微服務流控防護場景與應對措施
前言
微服務成了互聯網架構的標配模式,對微服務之間的調用的流量治理和管控就尤為重要。哪些場景需要流量防控,針對這些場景又有哪些應對措施。有沒有一個通用的措施來降低風險呢?這篇文章咱就聊聊這個。
一、服務被過載調用
當服務D的某個接口服務被上游服務過載調用時,如果不對服務D加入保護,可能整體將服務D整體拖垮。在這種場景中,我們需要對服務D配置限流,以保護服務D不被整體沖跨。
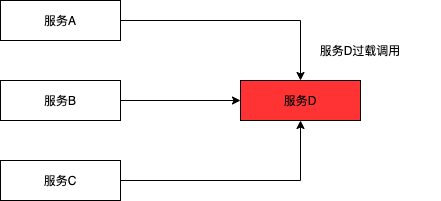
應對措施: 針對服務提供方D配置流量防護規則,對進入服務D的流量進行控制,從而對服務D提供保護。觸發流控時可以有多重策略,例如:快速失敗、預熱模式、排隊等待、預熱模式+排隊等待。
快速失敗: 發生流控時直接拋出異常。
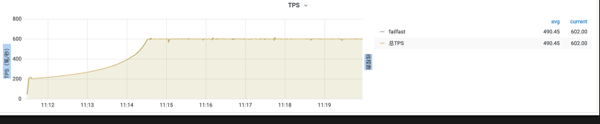
預熱模式: 發生流控時,流量緩慢增加的一種模式,效果如下圖所示,流量QPS從200緩慢增加到600。
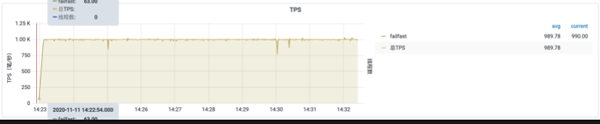
排隊等待: 請求勻速通過,過多請求需要排隊,此時排隊有超時時間,超過排隊時間拋出流控異常。效果如下圖所示:請求QPS保持1000的勻速通過。
預熱模式+排隊等待: 這種模式是預熱和排隊等待的疊加模式,請求以勻速的方式緩慢增加。如下圖:請求從0緩慢增加到500,勻速通過一段時間后,再增加到1000。

二、服務慢調用或故障
下面的場景A調用B、A調用C、A調用D,當服務B服務不穩定時,服務A調用服務B發生了慢調用或者大量異常錯誤。這種場景,如果不干預,可能影響到A調用C和A調用D的狀況。
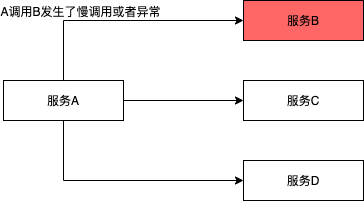
應對措施: A調用B配置熔斷降級規則,當服務B不穩定發生慢調用或者異常時,如果觸發閾值,將服務B的調用熔斷;從而保護了服務A調用C、服務A調用D的正常情況。
熔斷效果: 熔斷的實現通常通過斷路器實現,具體過程為:
- 當滿足慢調用比例、異常比例、異常數量閾值后,觸發熔斷(OPEN),在熔斷時長內拒絕所有請求
- 當熔斷過了定義的熔斷時長,狀態由熔斷(OPEN)變為探測(HALF_OPEN)
- 接下來的一個請求不發生慢調用或者異常,熔斷結束由探測狀態(HALF_OPEN)變為(CLOSED)
- 接下來的一個請求發生慢調用或者異常,繼續熔斷,由探測狀態(HALF_OPEN)變為(OPEN)
三、服務資源被擠占
分布式鏈路中,如果某一條鏈路產生慢調用,對其他鏈路造成擠壓。除了上面提到配置熔斷降級外,可以通過線程并發控制來隔離。
下圖中有3條鏈路,其中鏈路1由于服務E的不穩定,產生了慢調用。

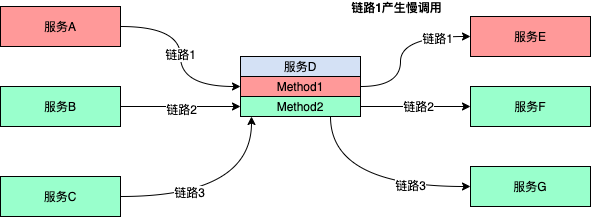
鏈路1慢調用可能導致如下情況:
- 鏈路1線程數增多對服務D資源造成擠壓
- 對服務D資源的過度擠壓,鏈路2和鏈路3造成不穩定
- 極端情況導致整個服務D不可用,嚴重時引發雪崩
應對措施: 通過對服務D的MethodA1、MethodA2的線程數并發設置規則,超過閾值時將會觸發阻斷,不再向下游調用,避免不可用引發雪崩。
并發控制效果 下圖中設置了調用方的并發線程數為10,通過每分鐘的查詢可以看出,線程數一直保持在10。
四、數據過熱擠占資源
熱點數據,比如:大促時的熱銷產品、秒殺類產品等。如下圖所示,如果不對熱點商品下單流量進行管控,可能對其他商品造成擠壓;影響整個商品下單體驗。

應對措施: 通過對熱點參數測速,配置流控規則,超過閾值時觸發流控。例如:通過對入參產品ID進行測速,超過設置的閾值時,觸發流控,避免對其過度擠占資源。
五、通用防護分組措施
上面的現象中,無論是服務不穩定、還是被擠占、或者被過載調用。除了通過上述的防護措施外,可以對服務進行等級劃分并分組。
如下圖所示:服務A和服務D為核心服務、服務B和服務C為非核心服務。通過將服務D進行分組,分成了1組和2組。分組1只允許核心服務調用,分組2只允許非核心服務調用。
這樣做的好處:將流量進行物理隔離,避免由于非核心業務流量對核心業務流量造成擠壓、保護核心鏈路穩定性。
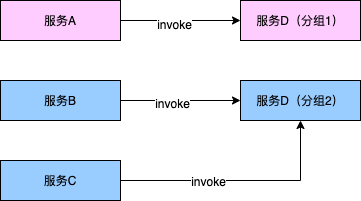
分組措施@1 通常可以更換注冊中心路徑實現,服務A和服務D(分組1)放在同一個注冊中心路徑(例如:soa-group1);服務B、服務C、服務D(分組2)放在另一個不同的注冊中心路徑(例如:soa-group2)。
分組措施@2 通過對分組的服務節點打標實現,例如:服務D(分組1)節點被打標為group1,服務D(分組2)節點被打標為group2。在服務消費方訂閱節點時根據不同的分組篩選節點調用。