注意這個數據科學錯誤,避免30多個小時的無用功……
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
下面這個模型在一項圖像識別競賽中經過了數天訓練。這是個相對比較簡單的模型,其AUC最初是0.9,符合比賽將AUC控制在0到1之間的要求,除此之外我對比賽也沒有太高的期望。也正因如此,當我照例評估重量模型,對模型進行訓練時,看到如下結果大吃一驚:
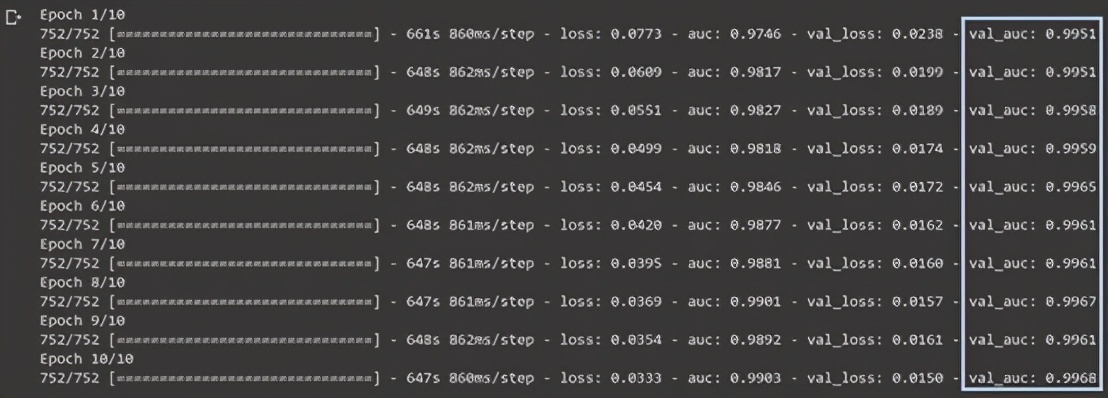
在當時比賽的實時排行榜中,排名首位的AUC值為0.965,而我當時的有效AUC值達到了0.9968,離獲勝拿獎僅有一步之遙,在一百多個隊伍中遙遙領先,讓我難以置信。深度學習之神好像是在這天點化了我,讓我在權重初始化上取得了這樣傲人的成績,簡直像有了優化超能力一樣厲害。
這個結果好的讓人難以置信。雖然我很想相信模型給出的數據,但我仍持有一絲懷疑。我一次又一次地對模型預測進行評估,起初測試了部分數據,然后測試了全部數據。結果是肯定的:驗證分數接近完美。
因此我確信自己找到了獲勝的捷徑,準備拿下第一名,帶著激動的心情,我趕忙將模型對測試數據的預測提交了。獎金唾手可得。
而比賽分數令人震驚。

0.5分。即便是隨便提交一個預測,或者是什么都不做僅僅是把比賽提供的樣本文件提交都能拿到0.5分。我當時獲得的魔法般的頓悟也就比瞎猜強了一點。
結果出來之后,我花了30多個小時,復盤數據,試圖找出哪里出了問題,整個人精疲力竭。預測中肯定那兒除了問題,可能是文件傳錯了。
然而,這30個小時也不過是白費功夫。我花了九牛二虎之力更正結果,但預測結果值仍然很低。
到底是哪里出問題了?
答案是:數據泄露。數據泄露是個很簡單的概念,但我就直直地走進了它的陷阱。在模型訓練中,我的編程沒有任何問題,模型也正確依照測試數據進行了訓練,問題出現在了不易發現的地方。
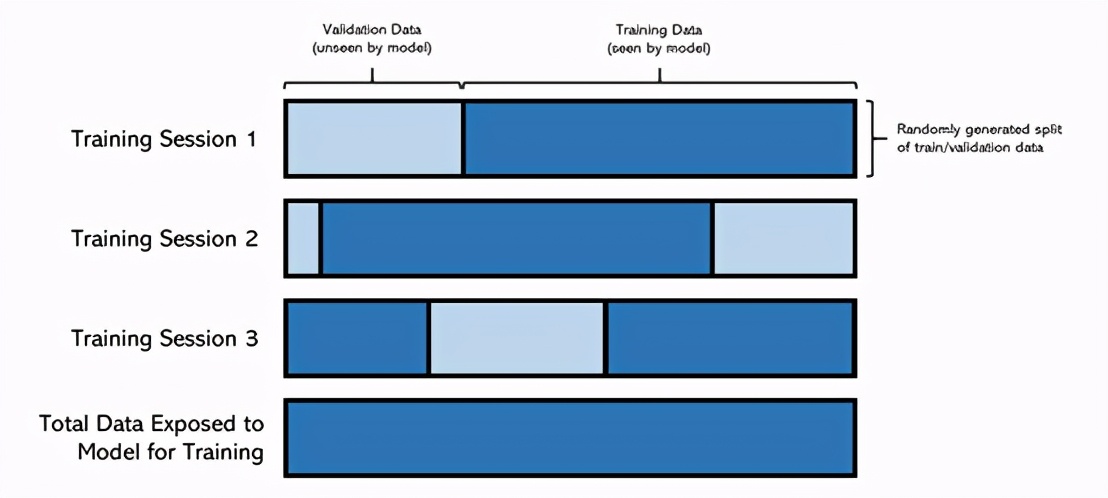
簡而言之,當模型遇到不該遇到的情況時,就會發生數據泄漏。在比賽中,我已經在多個會話中訓練了模型,也就是說,我將從上一個會話中加載模型權重,訓練模型并保存最佳性能的權重。由于計算時間限制,訓練在多個會話中進行。
但是,在每個會話中,我都會重新運行整個代碼,包括將數據隨機分為訓練和驗證集的代碼,因此每次培訓的訓練集并不相同。為避免這種情況,可以設置一個種子來劃分訓練/驗證組,而這是我(非常)沒有提前采取的措施。
盡管每次的訓練數據都不同,但模型的權重(它所了解的信息)卻被傳遞了下來。因此,經過足夠的培訓后,該模型已被暴露給整個數據集。
由于機器學習模型本身具有惰性,所以該模型會放棄學習,轉而對數據進行記憶,這對沒有感情的網絡來說非常簡單,也就導致這種現象發生過很多次。因此,面對從未見過的數據時,這個模型就無能為力了。
由于該模型已經在之前的訓練中見過驗證數據,所以才能得到近乎完美的0.9968,讓我誤以為這就是模型本身的能力。如果回憶一下模型早期的性能,想一想為什么驗證分數會高于訓練分數,就會明白這其實是一個相當奇怪且罕見的現象。
所以,大家在接下來的每一個實踐中都要牢記這重要的一課:如果結果太過完美,讓人不敢相信,那十有八九這個結果有問題。(這個方法在鑒別數據泄露中尤其重要。)
這是一種數據泄露,其他類型的泄露包括:
- 預處理。如果在拆分之前處理數據,那可能會導致信息泄漏。例如,如果你在整個數據集中使用均值之類的方法,則訓練集將包含有關驗證集的數據,反之亦然。
- 時間。如果在預測問題涉及到了時間,那簡單的隨機訓練/驗證拆分無效。也就是說,如果要基于A和B預測C,則應在[A,B]→C上訓練模型,而不要像[C,A]→B那樣訓練。這是因為知道了之后的數據點C的值,模型就可以預測之前的數據點B。
在事情太過完美的時候三思是個好習慣,但也要注意其中微妙的細節。比如說,分數增加的幅度很大,但不一定是很奇怪的現象;而當模型對測試數據進行預測時,其性能又很差勁。
實際上,最好的辦法是注意以任何方式分割數據的目的,以便將它們分為訓練/驗證/測試集,并盡早進行。此外,設置種子是強有力的保障。
從更開放的角度上講,數據泄漏可能是有益的。如果模型看到了不應該看到的數據,但是看到的數據有助于提升其概括能力,幫助學習,那么數據泄漏是有好處的。
例如,Kaggle的排名系統。該系統由一個公共排行榜和一個私人排行榜組成。在比賽結束之前,用戶可以訪問所有訓練內容和部分測試內容(在該系統中可訪問25%的內容,用于確定公共排行榜上的位置)。但是,比賽結束后,測試內容的另75%將用于評估模型,以確定最終私人排行榜的排位。
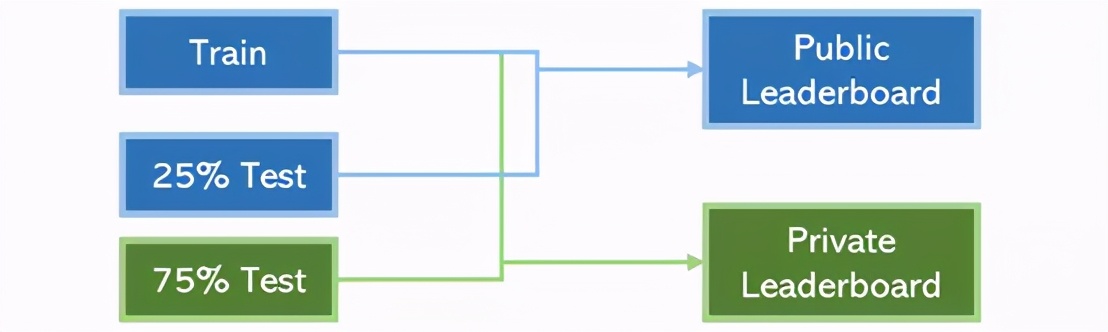
不過,如果我們能利用這25%的測試內容來提高私人排行榜上分數,這就算是數據泄露。
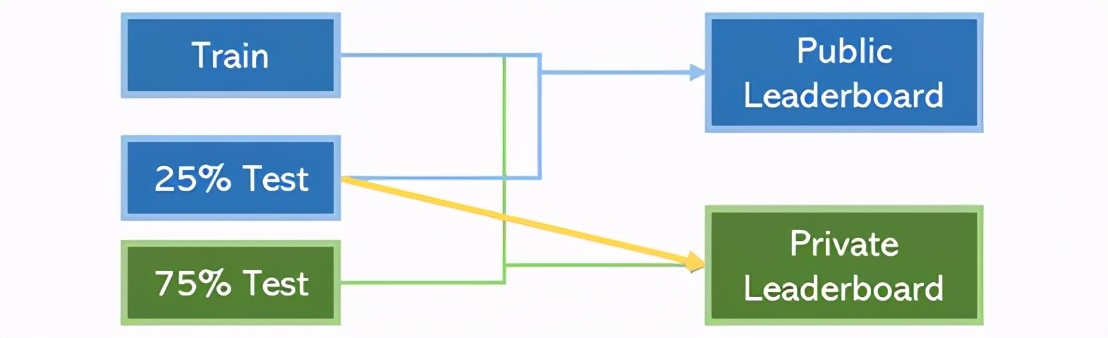
在Kaggle競賽中,相對常見的做法是在了解其他25%測試數據的情況下對75%測試數據進行某種預處理。比如,可以采用PCA來降低尺寸。這通常都會提升模型性能,因為數據一般都是越多越好。
我們在尋找提高數據連接性方法的道路上應永不停歇;一般來說,永遠不要將任何復雜的事件標記為純粹的壞(或好)事件。
總而言之,數據科學家應致力于為模型提供更多的數據,但要把不同用處的數據區分開。此外,為了不讓希望破滅,你應該消極地編程。畢竟,只有預期了最差的結果,面對問題才能淡定處理,面對成功也能欣喜若狂。