Hinton發布最新論文,表達神經網絡中部分-整體層次結構
2017年,深度學習三巨頭之一的Geoffrey Hinton,發表了兩篇論文解釋「膠囊網絡(Capsule Networks)」。
在當時,這是一種全新的神經網絡,它基于一種新的結構——膠囊,在圖像分類上取得了更優越的性能,解決了CNN的某些缺陷,例如無法理解圖片和語義關系、沒有空間分層和空間推理的能力等。
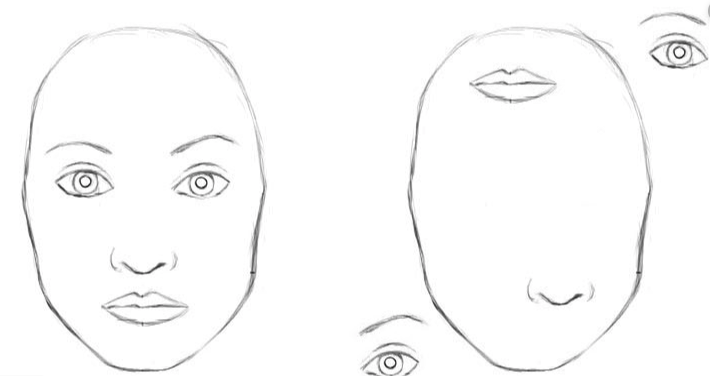
在CNN中,左右兩幅圖都可被網絡識別為人臉
甚至,Hinton自己也公開表示過,他要證明為何卷積神經網絡完全是「垃圾」,應該以自己的膠囊網絡代替。
過去三年中,他每年都會推出一個新版本的膠囊網絡。
本月,Hinton興奮地說道,自己發表了一篇新論文,名為如何在神經網絡中表示部分-整體層次結構?(How to represent part-whole hierarchies in a neural network)
本論文中,他提出了一個叫做GLOM的架構,可以在神經網絡中使用膠囊來表示視覺的層次結構,即部分-整體的關系。
署名只有Hinton一人。

GLOM通過提出island的概念來表示解析樹的節點。GLOM可以顯著提升transformer類的模型的可解釋性。可以顯著提升transformer類的模型的可解釋性。
提出island,GLOM表示解析樹的節點
有強有力的心理學證據表明,人們將視覺場景解析成部分-整體的層次結構,并將部分和整體之間相對不變的視覺關系,建模為部分和整體之間的坐標變換。
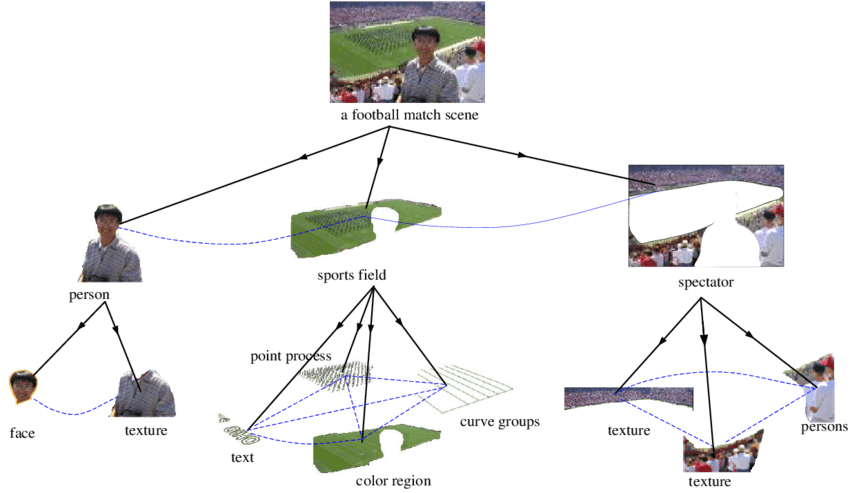
如果做出能和人們一樣理解圖像的神經網絡,我們就需要弄清楚,神經網絡如何才能表示部分-整體的層次結構?
這是很困難的,不同圖像有不同的結構,而傳統的神經網絡無法把固定輸入的圖像轉換為動態的層次結構(解析樹)。
而這,也是「膠囊模型」被提出的動機。
這些模型做出了這樣的假設:一個膠囊就是一組神經元,每個膠囊對應表示圖片特定位置的一個目標。
然后可以通過激活這些預先存在的、特定類型的膠囊,并在他們之間建立適當連接來創建一棵解析樹。
本文介紹了一種非常不同的方式,即在神經網絡中使用膠囊來表示部分-整體的層次結構。
需要注意的是,論文沒有描述一個工作系統。
相反,它提出了一個關于表征的單一想法,將幾個不同小組取得的進展合并到一個名為GLOM的假想系統中。
盡管本文主要關注對單一靜態圖像的感知,但GLOM很容易被理解為一個處理幀序列的流水線。靜態圖像可以被認為是多個相同幀組成的序列。
GLOM架構,顯著提升transformer類的模型的可解釋性
GLOM架構由大量的列組成,這些列都使用完全相同的權重。
每一列都是一個空間局部自動編碼器的堆棧,可以學習小圖像補丁中發生的多層次的表示。每個自動編碼器,使用多層自下而上的編碼器和解碼器,將一級的嵌入轉化為相鄰一級的嵌入。這些層次對應于部分-整體層次結構中的層次。
例如,當顯示一個人臉的圖像時,一個列可能會聚集為一個向量,用來表示鼻孔、鼻子、臉和人。
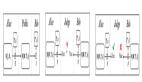
下圖顯示了不同層次的嵌入如何在單列中相互作用。
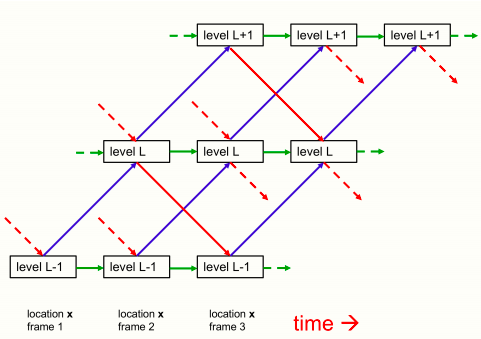
單列GLOM架構中相鄰三層之間自下而上、自上而下、同層交互的情況
其中,藍色箭頭和紅色箭頭分別代表自下而上和自上而下的交互方式,由兩個不同的神經網絡實現的,并且網絡中可以存在隱藏層。
對于一張靜態圖片來說,綠色箭頭可以簡化為殘差鏈接用來實現時序的平滑效果。對于視頻這種包含多幀序列的情況,綠色箭頭的連接轉為一個神經網絡用來學習時序過程中的膠囊狀態的變化。
不同列中同一層次的嵌入向量之間的交互作用,由一個非自適應的、注意力加權的局部平滑器來實現,這一點沒有在圖片中畫出來。這比列內的交互要簡單得多,因為它們不需要實現部分整體坐標變換。它們就像多頭Transformer中代表不同單詞片段的列之間的注意力加權交互,但它們更簡單,因為query、key和value都與嵌入向量相同。
列間相互作用通過使某一層次的每個嵌入向量向附近位置的其他類似向量回歸,在某一層次產生相同嵌入的島。這就形成了多個局部的「回聲室」,在這個「回聲室」中,一個層次的嵌入物主要關注其他相似的嵌入物。
在每一個離散的時間點和每個列中,一個層次的embedding更新為下列四方面的加權平均:
1 由自下而上的神經網作用于下層的embedding在上一時間步產生的預測
2 由自上而下的神經網在上一級的embedding上作用于上一時間步產生的預測
3 前一個時間步長的embedding向量
4 前一時間步相鄰列中同層次的embedding的注意力加權平均值
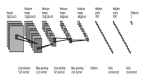
對于一個靜態圖像來說,隨著時間的推移,一個層面的嵌入應該會穩定下來,產生幾乎相同的向量的獨特島,如下圖所示:
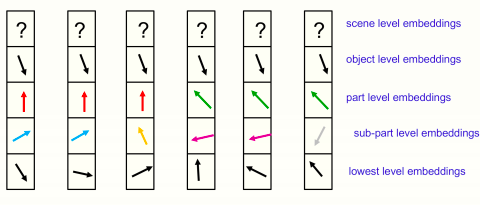
附近六列中某一特定時間的嵌入圖片
所有顯示的位置都屬于同一個對象,場景層面還沒有確定一個共享矢量。將每個位置的完整嵌入向量分為部分-整體層次結構中每個層次的獨立部分,然后將一個層次的高維嵌入向量作為二維向量顯示出來。
這樣就可以說明,不同位置的嵌入向量的排列情況。圖中所示的各級相同向量的島代表一棵分析樹。
GLOM沒有分配神經硬件來表示解析樹中的一個節點,也沒有給節點指向其前面和后面的指針,而是分配一個合適的活動向量來表示該節點,并對屬于該節點的所有位置使用相同的活動向量。訪問節點的先后能力是由自下而上和自上而下的神經網絡來實現的,而不是用RAM來做表查找。
像BERT一樣,整個系統可以在最后一個時間步進行訓練,從有缺失區域的輸入圖像中重建圖像,但目標函數還包括兩個正則化器,鼓勵在每個層次上有接近相同向量的島。
簡單來說,正則器只是新的嵌入在一個層面上與自下而上和自上而下的預測之間的保持一致的一種方法,這有利于形成局部島。
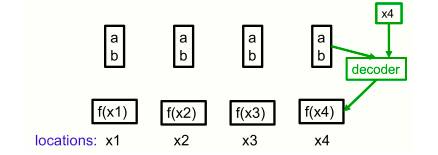
一個非常簡單的神經場的例子,使用單個像素作為位置。四個像素的強度都可以用同一個代碼(a,b)來表示,即使它們的強度根據函數f(x) = ax+b而變化。解碼器有一個額外的輸入,它指定了位置。
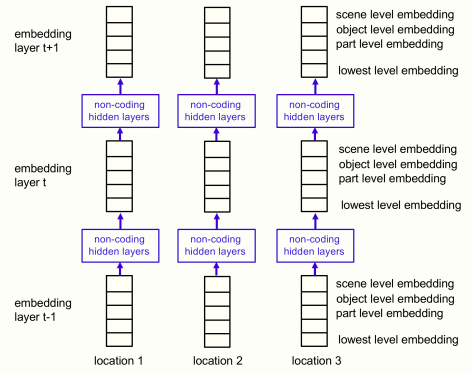
GLOM架構的另一種可視化方法
這是GLOM架構所示架構的另一種可視化方式,顯示了用另一種方式看待GLOM架構的各個自下而上和自上而下的神經網。
在這里,該架構與Transformer的關系更加明顯。文中第一個圖代表時間的水平維度變成了本圖中代表層次的垂直維度。
在每個位置,每個層現在都有部分-整體層次結構中所有層次的嵌入。這相當于在圖1中垂直壓縮了單個時間片內的層次描述。通過這個架構的一次正向傳遞就可以解釋靜態圖像。這里將所有特定級別的自下而上和自上而下的神經網都顯示為單個神經網。
在正向傳遞過程中,L層的嵌入向量通過多層自下而上的神經網接收來自上一層中L-1層嵌入向量的輸入。
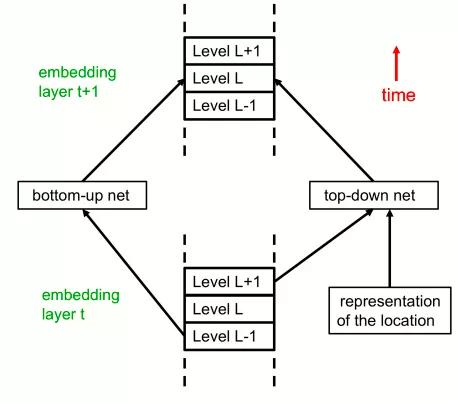
它還通過多層自上而下的神經網絡接收來自上一層中L+1級嵌入的輸入。在前向傳遞過程中,對前一層中L+1級的依賴性實現了自上而下的效果。層t+1中的L級嵌入也取決于層t中的L級嵌入和層t中其他附近位置的L級嵌入的注意力加權和,這些層內交互作用沒有顯示出來。
最后,研究人員還對GLOM與其他神經網絡模型(例如膠囊模型,變壓器模型,卷積神經網絡等)相比,存在的優勢作出了分析。
論文發表在https://arxiv.org/abs/2102.12627上。