如何通過Serverless提高Java微服務治理效率?
本文轉(zhuǎn)載自微信公眾號「Serverless」,作者王科懷(行松)。轉(zhuǎn)載本文請聯(lián)系Serverless公眾號。
微服務治理面臨的挑戰(zhàn)
在業(yè)務初期,因人手有限,想要快速開發(fā)并上線產(chǎn)品,很多團隊使用單體的架構來開發(fā)。但是隨著公司的發(fā)展,會不斷往系統(tǒng)里面添加新的業(yè)務功能,系統(tǒng)越來越龐大,需求不斷增加,越來越多的人也會加入到開發(fā)團隊,代碼庫也會增速的膨脹,慢慢的單體應用變得越來越臃腫,可維護性和靈活性逐漸降低,維護成本越來越高。
這個時候很多團隊會把單體應用架構改為微服務的架構,解決單體應用的問題。但隨著微服務越來越多,運維投入會越來越大,需要保證幾十甚至幾百個服務正常運行與協(xié)作,這給運維帶來了很大的挑戰(zhàn),下面從軟件生命周期的角度來分析這些挑戰(zhàn):
- 開發(fā)測試態(tài)
- 如何實現(xiàn)開發(fā)、測試、線上環(huán)境隔離?
- 如何快速調(diào)試本地變更?
- 如何快速部署本地變更?
- 發(fā)布態(tài)
- 如何設計服務發(fā)布策略?
- 如何無損下線舊版本服務?
- 如何實現(xiàn)對新版本服務灰 度測試?
- 運行態(tài)
- 線上問題如何排查?有什么工具可以利用呢?
- 對于服務質(zhì)量差的節(jié)點如何處理?
- 對于完全不工作的實例我們?nèi)绾位謴?
面對以上問題,Serverless 應用引擎在這方面都做了哪些工作?
Serverless 應用引擎
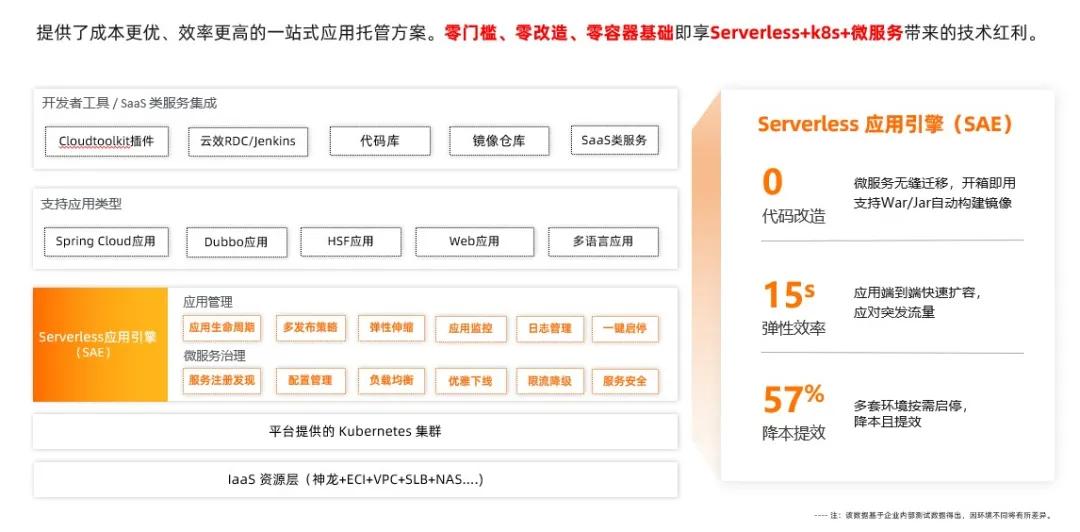
如上圖所示,Serverless 應用引擎(SAE)基于神龍 + ECI + VPC + SLB + NAS 等 IaaS 資源,構建了一個 Kubernetes 集群,在此之上提供了應用管理和微服務治理的一些能力。它可以針對不同應用類型進行托管,比如 Spring Cloud 應用、Dubbo 應用、HSF 應用、Web 應用和多語言應用。并且支持 Cloudtoolkit 插件、云效 RDC / Jenkins 等開發(fā)者工具。在 Serverless 應用引擎上,零代碼改造就可以把 Java 微服務的應用遷移到 Serverless。
總的來說,Serverless 應用引擎能夠提供成本更優(yōu)、效率更高的一站式應用托管方案,零門檻、零改造、零容器基礎,即可享受 Serverless + K8s + 微服務帶來的技術紅利。
微服務治理實踐
1. 開發(fā)態(tài)實踐
1)多環(huán)境管理
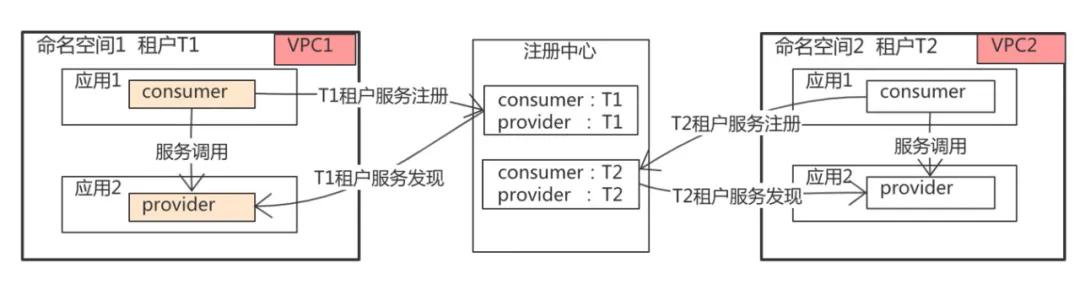
- 多租戶共有一個注冊中心,通過不同的租戶對流量進行隔離;更進一步可以通過網(wǎng)絡 VPC 進行環(huán)境隔離;
- 提供環(huán)境級別的運維操作,比如一鍵停止和拉起整個環(huán)境的功能;
- 提供環(huán)境級別的配置管理;
- 提供環(huán)境級別的網(wǎng)關路由流量管理。
2)云端聯(lián)調(diào)
Serverless 應用引擎(SAE)基于 Alibaba CloudToolkit 插件+ 跳板機可以實現(xiàn):
- 本地服務訂閱并注冊到云端 SAE 內(nèi)置的注冊中心;
- 本地服務可以和云端 SAE 服務互相調(diào)用。
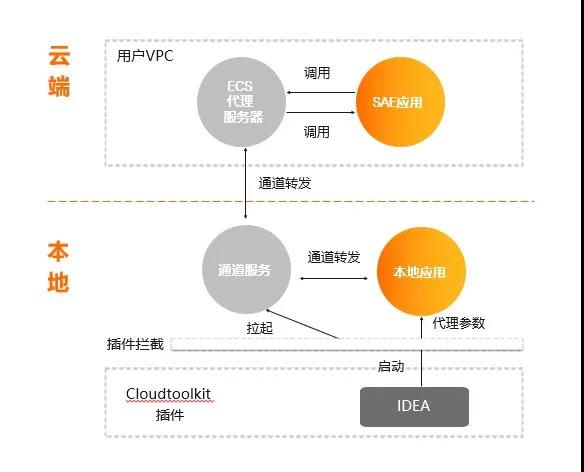
如上圖所示,在實現(xiàn)的時候用戶需要有一個 ECS 代理服務器,實際注冊的是 ECS 代理服務器到 SAE 的注冊中心,IDEA 在安裝 Cloudtoolkit 插件以后,在啟動進程時,會在本地拉起一個通道服務,這個通道服務會連上 ECS 代理服務器,本地所有的請求都會轉(zhuǎn)到 ECS 代理服務器上,云端對服務的調(diào)用也會通過 ECS 代理轉(zhuǎn)到本地,這樣就可以以最新的代碼在本地斷點調(diào)試,這就是云端聯(lián)調(diào)的實現(xiàn)。
3)構建快速開發(fā)體系
代碼在本地完成聯(lián)調(diào)以后,要能快速地通過 Maven 插件和 IDEA-plugin,可以很快地一鍵部署到云端的開發(fā)環(huán)境。
2. 發(fā)布態(tài)實踐
1)應用發(fā)布三板斧

- 可灰度:應用在發(fā)布的過程中,運維平臺一定要有發(fā)布策略,包括單批、分批、金絲雀等發(fā)布策略;同時還要支持流量的灰度;批次間也要允許自動/手動任選。
- 可觀測:發(fā)布過程可監(jiān)控,白屏化實時查看發(fā)布的日志和結果,及時定位問題。
- 可回滾:允許人工介入控制發(fā)布流程:異常中止、一鍵回滾。
通過這三點可以讓應用發(fā)布做到可灰度、可觀測、可回滾。
2)微服務無損下線
在版本更換的過程中,SAE 是如何保證舊版本的微服務流量可以無損地下線掉?
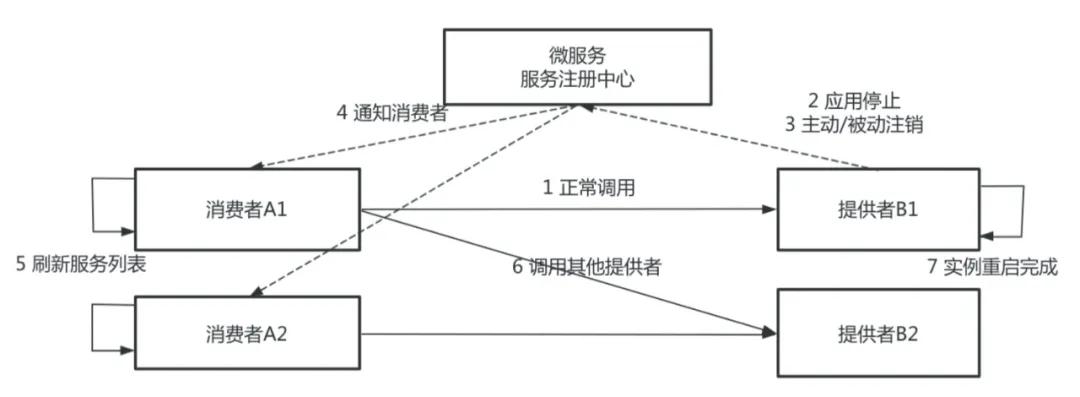
上圖是微服務注冊和發(fā)行的整個流程,圖中有服務消費者和服務提供者,服務提供者分別有 B1、B2 兩臺實例,服務消費者分別有 A1、A2 兩臺實例。
B1、B2 把自己注冊到注冊中心,消費者從注冊中心刷新服務列表,發(fā)現(xiàn)服務提供者 B1、B2,正常情況下,消費者開始調(diào)用 B1 或者 B2,服務提供者 B 需要發(fā)布新版本,先對其中一個節(jié)點進行操作,如 B1,首先停止 Java 進程,服務停止過程又分為主動銷毀和被動銷毀,主動銷毀是準實時的,被動銷毀的時間由不同的注冊中心決定,最差的情況可能需要一分鐘。
如果應用是正常停止,Spring Cloud 和 Dubbo 框架的 ShutdownHook 能正常被執(zhí)行,這一步的耗時基本上是可以忽略不計的。如果應用是非正常停止,比如說直接 Kill-9 的一個停止,或者是 Docker 鏡像構建的時候,Java 進程不是一號進程,且沒有把 Kill 信號傳遞給應用的話,那么服務提供者不會主動去注銷節(jié)點,它會等待注冊中心去發(fā)現(xiàn)、被動地去感知服務下線的過程。
當微服務注冊中心感知到服務下線以后,會通知服務消費者其中一個服務節(jié)點已下線,這里有兩種方式:注冊中心的推送和消費者的輪巡。注冊中心刷新服務列表,感知到提供者已經(jīng)下線一個節(jié)點,這一步對于 Dubbo 框架來說不存在,但對于 Spring Cloud 來說,它最差的刷新時間是 30 秒。等消費者的服務列表更新以后,就不再調(diào)用下線節(jié)點 B。從第 2 步到第 6 步的過程中,注冊中心如果是 Eureka,最差的情況需要消耗兩分鐘;如果是 Nacos,最差的情況需要消耗 50 秒。
在這個時間內(nèi)請求都有可能出現(xiàn)問題,所以發(fā)布的時候會出現(xiàn)各種報錯。
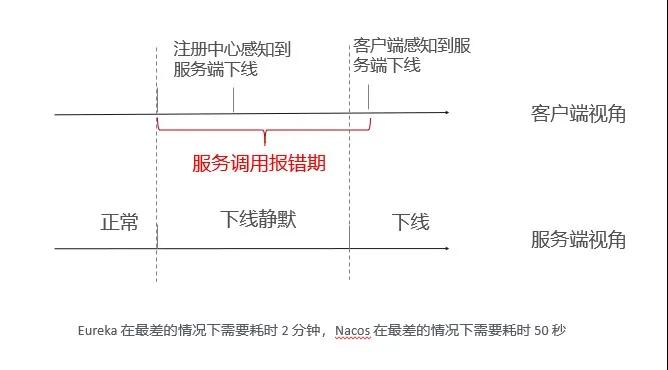
經(jīng)過上面的分析,在傳統(tǒng)的發(fā)布流程中,客戶端有一個服務端調(diào)用報錯期,這是由于客戶端沒有及時感知到服務端下線的實例造成的,這種情況主要是因為服務提供者借助微服務,通知消費者來更新服務提供的列表造成的。
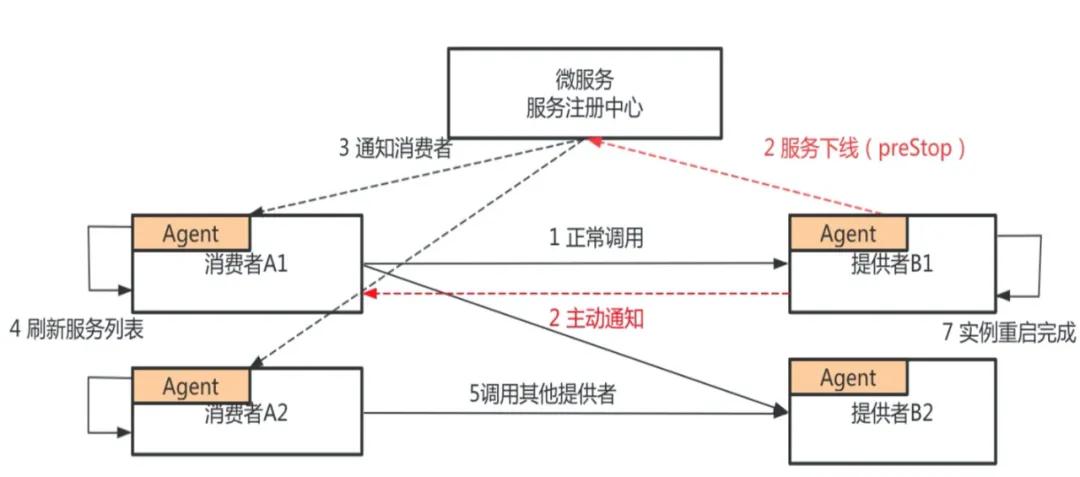
那能否繞過注冊中心,服務提供者直接通知服務消費者?答案是肯定的。SAE 做了兩件事情,第一,服務提供者在應用發(fā)布前,會主動向服務注冊中心注銷應用,并將應用標記為已下線狀態(tài),將原來停止進程階段的注銷變成了 preStop 階段注銷進程。
在接收到服務消費者的請求時,首先會正常處理本次請求,并且通知服務消費者此節(jié)點已經(jīng)下線,在此之后消費者收到通知后,會立即刷新自己的服務列表,在此之后服務消費者就不會再把請求發(fā)到服務提供者 B1 的實例上。
通過上面這個方案,就使得下線感知時間大大縮短,從原來的分鐘級別做到準實時的,確保你的應用在下線時能夠做到業(yè)務無損。
3)基于標簽的灰度發(fā)布
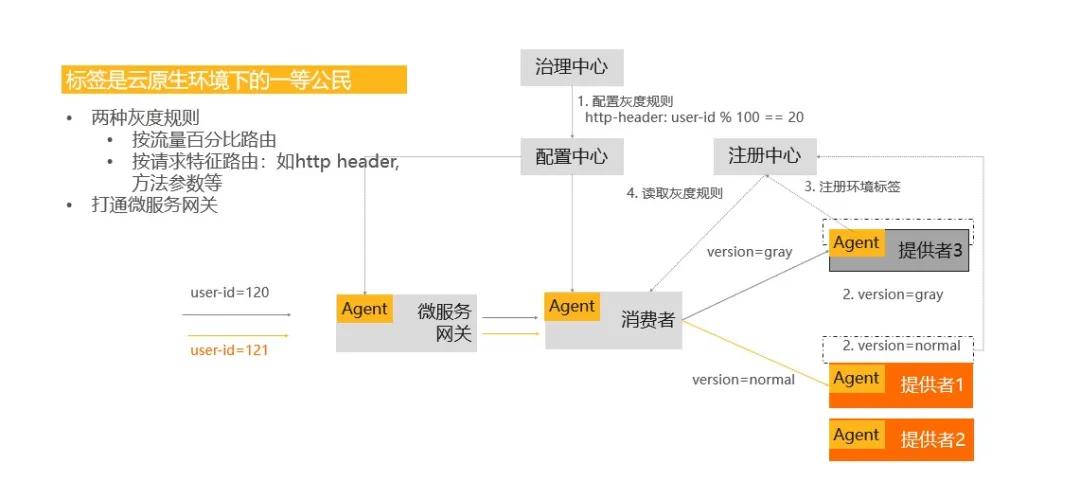
發(fā)布策略分為分批發(fā)布和灰度發(fā)布,如何實現(xiàn)流量的灰度?從上面的架構圖中可以看到,在應用發(fā)布之前,要配置一個灰度規(guī)則,比如按 uid 的取模余值 =20 來作為灰度流量的規(guī)則,當應用發(fā)布的時候,會對已發(fā)布的節(jié)點標識為一個灰度的版本,在這樣的情況下,當有流量進來時,微服務網(wǎng)關和消費者都會通過配置中心拿到在治理中心配置的灰度規(guī)則。
消費者的 Agent 也會從注冊中心拉取它所依賴的服務的一些信息,當一個流量進到消費者時,會按照灰度規(guī)則來做匹配,如果是灰度的流量,它會轉(zhuǎn)化到灰度的機器上;如果是正常流量,它會轉(zhuǎn)到正常的機器上,這是基于標簽實現(xiàn)的灰度發(fā)布的具體邏輯。
3. 運行態(tài)實踐
1)強大的應用監(jiān)控 & 診斷能力
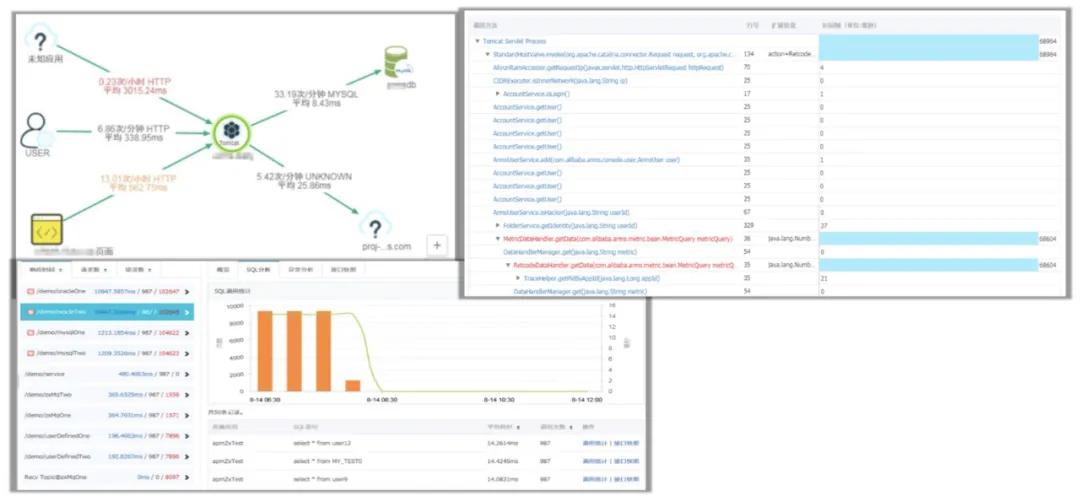
運行態(tài)的實例,服務的運行過程中會出現(xiàn)這樣或者那樣的問題,怎么去排查和解決它?
排查和解決的前提是必須具有強大的應用監(jiān)控能力和診斷能力,SAE 集成了云產(chǎn)品 ARMS,能夠讓跑在上面的 Java 微服務看到應用的調(diào)用關系拓撲圖,可以定位到你的 MySQL 慢服務方法的調(diào)用堆棧,進而定位到代碼級別的問題。
比如一個請求響應慢,業(yè)務出現(xiàn)問題,它可以定位到是哪個請求、哪個服務、服務的哪行代碼出現(xiàn)了問題,這樣就能為解決問題帶來很多便利。總的來說,就是我們要先有監(jiān)控報警的能力,才能幫助我們更好地診斷服務運營過程中的問題。
2)故障隔離和服務恢復
上面說到我們通過監(jiān)控、報警來排查、解決遇到的問題,那我們的系統(tǒng)能否主動去做一些事情呢?SAE 作為一個 Serverless 平臺,具備很多自運維的能力,下圖中有兩個場景:

- 場景1:某應用運營過程中,某幾臺機器由于磁盤滿或者宿主機資源爭搶,導致 load 很高或網(wǎng)絡狀態(tài)差,客戶端出現(xiàn)調(diào)用超時或者報錯。
面對這種情況,SAE 提供了服務治理能力,即離群摘除,它可以配置,當網(wǎng)絡超時嚴重或者后端服務 5xx 報錯達到一定比例時,可以選擇把該節(jié)點從消費端服務列表中摘除,從而使得有問題的機器不再響應業(yè)務的請求,很好地保證業(yè)務的 SLA。
- 場景2:某應用運行過程中,因突發(fā)流量導致內(nèi)存耗盡,觸發(fā) OOM。
這種情況下,通過 SAE 這種 Serverless 應用引擎,節(jié)點在配置健康檢查以后,節(jié)點里的容器是可以重新拉起的,可以做到快速對進程進行恢復。
3)精準容量+限流降級+極致彈性
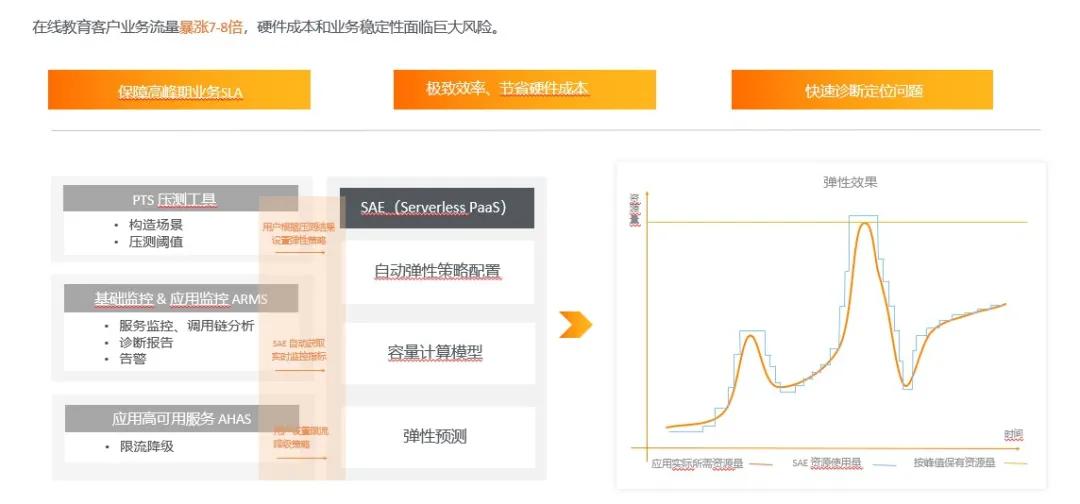
基于 Serverless Paas 平臺 SAE 和其他產(chǎn)品的互動,來達到整個運維態(tài)的閉環(huán)。
用戶在使用的時候,可以運用 PTS 壓測工具構造場景,然后得出來一些閾值。比如可以對流量高峰所需要消耗的資源進行預估,這時就可以根據(jù)這些閾值設計彈性策略。當業(yè)務系統(tǒng)達到請求比例時,就可以按照所設置的彈性策略來擴縮容自己的機器。
擴縮容在時間上,有可能還跟不上處理大批量的請求,這時可以通過和 AHAS 的互動,配置限流降級的能力。當有突發(fā)大流量時,首先可以用 AHAS 的能力把一些流量擋在門外,然后同時觸發(fā) SAE 上應用的擴容策略去擴容實例,當這些實例擴容完成之后,整個機器的平均負載會下降,流量又重新放進來。從突發(fā)大流量到限流降級再到擴容,最后到流量達到正常狀態(tài),這就是“精準容量+限流降級+極致彈性”的最佳實踐模型。
總結
本文首先按照提出問題、解決問題的思路,闡述微服務在開發(fā)、發(fā)布和運行態(tài)是如何解決問題的;再介紹如何通過 Serverless 產(chǎn)品和其他產(chǎn)品的互動,從而實現(xiàn)精準流量、限流降級和極致彈性。
- 開發(fā)測試態(tài)
- 通過注冊中心多租戶和網(wǎng)絡環(huán)境的隔離,并提供環(huán)境級別的能力;
- 通過云端聯(lián)調(diào)技術來快速調(diào)式本地變更;
- 如果 IDE 插件快速部署本地變更。
- 發(fā)布態(tài)
- 運維平臺針對應用發(fā)布需要具備可灰度、可觀測、 可回滾;
- 通過 MSE agent 能力實現(xiàn)服務無損下線;
- 通過標簽路由提供了線上流量灰度測試的能力。
- 運行態(tài)
- 建立強大應用監(jiān)控和診斷能力;
- 對服務質(zhì)量差的節(jié)點具備離群摘除能力;
- 對已經(jīng)不工作的實例通過配置健康檢查能夠做到實例重啟恢復業(yè)務;
- 提供了精準容量+限流降級+極致彈性模型。
作者簡介:王科懷,花名:行松,阿里云 SAE 技術研發(fā),負責 SAE 產(chǎn)品 Runtime 層技術架構設計,專注于微服務、Serverless、應用托管領域,基于云原生技術持續(xù)打造新一代應用托管平臺。