













讓我們一起揭秘代碼效率真相
本文轉載自微信公眾號「程序喵大人」,作者程序喵大人 。轉載本文請聯系程序喵大人公眾號。
大家好,我是逐漸過氣的程序喵。
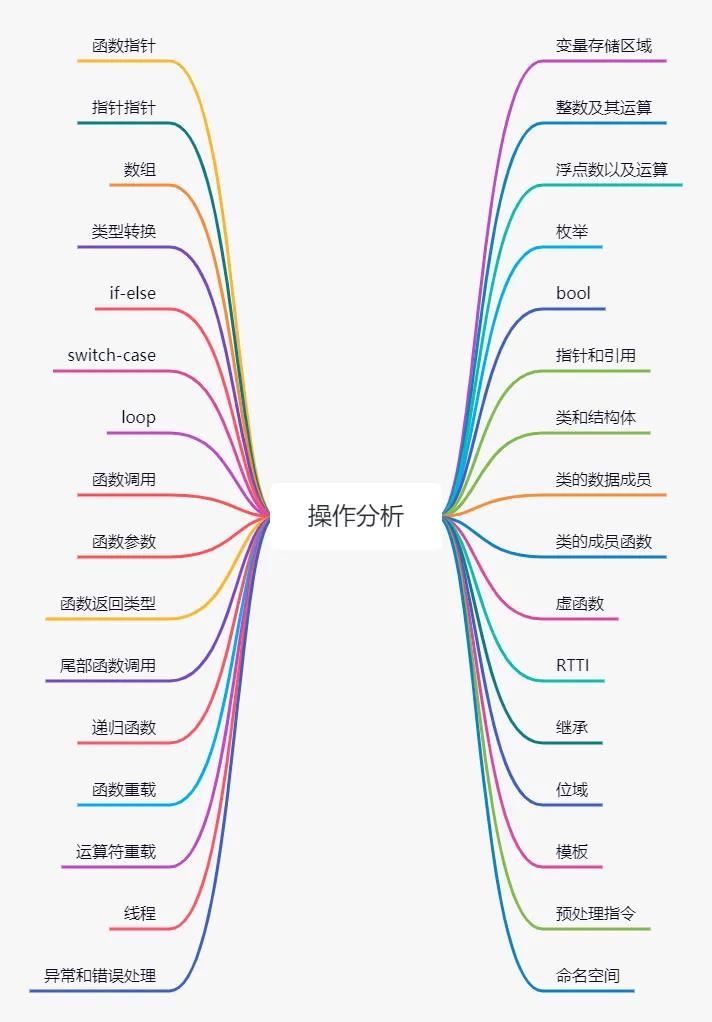
本篇文章我們將繼續分析C++各種操作的效率,包括不同類型變量的存儲效率,使用智能指針、循環、函數參數、虛函數、數組等的效率,以及如何做針對性優化,或選擇更有效的替代方案。
詳細目錄看下圖:
類和結構體
現今流行面向對象編程,個人也認為這是一種使代碼更加清晰和模塊化的方法。面向對象編程風格優缺點明顯,優點是:
- 如果變量是同一結構體或類的成員,則一起使用的變量也存儲在一塊,這樣數據緩存更有效。
- 類成員變量不需要作為參數傳遞給類成員函數,省去了參數傳遞的開銷。
缺點是:
- 一些程序員把代碼分成太多的小類,沒太大必要且效率低。
- 非靜態成員函數有一個this指針,它會作為隱式參數傳遞給函數,這會產生一部分開銷,特別是在32位系統中,寄存器是稀缺資源,this指針會占用一個寄存器。
- 虛函數效率較低
類和成員函數的開銷其實并沒有特別大,如果面向對象風格可以使程序結構更加清晰,我們只要避免在程序最關鍵的部分使用太多的函數調用,就不要擔心它的開銷。
類的數據成員
當創建類或結構體的實例時,其數據成員按其聲明的順序連續存儲。大多數編譯器都會對結構體進行內存對齊,這種對齊可能會在成員大小混合的結構體或類中,造成未使用字節的空洞。
- struct S1 {
- short int a; // 2字節
- // 6個空洞
- double b; // 8
- int d; // 4
- // 4個空洞
- };
- S1 ArrayOfStructures[100];
這里,在a和b之間有6個未使用的字節,因為b必須從一個能被8整除的地址開始。最后還有4個未使用的字節。這樣做的原因是,數組中S1的下一個實例必須從一個能被8整除的地址開始,以便將其b成員以8對齊。通過將最小的成員放在最后,未使用的字節數可以減少到2:
- struct S1 {
- double b; // 8
- int d; // 4
- short int a; // 2
- // 2個空洞
- };
- S1 ArrayOfStructures[100];
這種重新排序使結構變小了8個字節,整個數組變小了800個字節。
通過重新排序數據成員,結構對象和類對象通常可以變小。如果不確定一個結構或它的每個成員有多大,可以使用sizeof,它的返回值包括對象末尾的任何未使用的字節。
如果成員相對于結構體或類開頭的偏移量小于128,則訪問數據成員的代碼會更緊湊,因為該偏移量可以表示為8位有符號的數字。如果相對于結構體或類的開頭的偏移量是128字節或更大,那么偏移量必須表示為一個32位數字(指令集在8位到32位之間沒有偏移量)。例如:
- struct S2 {
- int a[100]; // 400
- int b; // 4
- int ReadB() {return b;}
- };
b的偏移量是400。任何通過指針或成員函數(如ReadB)訪問b的代碼,都需要將偏移量編碼為32位數字。如果交換了a和b,則兩者都可以通過編碼為8位有符號數字的偏移量來訪問,或者根本沒有偏移量。這使代碼更緊湊,以便更有效地使用Cache。因此,建議在結構或類聲明中,大數組和其他大對象排在最后,最常用的數據成員排在前面。如果不能在前128個字節內包含所有數據成員,則將最常用的成員放在前128個字節中。
類的成員函數
每次聲明或創建類的新對象時,都會生成數據成員的新實例。但無論多少類的實例,成員函數只有一份。調用成員函數和使用結構指針或引用來調用簡單函數一樣快。
- struct S3 {
- int a;
- int b;
- int Sum1() {return a + b;}
- };
- int Sum2(S3* p) {return p->a + p->b;}
- int Sum3(S3& r) {return r.a + r.b;}
這三個函數Sum1, Sum2和Sum3,做的是完全相同的事情,而且它們的效率是一樣的。有些編譯器會為這三個函數生成完全相同的代碼。Sum1有一個隱式的this指針,它和Sum2和Sum3中的p和r做同樣的事情。讓函數成為類的成員,還是給它一個指向類或結構的指針或引用,這只是編程風格的問題。一些編譯器通過在寄存器中傳輸this指針,使Sum1在32位Windows中比Sum2和Sum3更有效率。
靜態成員函數不能訪問任何非靜態數據成員或非靜態成員函數。靜態成員函數比非靜態成員函數更快,因為它不需要this指針。如果成員函數,它不需要任何非靜態成員訪問,可以通過將它們設為靜態函數來加快速度。
虛函數
虛函數用于實現運行時多態,多態是面向對象編程相對于非面向對象編程效率低的主要原因之一。如果可以避免虛函數的使用,那可以提高程序的運行效率,一般情況下,可以考慮使用編譯時多態替代運行時多態。關于虛函數為什么導致程序效率低,可以看我之前的文章:《》
RTTI
RTTI,運行時類型識別,會向所有類對象添加額外的信息,所以效率不高,可以考慮關閉RTTI選項來提高程序效率。
繼承
派生類對象的實現方式,與包含父類和子類成員的簡單類對象相同。父類和子類的成員訪問速度相同。通常,我們可以認為使用繼承幾乎不會對性能造成任何損失。
然而這些情況下,效率稍微會有所下降:
- 子類包括父類的所有數據成員,即便子類不需要父類的數據成員。
- 父類數據成員的大小添加到子類成員的偏移量中。訪問總偏移量大于127字節的數據成員的代碼稍微不那么緊湊。
繼承多個父類,可能會導致指向基類指針訪問派生類的對象時更復雜。我們可以通過在派生類中創建對象來避免多重繼承,即組合替代繼承:
- class B1;
- class B2;
- class D : public B1, public B2 {
- public:
- int c;
- };
換成這樣:
- class B1;
- class B2;
- class D : public B1 {
- public:
- B2 b2;
- int c;
- };
一般來說,只有當繼承對程序的邏輯結構有利時,才應該使用繼承。
位域
位可以使數據更加緊湊。訪問位成員比訪問結構體的普通成員效率低。如果大的數組可以以此來節省代碼空間,那么稍微犧牲點效率也未嘗不可。
使用<<和|操作組合位字段比單獨編寫成員更快。例如:
- struct Bitfield {
- int a:4;
- int b:2;
- int c:2;
- };
- Bitfield x;
- int A, B, C;
- x.a = A;
- x.b = B;
- x.c = C;
假設A、B和C的值太小,不會導致溢出,可以通過以下方式改進這段代碼:
- union Bitfield {
- struct {
- int a:4;
- int b:2;
- int c:2;
- };
- char abc;
- };
- Bitfield x;
- int A, B, C;
- x.abc = A | (B<<4) | (C<<6);
如果需要防止溢出可以這樣:
- x.abc = (A & 0x0F) | ((B & 3) << 4) | ((C & 3) <<6 );
函數重載
重載的函數,只是作為不同的函數來處理,和普通函數相同,沒有任何性能代價,可放心使用。
運算符重載
重載運算符等同于函數。使用重載運算符與使用普通函數的效率完全相同。帶有多個重載運算符的表達式,會導致為中間結果創建臨時對象,這樣效率較低。例如:
- class vector {
- public:
- float x, y;
- vector() {}
- vector(float a, float b) {x = a; y = b;}
- vector operator + (vector const &a) {
- return vector(x+a.x, y+a.y);
- }
- };
- vector a, b, c, d;
- a = b + c + d; // 產生了中間對象(b+c)
可以通過加入以下操作來避免為中間結果(b+c)創建臨時對象:
- a.x = b.x + c.x + d.x;
- a.y = b.y + c.y + d.y;
在簡單情況下,大多數編譯器可能會自動進行這種優化。
模板
在編譯之前,模板的參數被它們的值所替換,這一點上,模板與宏相似。下面的例子說明了函數參數和模板參數的區別:
- // Example 7.46
- int Multiply (int x, int m) {
- return x * m;
- }
- template <int m>
- int MultiplyBy (int x) {
- return x * m;
- }
- int a, b;
- a = Multiply(10,8);
- b = MultiplyBy<8>(10);
a和b都會得到值10 * 8 = 80。區別在于m傳遞到函數的方式。在這個簡單函數中,m在運行時從調用方轉移到被調用方。但是在模板函數中,m的值在編譯時就被替換,這樣編譯器看到的是常量8而不是變量m。
模板參數相對于使用函數參數的優點是避免了參數傳遞的開銷,缺點是編譯器需要為模板參數的每個不同值創建一個模板函數的新實例。如果在這個例子中,用許多不同的因子作為模板參數調用MultiplyBy,那么生成的代碼可能會變得非常大。
在上例中,模板函數比簡單函數快,因為編譯器知道它可以通過使用移位操作乘以2的冪。x*8被替換為x<<3,這樣更快。在簡單函數的情況下,編譯器不知道m的值,因此不能進行優化,除非函數可以內聯。(在上面的例子中,編譯器能夠內聯和優化這兩個簡單的函數函數,將80存于a和b中。但在更復雜的情況下,它可能做不了這種優化)。
模板參數也可以是類型,想必大家也經常使用這種類型不同的模板吧。模板之所以高效,是因為模板參數總是在編譯時解析。模板使源代碼更復雜,但不會使編譯后的代碼更復雜。一般來說,使用模板在運行速度方面沒有開銷。
如果模板參數完全相同,兩個或多個模板實例將被連接到一個模板實例中。如果模板參數不同,那么編譯器會為每組模板參數生成一個實例。帶有許多實例的模板會使編譯后的代碼變大。模板的過度使用,會使代碼難于閱讀。如果模板只有一個實例,我們可以使用#define、const或typedef來代替模板形參。
模板可實現編譯時多態,在某些情況下,我們可以使用編譯時多態替代運行時多態。
線程
線程想必大家都知道,充分利用多核系統的最佳方法,是將任務劃分為多個線程。然后,每個線程都可以在自己的CPU內核上運行。
在優化多線程程序時,需要考慮幾種開銷:
- 啟動和停止線程的成本:如果一個任務的執行時間,比它啟動和停止線程的時間還要短,那就不要把它放到單獨的線程中。
- 上下文切換的成本:如果線程數量不超過CPU的數量,開銷最小。
- 線程間同步和通信的成本。信號量、互斥鎖等的開銷相當大,如果兩個線程為了訪問同一資源而經常相互等待,那么最好將它們放到一個線程中。在多個線程之間共享的變量須聲明為volatile,這可以防止編譯器將該變量存儲在寄存器中,而該寄存器在線程之間不共享。
異常和錯誤處理
關于異常和錯誤處理我之前寫過一篇文章你的c++團隊還在禁用異常處理嗎?,大家可以看看,使用異常來處理錯誤是個很有效的方法,異常處理目的是以一種優雅的方式檢測很少發生的錯誤,并從錯誤情況中恢復。使用異常處理有些缺點我們需要知道:
- 打開exception選項會導致程序空間增大10%左右
- 帶有try-catch的代碼運行效率和普通代碼類似,但也肯定沒有普通代碼效率高(看編譯器優化的程度)
- 一旦發生異常,程序運行速度明顯下降
某些明確不會產生異常的函數可以考慮加noexcept修飾,讓編譯器進行最大程度的優化。
如果不需要從錯誤中恢復,則不需要進行異常處理,建議使用系統的、經過深思熟慮的方法來處理錯誤。
預處理指令
預處理指令,所有以#開頭的指令,在程序性能方面沒有任何開銷,因為它們是在程序編譯之前解析的。
#if指令對于支持使用同一源代碼的多個平臺或多個配置很有用。#if比if更高效,因為#if在編譯時解析,而if在運行時解析。
定義常量時,#define指令等價于const定義。例如,#define ABC 123和const int ABC = 123; 同樣有效,因為在大多數情況下,優化編譯器可以用整數常量的值替換整數常量。然而,在某些情況下,const int聲明可能占用內存空間,而#define指令則不會占用內存空間。使用宏有些時候比普通函數更有效。
命名空間
盡管使用命名空間吧,不用擔心,在速度方面沒有任何開銷。
上面分析了不同操作的效率以及如何針對性做一些優化,在網上我也找到了一個圖,圖里列出了不同的操作占用的CPU時鐘周期:

我們可以仔細看看上圖,在編碼時選擇效率更高的操作。
參考資料
https://www.agner.org/optimize/




















