我的內存怎么不夠用了?
- 為什么內存不夠用?
- 交換(Swap)技術
- 虛擬內存
- 頁(Page)和頁表
- MMU
- 頁表條目
- 大頁面問題
內存是稀缺的,隨著應用使用內存也在膨脹。當程序越來復雜,進程對內存的需求會越來越大。從安全角度考慮,進程間使用內存需要隔離。另外還有一些特殊場景,存在不希望 CPU 進行緩存的場景。這個時候,有一個虛擬化層承接各種各樣的訴求,統一進行處理,就會有很大的優勢。
為什么內存不夠用?
要理解一個技術,就必須理解它為何而存在。總體來說,虛擬化技術是為了解決內存不夠用的問題,那么內存為何不夠用呢?
主要是因為程序越來越復雜。比如說我現在給你錄音的機器上就有 200 個進程,目前內存的消耗是 21G,我的內存是 64G 的,但是多開一些程序還是會被占滿。另外,如果一個程序需要使用大的內存,比如 1T,是不是應該報錯?如果報錯,那么程序就會不好寫,程序員必須小心翼翼地處理內存的使用,避免超過允許的內存使用閾值。以上提到的這些都是需要解決的問題,也是虛擬化技術存在的價值和意義。
那么如何來解決這些問題呢?歷史上有過不少的解決方案,但最終沉淀下的是虛擬化技術。接下來我為你介紹一種歷史上存在過的 Swap 技術以及虛擬化技術。
交換(Swap)技術
Swap 技術允許一部分進程使用內存,不使用內存的進程數據先保存在磁盤上。注意,這里提到的數據,是完整的進程數據,包括正文段(程序指令)、數據段、堆棧段等。輪到某個進程執行的時候,嘗試為這個進程在內存中找到一塊空閑的區域。如果空間不足,就考慮把沒有在執行的進程交換(Swap)到磁盤上,把空間騰挪出來給需要的進程。
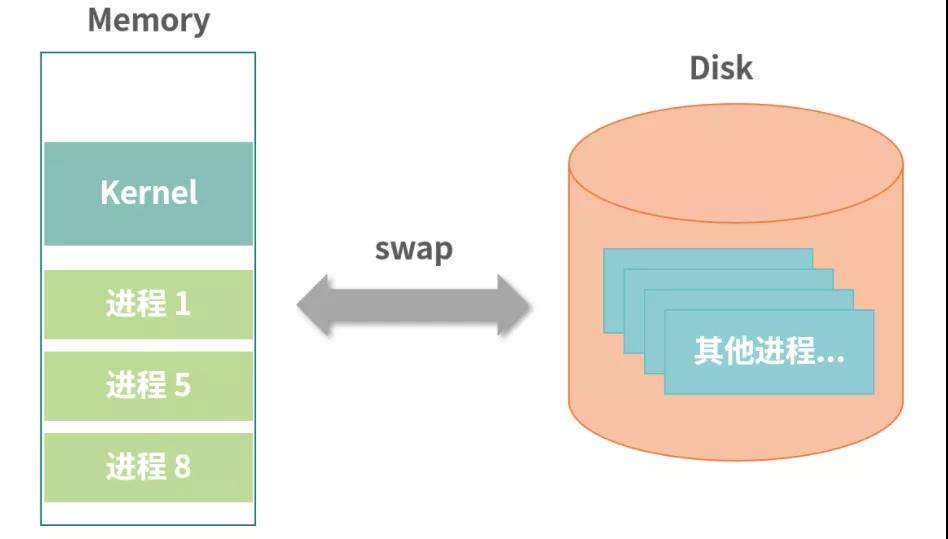
上圖中,內存被拆分成多個區域。內核作為一個程序也需要自己的內存。另外每個進程獨立得到一個空間——我們稱為地址空間(Address Space)。你可以認為地址空間是一塊連續分配的內存塊。每個進程在不同地址空間中工作,構成了一個原始的虛擬化技術。
比如:當進程 A 想訪問地址 100 的時候,實際上訪問的地址是基于地址空間本身位置(首字節地址)計算出來的。另外,當進程 A 執行時,CPU 中會保存它地址空間的開始位置和結束位置,當它想訪問超過地址空間容量的地址時,CPU 會檢查然后報錯。
上圖描述的這種方法,是一種比較原始的虛擬化技術,進程使用的是基于地址空間的虛擬地址。但是這種方案有很多明顯的缺陷,比如:
- 碎片問題:上圖中我們看到進程來回分配、回收交換,內存之間會產生很多縫隙。經過反反復復使用,內存的情況會變得十分復雜,導致整體性能下降。
- 頻繁切換問題:如果進程過多,內存較小,會頻繁觸發交換。
首先重新 Review 下我們的設計目標。
- 隔離:每個應用有自己的地址空間,互不影響。
- 性能:高頻使用的數據保留在內存中、低頻使用的數據持久化到磁盤上。
- 程序好寫(降低程序員心智負擔):讓程序員不用關心底層設施。
現階段,Swap 技術已經初步解決了問題 1。
關于問題 2,Swap 技術在性能上存在著碎片、頻繁切換等明顯劣勢。
關于問題3, 使用 Swap 技術,程序員需要清楚地知道自己的應用用多少內存,并且小心翼翼地使用內存,避免需要重新申請,或者研發不斷擴容的算法——這讓程序心智負擔較大。
經過以上分析,需要更好的解決方案,就是我們接下來要學習的虛擬化技術。
虛擬內存
虛擬化技術中,操作系統設計了虛擬內存(理論上可以無限大的空間),受限于 CPU 的處理能力,通常 64bit CPU,就是 264 個地址。
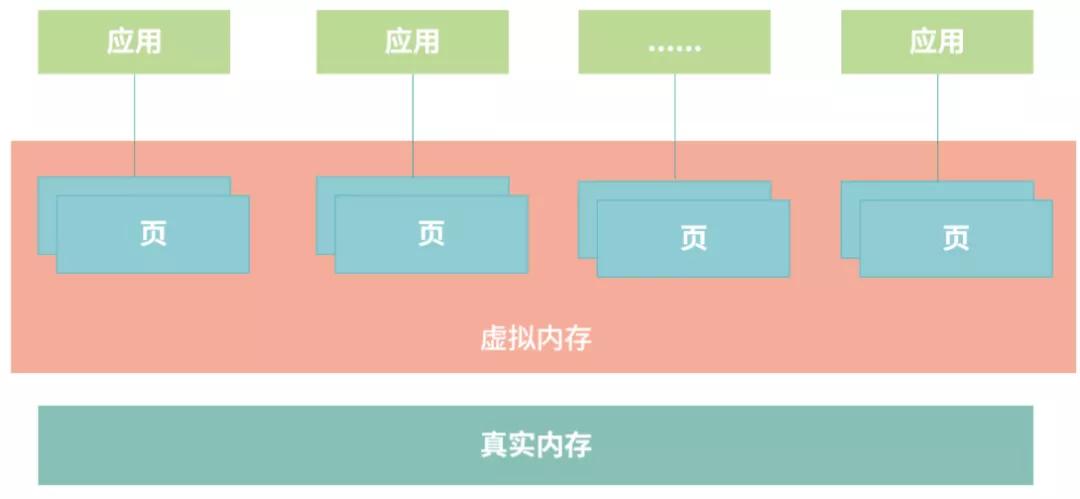
虛擬化技術中,應用使用的是虛擬內存,操作系統管理虛擬內存和真實內存之間的映射。操作系統將虛擬內存分成整齊小塊,每個小塊稱為一個頁(Page)。之所以這樣做,原因主要有以下兩個方面。
一方面應用使用內存是以頁為單位,整齊的頁能夠避免內存碎片問題。
另一方面,每個應用都有高頻使用的數據和低頻使用的數據。這樣做,操作系統就不必從應用角度去思考哪個進程是高頻的,僅需思考哪些頁被高頻使用、哪些頁被低頻使用。如果是低頻使用,就將它們保存到硬盤上;如果是高頻使用,就讓它們保留在真實內存中。
如果一個應用需要非常大的內存,應用申請的是虛擬內存中的很多個頁,真實內存不一定需要夠用。
頁(Page)和頁表
接下來,我們詳細討論下這個設計。操作系統將虛擬內存分塊,每個小塊稱為一個頁(Page);真實內存也需要分塊,每個小塊我們稱為一個 Frame。Page 到 Frame 的映射,需要一種叫作頁表的結構。
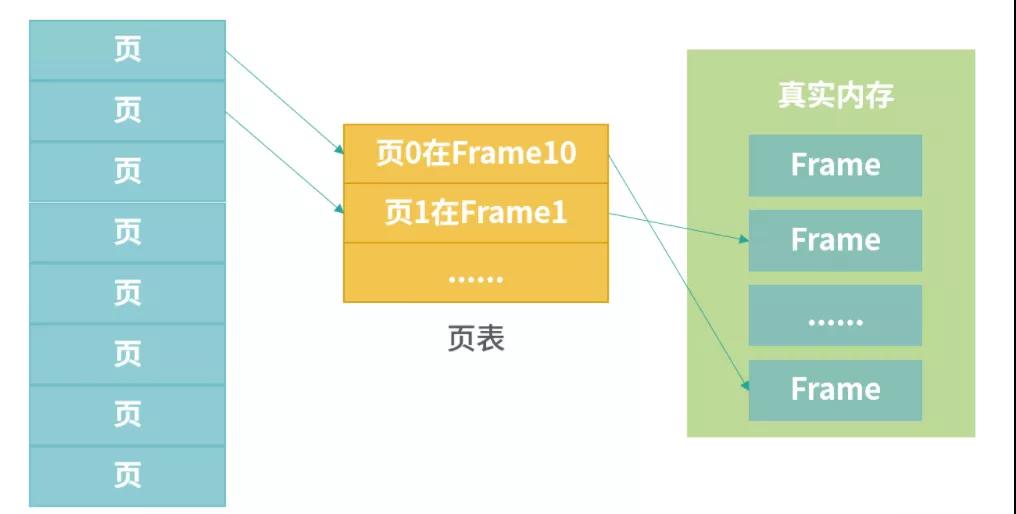
上圖展示了 Page、Frame 和頁表 (PageTable)三者之間的關系。Page 大小和 Frame 大小通常相等,頁表中記錄的某個 Page 對應的 Frame 編號。頁表也需要存儲空間,比如虛擬內存大小為 10G, Page 大小是 4K,那么需要 10G/4K = 2621440 個條目。如果每個條目是 64bit,那么一共需要 20480K = 20M 頁表。操作系統在內存中劃分出小塊區域給頁表,并負責維護頁表。
頁表維護了虛擬地址到真實地址的映射。每次程序使用內存時,需要把虛擬內存地址換算成物理內存地址,換算過程分為以下 3 個步驟:
- 通過虛擬地址計算 Page 編號;
- 查頁表,根據 Page 編號,找到 Frame 編號;
- 將虛擬地址換算成物理地址。
下面我通過一個例子給你講解上面這個換算的過程:如果頁大小是 4K,假設程序要訪問地址:100,000。那么計算過程如下。
頁編號(Page Number) = 100,000/4096 = 24 余1619。24 是頁編號,1619 是地址偏移量(Offset)。
查詢頁表,得到 24 關聯的 Frame 編號(假設查到 Frame 編號 = 10)。
換算:通常 Frame 和 Page 大小相等,替換 Page Number 為 Frame Number 物理地址 = 4096 * 10 + 1619 = 42579。
MMU
上面的過程發生在 CPU 中一個小型的設備——內存管理單元(Memory Management Unit, MMU)中。如下圖所示:
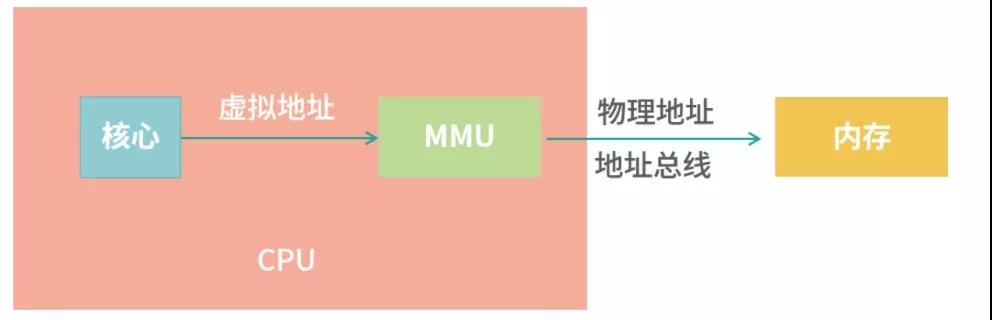
當 CPU 需要執行一條指令時,如果指令中涉及內存讀寫操作,CPU 會把虛擬地址給 MMU,MMU 自動完成虛擬地址到真實地址的計算;然后,MMU 連接了地址總線,幫助 CPU 操作真實地址。
這樣的設計,就不需要在編寫應用程序的時候擔心虛擬地址到物理地址映射的問題。我們把全部難題都丟給了操作系統——操作系統要確定MMU 可以讀懂自己的頁表格式。所以,操作系統的設計者要看 MMU 的說明書完成工作。
難點在于不同 CPU 的 MMU 可能是不同的,因此這里會遇到很多跨平臺的問題。解決跨平臺問題不但有繁重的工作量,更需要高超的編程技巧,Unix 最初期的移植性(跨平臺)是 C 語言作者丹尼斯·里奇實現的。
MMU 需要查詢頁表(這是內存操作),而 CPU 執行一條指令通過 MMU 獲取內存數據,難道可以容忍在執行一條指令的過程中,發生多次內存讀取(查詢)操作?難道一次普通的讀取操作,還要附加幾次查詢頁表的開銷嗎?當然不是,這里還有一些高速緩存的設計,這部分后面還可以繼續討論。
頁表條目
上面我們籠統介紹了頁表將 Page 映射到 Frame。那么,頁表中的每一項(頁表條目)長什么樣子呢?下圖是一個頁表格式的一個演示。
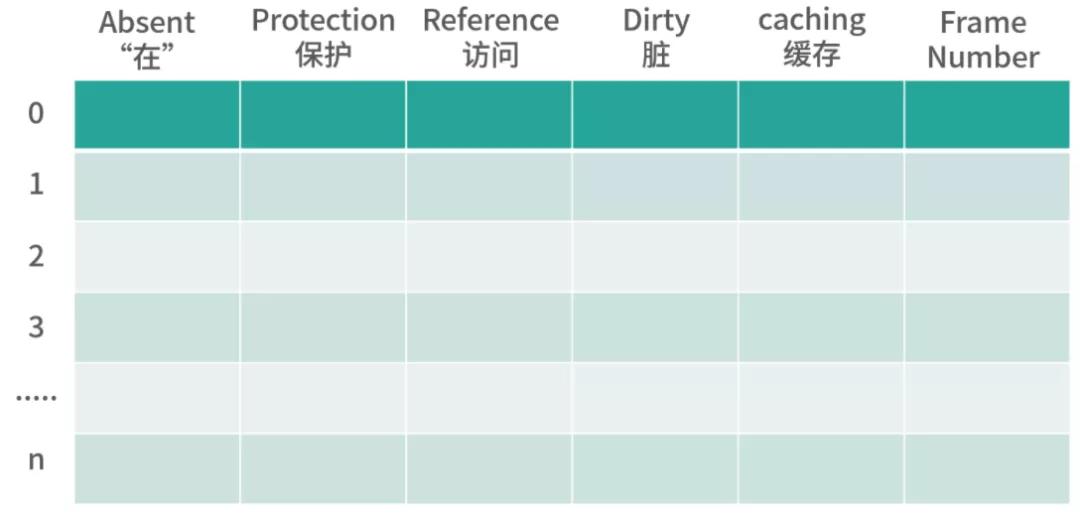
頁表條目本身的編號可以不存在頁表中,而是通過偏移量計算。比如地址 100,000 的編號,可以用 100,000 除以頁大小確定。
- Absent(“在”)位,是一個 bit。0 表示頁的數據在磁盤中(不再內存中),1 表示在內存中。如果讀取頁表發現 Absent = 0,那么會觸發缺頁中斷,去磁盤讀取數據。
- Protection(保護)字段可以實現成 3 個 bit,它決定頁表用于讀、寫、執行。比如 000 代表什么都不能做,100 代表只讀等。
- Reference(訪問)位,代表這個頁被讀寫過,這個記錄對回收內存有幫助。
- Dirty(“臟”)位,代表頁的內容被修改過,如果 Dirty =1,那么意味著頁面必須回寫到磁盤上才能置換(Swap)。如果 Dirty = 0,如果需要回收這個頁,可以考慮直接丟棄它(什么也不做,其他程序可以直接覆蓋)。
- Caching(緩存位),描述頁可不可以被 CPU 緩存。CPU 緩存會造成內存不一致問題,在上個模塊的加餐中我們討論了內存一致性問題,具體你可以參考“模塊四”的加餐內容。
Frame Number(Frame 編號),這個是真實內存的位置。用 Frame 編號乘以頁大小,就可以得到 Frame 的基地址。
在 64bit 的系統中,考慮到 Absent、Protection 等字段需要占用一定的位,因此不能將 64bit 都用來描述真實地址。但是 64bit 可以尋址的空間已經遠遠超過了 EB 的級別(1EB = 220TB),這已經足夠了。在真實世界,我們還造不出這么大的內存呢。
大頁面問題
最后,我們討論一下大頁面的問題。假設有一個應用,初始化后需要 12M 內存,操作系統頁大小是 4K。那么應該如何設計呢?
為了簡化模型,下圖中,假設這個應用只有 3 個區域(3 個段)——正文段(程序)、數據段(常量、全局變量)、堆棧段。一開始我們 3 個段都分配了 4M 的空間。隨著程序執行,堆棧段的空間會繼續增加,上不封頂。
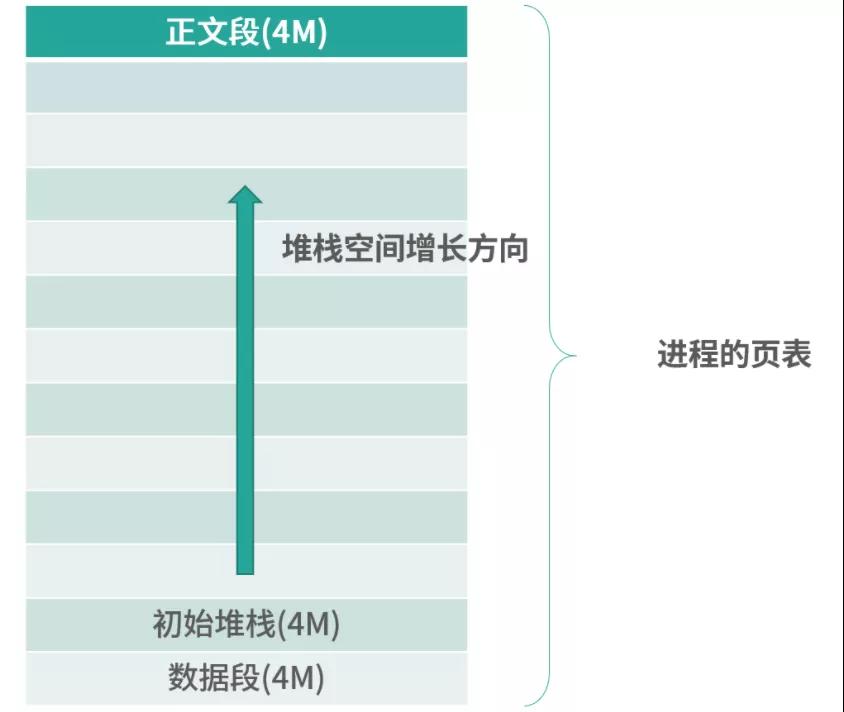
上圖中,進程內部需要一個頁表存儲進程的數據。如果進程的內存上不封頂,那么頁表有多少個條目合適呢?進程分配多少空間合適呢?如果頁表大小為 1024 個條目,那么可以支持 1024*4K = 4M 空間。按照這個計算,如果進程需要 1G 空間,則需要 256K 個條目。我們預先為進程分配這 256K 個條目嗎?創建一個進程就劃分這么多條目是不是成本太高了?
為了減少條目的創建,可以考慮進程內部用一個更大的頁表(比如 4M),操作系統繼續用 4K 的頁表。這就形成了一個二級頁表的結構,如下圖所示:

這樣 MMU 會先查詢 1 級頁表,再查詢 2 級頁表。在這個模型下,進程如果需要 1G 空間,也只需要 1024 個條目。比如 1 級頁編號是 2, 那么對應 2 級頁表中 [2* 1024, 3*1024-1] 的部分條目。而訪問一個地址,需要同時給出一級頁編號和二級頁編號。整個地址,還可以用 64bit 組裝,如下圖所示:

MMU 根據 1 級編號找到 1 級頁表條目,1 級頁表條目中記錄了對應 2 級頁表的位置。然后 MMU 再查詢 2 級頁表,找到 Frame。最后通過地址偏移量和 Frame 編號計算最終的物理地址。這種設計是一個遞歸的過程,因此還可增加 3 級、4 級……每增加 1 級,對空間的利用都會提高——當然也會帶來一定的開銷。這對于大應用非常劃算,比如需要 1T 空間,那么使用 2 級頁表,頁表的空間就節省得多了。而且,這種多級頁表,頂級頁表在進程中可以先只創建需要用到的部分,就這個例子而言,一開始只需要 3 個條目,從 256K 個條目到 3 個,這就大大減少了進程創建的成本。