間有數(shù)據(jù)尚未寫入,也即亂序,此時 Broker 拒絕該消息。
如果消息序號小于等于 Broker 維護的序號,說明該消息已被保存,即為重復消息,Broker直接丟棄該消息。
總結來說,producer 端發(fā)送消息時,生成全局唯一自增pid,和broker中數(shù)據(jù)的pid進行對比,多則刪除,少則通知producer端重新發(fā)送。
3.2.2、事務:跨分區(qū)原子寫入
上述冪等設計只能保證單個 Producer 對于同一個 <Topic, Partition> 的 Exactly Once 語義。
Kafka 現(xiàn)在通過新的事務 API 支持跨分區(qū)原子寫入。這將允許一個生產者發(fā)送一批到不同分區(qū)的消息,這些消息要么全部對任何一個消費者可見,要么對任何一個消費者都不可見。這個特性也允許在一個事務中處理消費數(shù)據(jù)和提交消費偏移量,從而實現(xiàn)端到端的精確一次語義。
為了實現(xiàn)這種效果,應用程序必須提供一個穩(wěn)定的(重啟后不變)唯一的 ID,也即Transaction ID 。 Transactin ID 與 PID 可能一一對應。區(qū)別在于 Transaction ID 由用戶提供,將生產者的 transactional.id 配置項設置為某個唯一ID。而 PID 是內部的實現(xiàn)對用戶透明。
另外,為了保證新的 Producer 啟動后,舊的具有相同 Transaction ID 的 Producer 失效,每次 Producer 通過 Transaction ID 拿到 PID 的同時,還會獲取一個單調遞增的 epoch。由于舊的 Producer 的 epoch 比新 Producer 的 epoch 小,Kafka 可以很容易識別出該 Producer 是老的 Producer 并拒絕其請求。
有了Transaction ID后,Kafka可保證:
- 跨Session的數(shù)據(jù)冪等發(fā)送。當具有相同Transaction ID的新的Producer實例被創(chuàng)建且工作時,舊的且擁有相同Transaction ID的Producer將不再工作。
- 跨Session的事務恢復。如果某個應用實例宕機,新的實例可以保證任何未完成的舊的事務要么Commit要么Abort,使得新實例從一個正常狀態(tài)開始工作。
需要注意的是,上述的事務保證是從Producer的角度去考慮的。從Consumer的角度來看,該保證會相對弱一些。尤其是不能保證所有被某事務Commit過的所有消息都被一起消費,因為:
- 對于壓縮的Topic而言,同一事務的某些消息可能被其它版本覆蓋
- 事務包含的消息可能分布在多個Segment中(即使在同一個Partition內),當老的Segment被刪除時,該事務的部分數(shù)據(jù)可能會丟失
- Consumer在一個事務內可能通過seek方法訪問任意Offset的消息,從而可能丟失部分消息
- Consumer可能并不需要消費某一事務內的所有Partition,因此它將永遠不會讀取組成該事務的所有消息
四、事務中Offset的提交
許多基于Kafka的應用,尤其是Kafka Stream應用中同時包含Consumer和Producer,前者負責從Kafka中獲取消息,后者負責將處理完的數(shù)據(jù)寫回Kafka的其它Topic中。
為了實現(xiàn)該場景下的事務的原子性,Kafka需要保證對Consumer Offset的Commit與Producer對發(fā)送消息的Commit包含在同一個事務中。否則,如果在二者Commit中間發(fā)生異常,根據(jù)二者Commit的順序可能會造成數(shù)據(jù)丟失和數(shù)據(jù)重復:
- 如果先Commit Producer發(fā)送數(shù)據(jù)的事務再Commit Consumer的Offset,即At Least Once語義,可能造成數(shù)據(jù)重復。
- 如果先Commit Consumer的Offset,再Commit Producer數(shù)據(jù)發(fā)送事務,即At Most Once語義,可能造成數(shù)據(jù)丟失。
五、分布式事務經(jīng)見實現(xiàn)機制
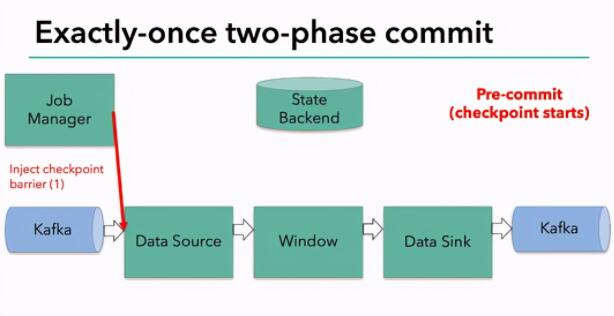
5.1 兩階段提交
Kafka的事務機制與《分布式事務(一)兩階段提交及JTA》一文中所介紹的兩階段提交機制看似相似,都分PREPARE階段和最終COMMIT階段,但又有很大不同。
- Kafka事務機制中,PREPARE時即要指明是PREPARE_COMMIT還是PREPARE_ABORT并且只須在Transaction Log中標記即可,無須其它組件參與。而兩階段提交的PREPARE需要發(fā)送給所有的分布式事務參與方,并且事務參與方需要盡可能準備好,并根據(jù)準備情況返回Prepared或Non-Prepared狀態(tài)給事務管理器。
- Kafka事務中,一但發(fā)起PREPARE_COMMIT或PREPARE_ABORT則確定該事務最終的結果應該是被COMMIT或ABORT。而分布式事務中,PREPARE后由各事務參與方返回狀態(tài),只有所有參與方均返回Prepared狀態(tài)才會真正執(zhí)行COMMIT,否則執(zhí)行ROLLBACK
- Kafka事務機制中,某幾個Partition在COMMIT或ABORT過程中變?yōu)椴豢捎茫挥绊懺揚artition不影響其它Partition。兩階段提交中,若唯一收到COMMIT命令參與者Crash,其它事務參與方無法判斷事務狀態(tài)從而使得整個事務阻塞
- Kafka事務機制引入事務超時機制,有效避免了掛起的事務影響其它事務的問題
- Kafka事務機制中存在多個Transaction Coordinator實例,而分布式事務中只有一個事務管理器
兩階段提交原理
二階段提交的算法思路可以概括為:協(xié)調者詢問參與者是否準備好了提交,并根據(jù)所有參與者的反饋情況決定向所有參與者發(fā)送commit或者rollback指令(協(xié)調者向所有參與者發(fā)送相同的指令)。
所謂的兩個階段是指
- 準備階段 又稱投票階段。在這一階段,協(xié)調者詢問所有參與者是否準備好提交,參與者如果已經(jīng)準備好提交則回復Prepared,否則回復Non-Prepared。
- 提交階段又稱執(zhí)行階段。協(xié)調者如果在上一階段收到所有參與者回復的Prepared,則在此階段向所有參與者發(fā)送commit指令,所有參與者立即執(zhí)行commit操作;否則協(xié)調者向所有參與者發(fā)送rollback指令,參與者立即執(zhí)行rollback操作。
5.2 Zookeeper
Zookeeper的原子廣播協(xié)議與兩階段提交以及Kafka事務機制有相似之處,但又有各自的特點
- Kafka事務可COMMIT也可ABORT。而Zookeeper原子廣播協(xié)議只有COMMIT沒有ABORT。當然,Zookeeper不COMMIT某消息也即等效于ABORT該消息的更新。
- Kafka存在多個Transaction Coordinator實例,擴展性較好。而Zookeeper寫操作只能在Leader節(jié)點進行,所以其寫性能遠低于讀性能。
- Kafka事務是COMMIT還是ABORT完全取決于Producer即客戶端。而Zookeeper原子廣播協(xié)議中某條消息是否被COMMIT取決于是否有一大半FOLLOWER ACK該消息。