













裴健團隊44頁新作:理解深度學習模型復雜度,看這一篇就夠了
在機器學習、數據挖掘和深度學習中,模型復雜性始終是重要的基本問題。
模型的復雜性不僅會影響模型在特定問題和數據上的可學習性,模型在看不見的數據上的泛化能力也與之有關。
模型的復雜性不僅受模型體系結構的本身影響,還受到數據分布,數據復雜性和信息量的影響。
因此近年來,模型復雜性已成為一個越來越活躍的方向,在模型體系結構搜索、圖形表示、泛化研究和模型壓縮等領域都至關重要。
近日,首篇深度學習模型復雜度綜述「Model Complexity of Deep Learning: A Survey」在arXiv上線。
并對這兩個方向的最新進展進行了回顧。
論文作者為著名大數據科學家裴健教授與他的兩位學生,以及微軟亞洲研究院的兩位合作者。
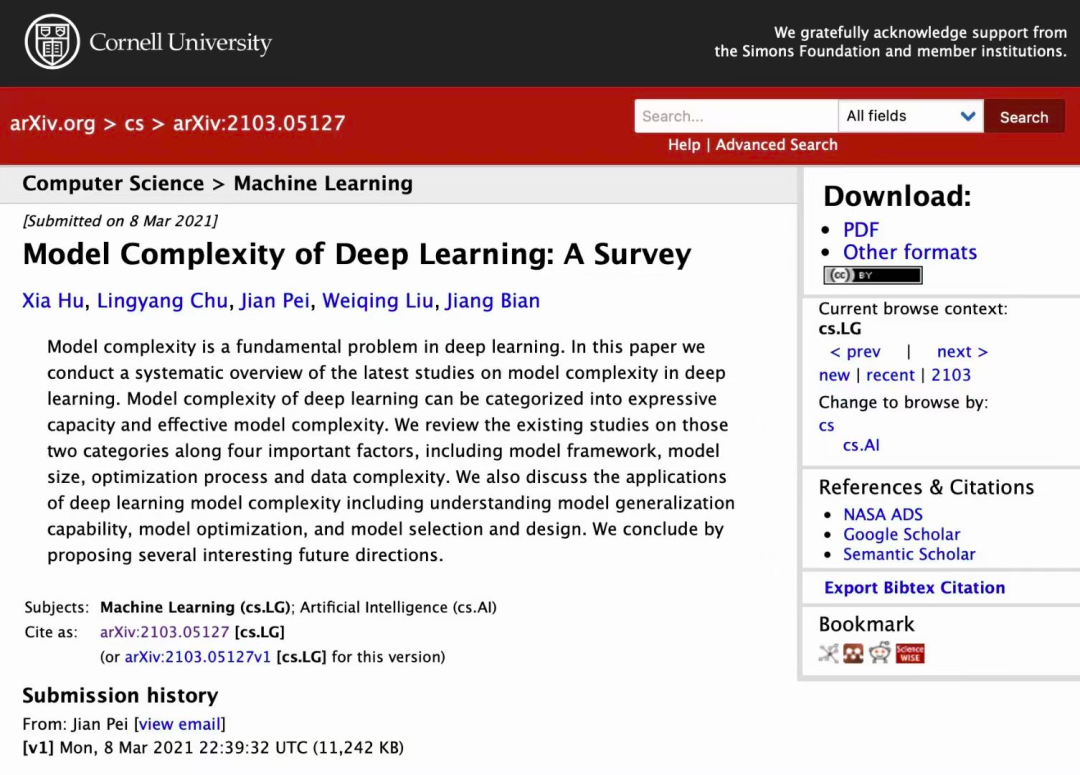
深度學習的模型復雜性可以解釋為「表達能力」和「有效模型復雜度」。在這篇論文在,研究人員沿著模型框架、模型尺寸、優化過程、數據復雜度四個重要因素對這兩類模型的現有研究進行回顧。
最后,作者再從理解模型泛化能力、優化策略、模型的選擇與設計對其應用進行論述。
可以說,理解深度學習模型復雜度,看這一篇就夠了。
首篇深度學習模型復雜度綜述,四個重要因素
首先,我們先來看模型復雜度受哪些因素影響。
模型框架
模型框架的選擇影響模型的復雜性。影響因素包括模型類型(如FCNN、CNN),激活函數(例如,Sigmoid、ReLU)等。不同的模型框架可能需要不同的復雜性度量標準和方法可能無法直接相互比較。
模型尺寸
深度模型的大小影響模型的復雜度。一些常見的所采用的模型尺寸測量方法包括參數個數、參數個數隱藏層的數量、隱藏層的寬度、過濾器的數量以及過濾器大小。在同一模型框架下,模型的復雜性對于不同的大小,可以通過相同的復雜性度量進行量化從而成為可比較的標準。
優化過程
優化過程影響模型的復雜度,包括目標函數的形式、學習算法的選擇和超參數的設置。
數據復雜度
訓練模型的數據也會影響模型的復雜性。主要影響因素包括數據維度、數據類型和數據類型分布、由Kolmogorov復雜性度量的信息量等。
通常來說,復雜度的研究模型選取有如下兩種:
一是指定模型(model-specific)的方法關注于特定類型的模型,并基于結構特征探索復雜性。例如,Bianchini等人和Hanin等人研究了FCNNs的模型復雜性,Bengio和Delalleau關注和積網絡的模型復雜性。此外,一些研究進一步提出了激活的限制條件約束非線性特性的函數。
還有一種方法是跨模型(cross-model),當它涵蓋多種類型的模型時,而不是多個特定類型的模型,因此可以應用于比較兩個或多個更多不同類型的模型。例如,Khrulkov等人比較了建筑物連接對一般RNN、CNN和淺層FCNN復雜性的影響在這些網絡結構和張量分解中。
「表達能力」與「有效模型復雜度」
模型的表達能力
模型的表達能力意味著這個模型在不同數據上的表達能力,即性能,綜述主要分析方法是從下面四個角度分析。
深度效率(depth efficiency)分析深度學習模型如何從架構的深度獲得更好地性能(例如,精確度)。
寬度效率(width efficiency)分析深度學習中各層的寬度對模型影響程度。
可表達功能空間(expressible functional space)研究可表達的功能由具有特定框架和指定大小的深模型表示,在不同參數的情況下。
最后,VC維度和Rademacher復雜性是機器學習中表達能力的兩個經典度量。
模型的有效復雜度
深度學習模型的有效復雜性也稱為實際復雜性、實際表達能力和可用容量。
它反映了復雜性具有特定參數化的深部模型所代表的函數。深度學習模型的有效復雜性主要從以下兩個方面進行了探討。
有效復雜性的一般度量(general measures of effective complexity)設計深度學習模型有效復雜性的量化度量。
對高容量低現實現象的調查發現深度學習模型的有效復雜性可能遠低于他們的表達能力。一些研究探討了深度學習模型的有效復雜性和表達能力之間的差距。
模型復雜度的應用
這篇論文主要介紹了三個應用,理解模型泛化能力、模型優化、模型選擇和設計。
理解模型泛化能力
深度學習模型總是過于參數化,也就是說,它們的參數要多得多,模型參數比最優解和訓練樣本數多。然而,人們經常發現大型的過參數化神經網絡具有良好的泛化能力。一些研究甚至發現更大、更復雜的網絡通常更具通用性。這一觀察結果與函數復雜性的經典概念相矛盾,例如著名的奧卡姆剃須刀原則,更喜歡簡單的定理。
什么導致過度參數化深度學習模型的良好泛化能力?
1、在訓練誤差為零的情況下,一個網絡訓練在真實的標簽上,導致良好的泛化能力,其復雜度比在隨機標簽上訓練的網絡要低得多。
2、增加隱藏單元的數量或參數的數量,從而減少了泛化誤差,有望降低復雜度。
3、使用兩種不同的優化算法,如果都導致零訓練誤差,具有較好泛化能力的模型具有較低的復雜度。
優化策略
模型優化關注的是神經網絡模型如何建立以及為什么建立,為什么可以成功訓練。具體來說,優化一個深度學習模型一般是確定模型參數,使損失函數最小化非凸的。損失函數的設計通常基于一個問題和模型的要求,因此一般包括在訓練集上評估的性能度量和其他約束條件。
模型復雜度被廣泛用于提供一個度量來進行優化可追蹤。例如,有效模型復雜性的度量指標神經網絡有助于監測優化過程中模型的變化處理并理解優化過程是如何進行的。這樣的度量也有助于驗證優化算法新改進的有效性。
Nakkiran等人研究了訓練過程中的雙下降現象利用有效復雜度度量數據集的最大大小,在該數據集上可以得到零訓練誤差實現。結果表明,雙下降現象是可以表示的作為有效復雜性的函數。Raghu等人和Hu等人提出了新的正則化方法,并證明了這些方法對減小復雜度是有效的。
模型選擇和設計
給定一個具體的學習任務,研究人員如何為這個任務確定一個可行的模型結構。給出了各種不同體系結構和不同性能的模型復雜性,研究人員如何從中挑選出最好的模型?這就是模型選擇和設計問題。
一般來說,模型的選擇和設計是基于兩者之間的權衡,預測性能和模型復雜性。

一方面,高精度的預測是學習模型的基本目標。模型應該能夠捕獲隱藏在模型中的底層模式訓練數據和實現預測的精度盡可能高。為了表示大量的知識并獲得較高的準確度,一個模型具有較高的表達能力,自由度大,體積大,需要更大訓練集。在這個程度上,一個具有更多參數和更高的復雜性是有利的。
另一方面,過于復雜的模型可能很難進行訓練,可能會導致不必要的資源消耗,例如存儲、計算和時間成本。不必要的資源消耗特別是在實際的大規模應用中,應避免使用。為了這個目標,一個更簡單的模型比一個更精確的模型更可取。
數據價值和數據資產管理
綜述的作者裴健是數據科學領域的世界頂尖學者,加拿大西蒙弗雷澤大學計算機科學學院教授,還是加拿大皇家學會、加拿大工程院、ACM和IEEE的院士。
近日,在O'Reilly媒體集團原首席數據科學家Ben Lorica 羅瑞卡主持的podcast中,裴健教授談論了數據價值和數據資產管理的問題。
他認為,第一,數據作為企業的核心資源,CFO和CDO要一起來關注數據資源的運轉、使用和效益。第二,數據不僅僅是技術,企業急需組建有經濟學家參與的核心團隊來研發運營數據產品和數據資產。第三,每一家企業都有大量的上游和下游數據應用,企業的數據往往比自己所認知價值大得多,數字化數據化企業的業務并運營好數據資產具有重大的投資價值。
2021年4月29日至5月1日,裴健教授與論文的其他作者還將在SDM (SIAM International Conference on Data Mining ,SIAM數據挖掘國際會議)上進行演講,對論文內容進行解讀。























