xeus-sql:讓Jupyter支持SQL處理
現在用Jupyter進行數據處理,對數據工作者來說已經不是一個新鮮事情了。然而如何將大量數據導入卻是一個比較棘手的事情。大家都知道關系數據庫是數據存儲的最重要的載體,那么對數據庫的支持是Jupyter數據科學界一個迫切的需求。
此前Jupyter曾發布過一個內核xeus-sqlite允許用戶直接從notebook進行SQLite查詢。日前Jupyter新發布了一個新的項目xeus-sql,這是對xeus-sqlite的擴展,是Jupyter的通用數據庫訪問工具,使用它可以在絕大多數的關系數據庫上進行SQL查詢。
數據庫支持
xeus-sql支持市面上的絕大多數數據,包括:
- MySQL
- PostgreSQL的
- SQLite3
- DB2
- Oracle
- Firebird
以及支持ODBC驅動程序的任何數據庫。
為了提供所有這些集成,xeus-sql依賴SOCI庫作為項目的主干。SOCI在統一的C++ API之后抽象所有不同的數據庫連接和查詢詳細信息。xeus-sql使用SOCI和xeus將SQL功能公開給Jupyter。
安裝
為確保安裝正常進行,最好xeus在一個全新的conda環境中安裝。xeus-sql還需要使用miniconda安裝,完整的anaconda 可能會產生沖突。最安全的用法是創建一個以xeus-sqlminiconda安裝命名的環境:
- conda create -n xeus-sql
- conda activate xeus-sql
從conda安裝
Conda forge提供了MySQL,PostgreSQL和SQLite的打包版本,可以使用conda或mamba輕松安裝它們一鍵安裝,使用conda軟件包管理器安裝xeus-sql:
- conda install xeus-sql jupyterlab -c conda-forge
或者使用mamba:
- mamba install xeus-sql jupyterlab -c conda-forge
或者可以分別安裝:
- mamba install xeus-sql soci-mysql -c conda-forge
- mamba install xeus-sql soci-postgresql -c conda-forge
- mamba install xeus-sql soci-mysql -c conda-forge
不同的SQL后端之間存在一些差異,可以參考xeus-sql詳細文檔和示例學習。
使用方法
要連接MySQ,需要首先安裝xeus-sql和soci-mysql,然后用LOAD加載連接數據庫:
- %LOAD mysql db=dbname user=user1 password='Password123#@!'
上面db數據庫名稱,user為連庫用戶名,password為用戶密碼。
連接成功就可以執行數據庫命令和SQL語句,比如:
- show databases;
- SELECT * FROM test
- INSERT INTO example VALUES (2, 'Core')
- SELECT * FROM example
- INSERT INTO example VALUES (3, 'Table')
其他數據庫后端也類似:
firebird:
- %LOAD firebird service=firebird.fdb user=SYSDBA
postgresql:
- %LOAD postgresql dbname=newdvdrental
可視化查詢
對于熟悉可視化SQL表和查詢結果的表形式的用戶,Jupyter的豐富顯示系統提供了根據使用的應用程序將它們顯示為豐富文本顯示還是純文本顯示的選項。
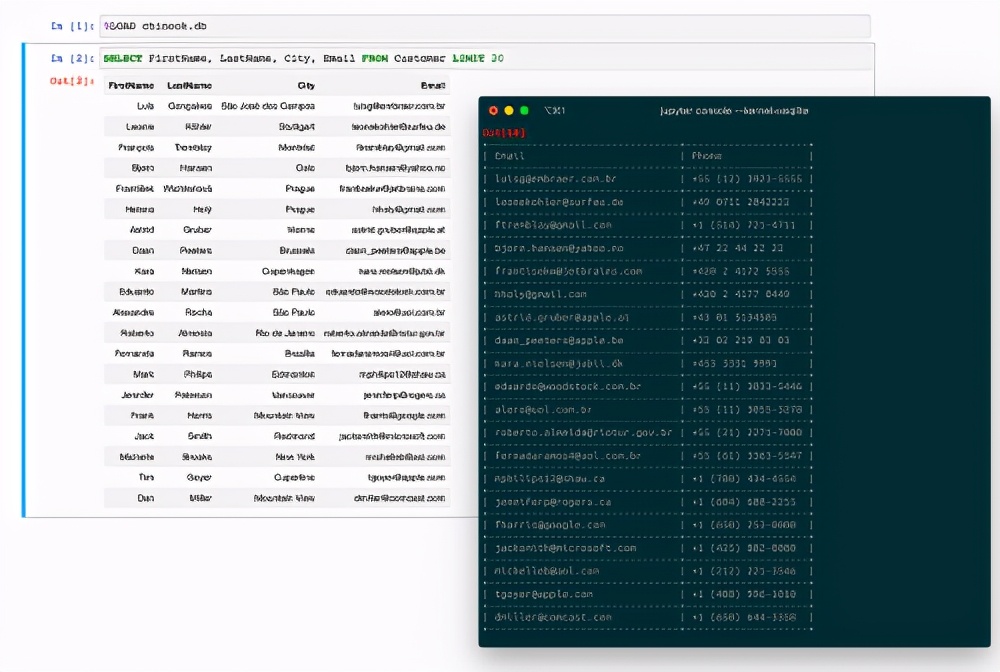
除了顯示帶有表的查詢之外,在還可以直接在Notebook中根據查詢結果輕松創建Vega-Lite圖形:
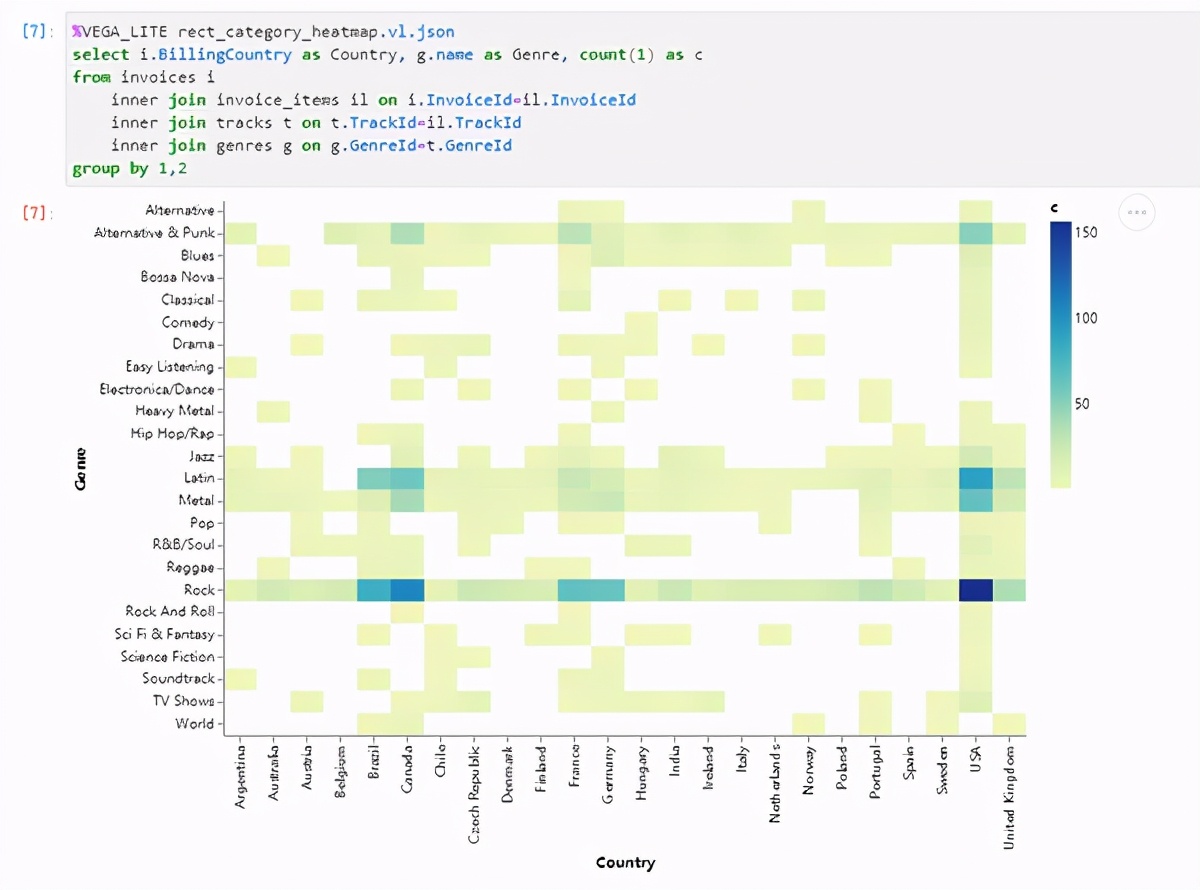
Vega-Lite是一個功能強大的庫可以使用xeus-sql從關系數據中創建許多不同的可視化文件。
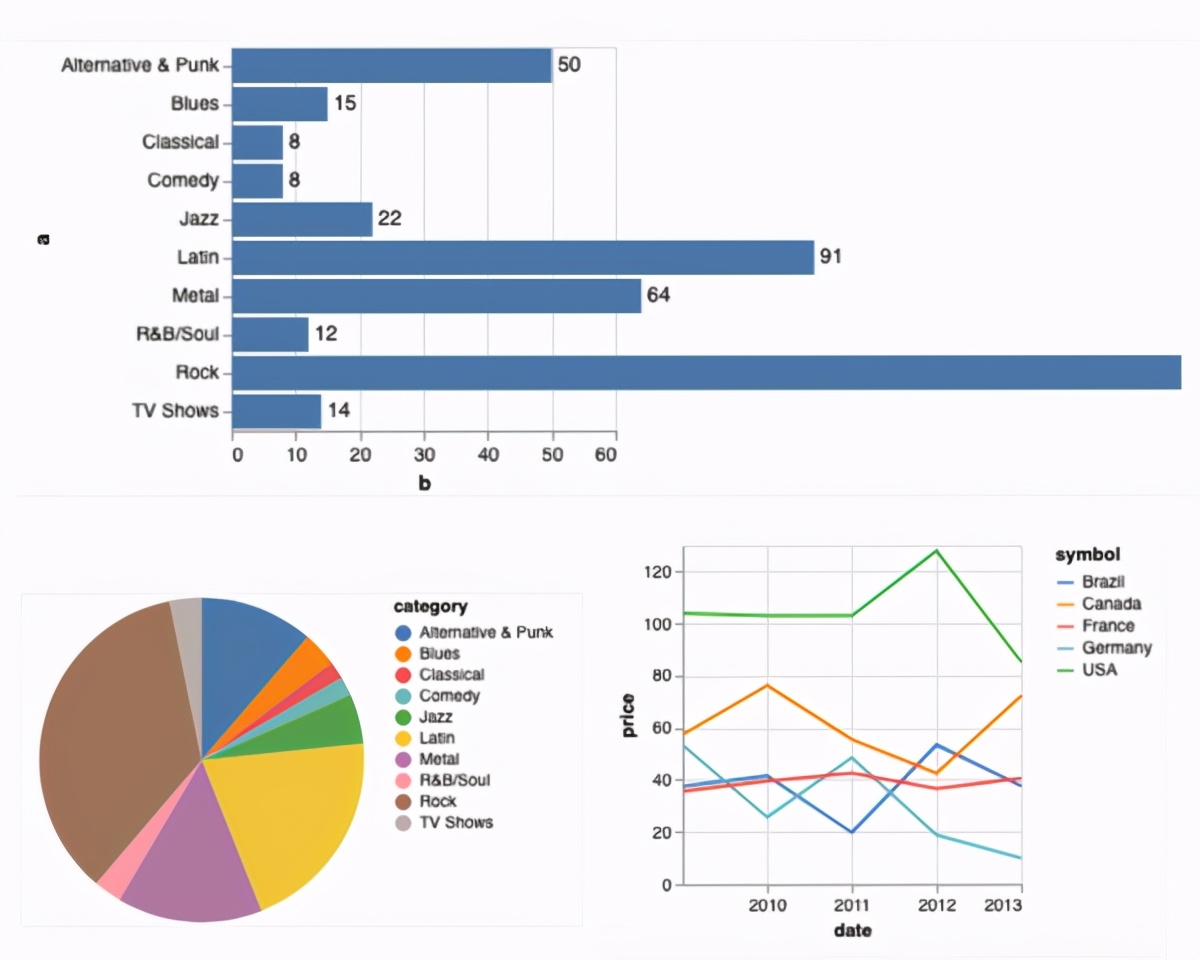
為了支持此功能,xeus-sql依賴于xvega(vega的C++后端)和定制的Jupyter魔術來繪制通過xvega-bindings實用程序庫中實現的微型語言。除了使用迷你語言之外,還可以直接提供可視化的JSON規范。
總結
xeus-sql的推出,讓Jupyter如虎添翼,可以非常方便數據工作者進行數據處理和可視化。同時對于傳統dba和數據庫用戶可以使用Jupyter作為一個便捷的數據庫客戶端。