













MySQL隨機(jī)恢復(fù)的幾個(gè)段位
對(duì)于MySQL數(shù)據(jù)恢復(fù)而言,其實(shí)很多時(shí)候都會(huì)有點(diǎn)兒不踏實(shí),大多數(shù)情況下備份恢復(fù)體系的建設(shè)是一氣呵成的,建設(shè)完善之后保持原樣,就很少干預(yù)和測(cè)試了,而一旦需要恢復(fù)的時(shí)候,才發(fā)現(xiàn)這也不好,那也不完善,輕則花費(fèi)重金恢復(fù),重則是職業(yè)生涯的終點(diǎn)。
所以我們?cè)跀?shù)據(jù)恢復(fù)的時(shí)候,我們特意完善了一個(gè)功能,那就是隨機(jī)恢復(fù),隨機(jī)恢復(fù)主要實(shí)現(xiàn)兩個(gè)功能:基于備份集恢復(fù)和基于時(shí)間點(diǎn)恢復(fù)。基于備份集恢復(fù)相對(duì)比較簡(jiǎn)單,就是什么時(shí)候做的備份,一定要恢復(fù)出來,而基于時(shí)間點(diǎn)會(huì)復(fù)雜一些,比如數(shù)據(jù)庫(kù)可以恢復(fù)到10:00:00,是需要實(shí)現(xiàn)精確到秒級(jí)的恢復(fù)能力,我們?cè)诖烁M(jìn)一步,生成一個(gè)隨機(jī)時(shí)間,然后讓服務(wù)按照指定的時(shí)間點(diǎn)進(jìn)行恢復(fù),每天大約會(huì)跑10個(gè)左右的任務(wù),都是隨機(jī)從服務(wù)組中抽取。
經(jīng)過一段時(shí)間的調(diào)整和驗(yàn)收,從50%左右的成功率不斷調(diào)整,到了現(xiàn)在的93%左右的成功率,我的初步要求是兩個(gè)9,這個(gè)標(biāo)準(zhǔn)提了一段時(shí)間了,從實(shí)踐的結(jié)果來看,這個(gè)標(biāo)準(zhǔn)要達(dá)成付出的代價(jià)和心血是很多的,遠(yuǎn)遠(yuǎn)不是看上去的那么輕松。
對(duì)此我對(duì)隨機(jī)恢復(fù)設(shè)置了3個(gè)段位,可以作為參考。
第一層級(jí):隨機(jī)抽樣+單機(jī)恢復(fù)
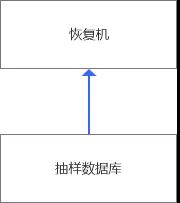
這一層級(jí)思路很簡(jiǎn)單,隨機(jī)從服務(wù)組中選取一個(gè)實(shí)例,到指定的恢復(fù)機(jī)恢復(fù),只要數(shù)據(jù)庫(kù)能夠正常啟動(dòng)則標(biāo)識(shí)成功,否則,如果因?yàn)閰?shù)兼容性,版本差異,空間瓶頸,插件問題等導(dǎo)致無法啟動(dòng),都會(huì)標(biāo)記為失敗。
當(dāng)然這種模式的缺點(diǎn)也很明顯,那就是隨機(jī)的模式,最尷尬的無非是同樣的實(shí)例被反復(fù)選中,或者全是大塊頭的實(shí)例,對(duì)恢復(fù)造成很大的壓力導(dǎo)致失敗,另外則是恢復(fù)機(jī)成為瓶頸,跨機(jī)房流量和空間限制,會(huì)導(dǎo)致單一的恢復(fù)機(jī)難以支撐更高的指標(biāo)要求,這也是早期難以突破1個(gè)9的主要原因。
第二層級(jí):隨機(jī)抽樣+多IDC節(jié)點(diǎn)負(fù)載均衡
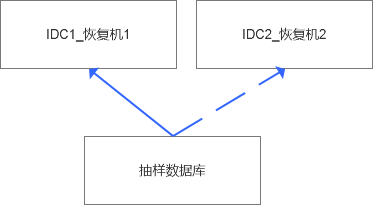
這種思路可操作性很強(qiáng),優(yōu)點(diǎn)會(huì)很明顯,原本的恢復(fù)任務(wù)可以隨機(jī)的分配在不同的IDC中,對(duì)于跨機(jī)房流量消耗是一種很大的改良,同時(shí)也可以大大提高隨機(jī)恢復(fù)的吞吐量,比如我們?cè)究梢耘?0個(gè)隨機(jī)恢復(fù)任務(wù),那么如果我們加到15個(gè)任務(wù)也可以說是輕輕松松。
第三層級(jí):隨機(jī)策略調(diào)度+多IDC負(fù)載均衡
這是我認(rèn)為目前改進(jìn)空間很大,能夠迭代進(jìn)入2個(gè)9的關(guān)鍵階段。可以從如下的方面考慮:
1)恢復(fù)服務(wù)器實(shí)現(xiàn)多版本插件式部署,對(duì)于恢復(fù)服務(wù)器而言,不需要默認(rèn)數(shù)據(jù)庫(kù)版本,所有差異化版本都是插件式目錄,可以快速構(gòu)建恢復(fù)服務(wù)器,提高恢復(fù)擴(kuò)展能力
2)根據(jù)恢復(fù)服務(wù)器的存儲(chǔ)和配置進(jìn)行定制化延遲啟動(dòng),比如有的服務(wù)器CPU配置好一些,啟動(dòng)數(shù)據(jù)庫(kù)快一些,有些數(shù)據(jù)庫(kù)啟動(dòng)要略慢一些,可以通過配置化實(shí)現(xiàn)延遲啟動(dòng)的問題,避免數(shù)據(jù)庫(kù)啟動(dòng)中的一些尷尬問題
3)大容量實(shí)例在指定服務(wù)器中調(diào)度恢復(fù),節(jié)省資源成本,比如有一個(gè)實(shí)例容量是800G,那么恢復(fù)機(jī)需要在900G左右,那么不是所有恢復(fù)服務(wù)器都需要900G,通常來說,這是極個(gè)別的現(xiàn)象,比如通用配置500G就足夠。
4)大容量的實(shí)例盡量減少調(diào)度頻率,如果一個(gè)實(shí)例的容量較大,恢復(fù)成本較高,那么我們可以有效恢復(fù)的基礎(chǔ)上調(diào)整恢復(fù)優(yōu)先級(jí)
5)未恢復(fù)的實(shí)例需要優(yōu)先調(diào)度,如果有1000個(gè)實(shí)例,如果經(jīng)過了很長(zhǎng)時(shí)間,恢復(fù)的覆蓋范圍始終覆蓋不了大多數(shù)實(shí)例,其實(shí)隨機(jī)恢復(fù)的設(shè)計(jì)是有問題的。需要照顧到那些沒有被調(diào)度到的實(shí)例
6)實(shí)現(xiàn)彈性調(diào)度,比如對(duì)于容量小的實(shí)例,恢復(fù)效率會(huì)快很多,那么我們勢(shì)必就可以增加這類實(shí)例的恢復(fù)數(shù)量,而如果選中的實(shí)例容量較大,則可以在時(shí)長(zhǎng),數(shù)量方面做一些調(diào)控。
第4層級(jí):根據(jù)統(tǒng)計(jì)學(xué)模型假設(shè)檢驗(yàn)
在第3層級(jí)的基礎(chǔ)上,達(dá)到了兩個(gè)9的前提下,第4個(gè)層級(jí)會(huì)把恢復(fù)轉(zhuǎn)化為一個(gè)通用問題,對(duì)于如何衡量恢復(fù)能力在沒法實(shí)現(xiàn)全量數(shù)據(jù)集恢復(fù)的前提下,可以基于統(tǒng)計(jì)學(xué)的模型進(jìn)行假設(shè)檢驗(yàn),最終的目的是通過一個(gè)有效樣本數(shù)據(jù)進(jìn)行統(tǒng)計(jì)量的評(píng)估和分析,這個(gè)部分的內(nèi)容理論深度其實(shí)沒那么復(fù)雜,是一種全新的思維邏輯去評(píng)估恢復(fù)質(zhì)量。
本文轉(zhuǎn)載自微信公眾號(hào)「 楊建榮的學(xué)習(xí)筆記」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請(qǐng)聯(lián)系 楊建榮的學(xué)習(xí)筆記公眾號(hào)。



















