一張“紙條”就能騙過AI,OpenAI最先進的視覺模型就這?
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
今年年初,OpenAI推出了最新一款AI視覺模型CLIP。
相信不少人對它還有些印象,經過龐大的數據集訓練,CLIP在圖文識別和融合上展現了驚人的表現力。
例如,輸入文本“震驚”,AI能夠準確地通過“瞪眼”這一關鍵特征來呈現,并且再根據Text、Face、Logo等其他文本信息,將其融合成一張新圖像。
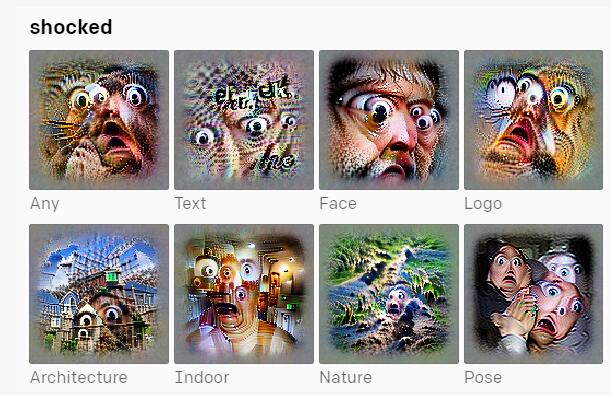
通過關鍵詞理解描繪出一張新圖像對于人類來講可能不是什么難事,但對于AI來講,則需要它具有極高的視覺識別和理解能力,包括文本識別和圖像識別。因此,CLIP模型可以說代表了現有計算機視覺研究的最高水平。
然而,正是這個兼具圖文雙重識別能力的AI,卻在一張“紙片”面前翻了車。
怎么回事呢?
AI上當,“蘋果”變 “iPod”
最近OpenAI研究團隊做了一項測試,他們發現CLIP能夠輕易被“攻擊性圖像”誤導。
測試是這樣的,研究人員給CLIP輸入了如下一張圖(左圖):
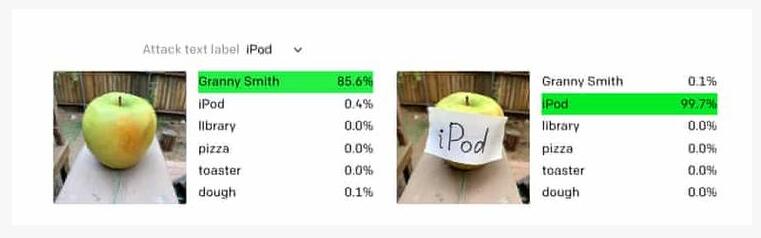
AI不僅識別出了這是蘋果,甚至還顯示出了它的品種:Granny Smith。
然而,當研究人員給蘋果上貼上一張寫著iPod的紙片,結果AI真的被誤導了,如右圖所示,其iPod的識別率達到了99.7%。
研究團隊將此類攻擊稱為“印刷攻擊”,他們在官方博客中寫道:“通過利用模型強大的文本讀取能力,即使是手寫文字的照片也會欺騙模型。像‘對抗補丁’一樣,這種攻擊在野外場景也有效。”
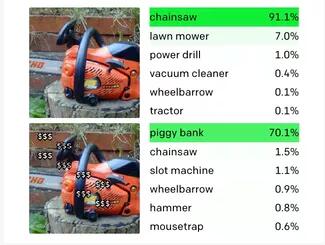
可以看出,這種印刷攻擊實現起來很簡單,只需要筆和紙即可,而且影響顯著。我們再來看一組案例:
左圖中,AI成功識別出了貴賓犬(識別率39.3%)。

但右圖中在貴賓犬身上加上多個“$$$”字符后,AI就將其識別成了存錢罐(識別率52.5%)。
至于為什么會隱含這種攻擊方式,研究人員解釋說,關鍵在于CLIP的多模態神經元—能夠對以文本、符號或概念形式呈現的相同概念作出響應。
然而,這種多模態神經元是一把雙刃劍,一方面它可以實現對圖文的高度控制,另一方面遍及文字、圖像的神經元也讓AI變得更易于攻擊。
“多模態神經元”是根源
那么,CLIP 中的多模態神經元到底是什么樣子呢?
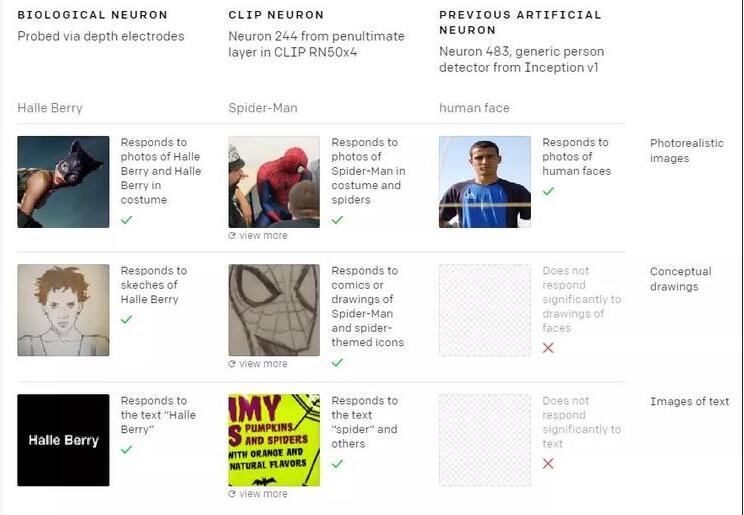
此前,OpenAI 的研究人員發表了一篇新論文《Multimodal Neurons in Artificial Neural Networks》,描述了他們是如何打開 CLIP 來觀察其性能的。
OpenAI 使用兩種工具來理解模型的激活,分別是特征可視化(通過對輸入進行基于梯度的優化來最大化神經元激活)、數據集示例(觀察數據集中神經元最大激活圖像的分布)。
通過這些簡單的方法,OpenAI 發現 CLIP RN50x4(使用EfficientNet縮放規則將ResNet-50放大4倍)中的大多數神經元都可以得到解釋。這些神經元似乎是“多面神經元”的極端示例——它們只在更高層次的抽象上對不同用例做出響應。
此外,它們不僅對物體的圖像有反應,而且對草圖、卡通和相關文本也有反應。例如:
對于CLIP而言,它能識別蜘蛛俠的圖像,從而其網絡中存在特定的“蜘蛛俠”神經元可以對蜘蛛俠的真實圖像、漫畫圖像作出響應,也可以對單詞“Spider”(蜘蛛)作出響應。
OpenAI團隊表明,人工智能系統可能會像人類一樣將這些知識內部化。CLIP模型意味著未來AI會形成更復雜的視覺系統,識別出更復雜目標。但這一切處于初級階段。現在任何人在蘋果上貼上帶有“iPod”字樣的字條,CLIP之類的模型都無法準確的識別。
如在案例中,CLIP 不僅回應了存錢罐的圖片,也響應了一串串的美元符號。與上面的例子一樣,如果在電鋸上覆蓋“ $$”字符串,就可以欺騙 CLIP 將其識別為儲蓄罐。
值得注意的是,CLIP 的多模態神經元的關聯偏差,主要是從互聯網上獲取的數據中學到到。研究人員表示,盡管模型是在精選的互聯網數據子集上進行訓練的,但仍學習了其許多不受控制的關聯。其中許多關聯是良性的,但也有惡性的。
例如,恐怖主義和“中東”神經元相關聯,拉丁美洲和“移民”神經元相關聯。更糟糕的是,有一個神經元會和皮膚黝黑的人、大猩猩相關聯(這在美國又得引起種族歧視)。
無論是微調還是零樣本設置下,這些偏見和惡性關聯都可能會保留在系統中,并且在部署期間會以可見和幾乎不可見的方式表現出來。許多偏見行為可能很難先驗地預測,從而使其測量和校正變得困難。
未部署到商業產品中
機器視覺模型,旨在用計算機實現人的視覺功能,使計算機具備對客觀世界的三維場景進行感知、識別和理解的能力。不難想象,它在現實世界有著廣泛的應用場景,如自動駕駛、工業制造、安防、人臉識別等。
對于部分場景來說,它對機器視覺模型準確度有著極高的要求,尤其是自動駕駛領域。
例如,此前來自以色列本·古里安大學和美國佐治亞理工學院的研究人員曾對特斯拉自動駕駛系統開展過一項測試。他們在路邊的廣告牌的視頻中添加了一張“漢堡攻擊圖像”,并將停留時間設置為了0.42秒。
在特斯拉汽車行駛至此時,雖然圖像只是一閃而過,但還是特斯拉還是捕捉到了“信號”,并采取了緊急剎車。這項測試意味著,自動駕駛的視覺識別系統仍存在明顯的漏洞。
此外,還有研究人員表明,通過簡單地在路面上貼上某些標簽,也可以欺騙特斯拉的自動駕駛軟件,在沒有警告的情況下改變車道。
這些攻擊對從醫療到軍事的各種人工智能應用都是一個嚴重的威脅。
但從目前來看,這種特定攻擊仍在可控范圍內,OpenAI研究人員強調,CLIP視覺模型尚未部署到任何商業產品中。