













Google 開源 Lyra 編解碼器,利用機器學習減少語音通話帶寬使用
在疫情的持續影響下,過去一年多的時間表明,在線交流對我們的生活十分重要。無論你身處何地,無論網絡條件如何,清楚地了解彼此的在線情況從未像現在這樣重要。這就是為什么 Google 在 2 月份推出了 Lyra 的原因:一個革命性的新音頻編解碼器,使用機器學習來產生高質量的語音通話。

為了讓這個編解碼器變得更加完善,Google 近日通過官方博客宣布將 Lyra 進行開源,允許其他開發者為他們的通信應用提供助力。這個版本提供了開發者使用 Lyra 進行音頻編碼和解碼所需的工具,針對 64 位 ARM Android 平臺進行了優化,并在 Linux 上進行了開發。Google 希望能夠擴展這個代碼庫,并與社區一起開發對其他平臺的支持和改進。
Lyra 架構
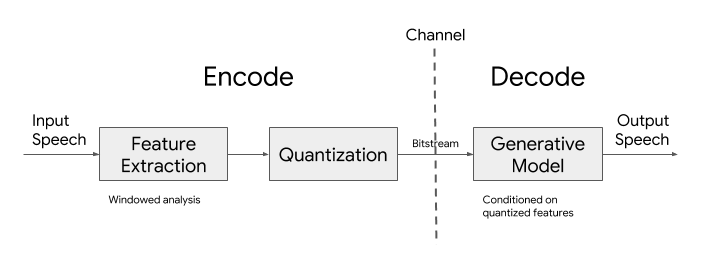
Lyra的架構分為兩部分,編碼器和解碼器。當有人對著手機說話時,編碼器會從他們的語音中捕捉獨特的屬性。這些語音屬性,也稱為特征,以40ms為單位提取,然后壓縮并通過網絡發送。解碼器的工作是將這些特征轉換回音頻波形,以便通過電話聽筒播放出來。
將特征解碼回波形的過程是通過生成模型(Generative models)處理的,生成模型是一種特殊類型的機器學習模型,非常適合從有限的特征中重新創建一個完整的音頻波形。Lyra架構與傳統的音頻編解碼器非常相似,幾十年來,傳統的音頻編解碼器已經構成了互聯網通信的主干。這些傳統的編解碼器是基于數字信號處理(DSP)技術,而 Lyra 的關鍵優勢來自于生成模型重建高質量語音信號的能力。
Lyra 架構圖
影響
在過去十年中,設備上計算能力的爆炸性增長超過了可靠的高速無線基礎設施的建設。對于存在這種反差的地區——特別是對發展中國家而言,技術將使人們能夠更緊密地聯系在一起的承諾仍然遙遙無期。即使在擁有高度可靠網絡環境的地區,"隨時隨地"工作和遠程辦公的出現也進一步限制了移動數據的使用。雖然 Lyra 將原始音頻壓縮到 3kbps,質量優于其他編解碼器(如 Opus),但它并不打算成為一個完全的替代方案,而是可以在這種情況下節省帶寬。
此外,Google 還認識到 Lyra 可能會有其他一些獨特的應用,由于 Lyra 可以顯著減少音頻文件大小,因此可以用于存檔大量的語音;通過利用 Lyra 編碼器來節省移動設備的電量;緩解緊急情況下許多人試圖同時撥打電話的網絡擁堵。
開源版本
Lyra 的代碼是用 C++ 所編寫的,以提高速度、效率和互操作性,使用 Bazel 構建框架和 GoogleTest 框架進行徹底的單元測試,并基于 Apache 許可協議進行分發。感興趣的用戶可以訪問 GitHub 查看源代碼及演示。
本文轉自OSCHINA
本文標題:Google 開源 Lyra 編解碼器,利用機器學習減少語音通話帶寬使用
本文地址:https://www.oschina.net/news/136239/google-open-source-lyra





















