













漫談序列化之使用、原理、問題
前言
天天跟我說給我介紹對象對象,對象在哪里?哪里有對象?
你倒是把對象拿給我看看啊!
拿去拿去 :
- {
- "name": "小麗",
- "age": "22",
- "sex": "女"
- }
我去~
序列化概念
說到對象,是一個比較寬泛的概念,簡單的說,他就是類的一個實例,有狀態和行為,存活在內存中,一旦JVM停止運行,對象的狀態也會丟失。
那么如何將這個對象當前狀態進行一個記錄,使其可以進行存儲和傳輸呢?這就要用到序列化了:
序列化 (Serialization)是將對象的狀態信息轉換為可以存儲或傳輸的形式的過程
比如一個User對象,名字為小麗,年齡22,性別為女。現在要把這個User對象保存下來,不然要是這個對象被別人改成了男可咋辦。
所以我們就可以把它當前的狀態信息轉化成一種固定的格式,比如json格式:
- {
- "name": "小麗",
- "age": "22",
- "sex": "女"
- }
所以上述的例子就是一個序列化過程,本身這個User對象存活在內存中,是無法直接進行數據持久化的,所以我們需要一些序列化的方式讓它可以進行保存傳輸:
比如xml、JSON、Protobuf、Serializable、Parcelable,這些都是可以進行序列化的方式。
所以關于序列化我們就有很多問題了:
- 在java有Serializable的前提下,Android為什么設計出了Parcelable?
- Parcelable一定比Serializable快嗎?
- 為什么Java提供了Serializable的序列化方式,而不是直接使用json或者xml?
- Serializable、Parcelable、Json等序列化方式我們該怎么選擇?
帶著這些問題,我們去看看序列化的世界。
Serializable
先說說Java中自帶的序列化方式——Serializable。
Serializable是java.io包中定義的、用于實現Java類的序列化操作而提供的一個語義級別的接口
只要我們實現Serializable接口,那么這個類就可以被ObjectOutputStream轉換為字節流,也就是進行了序列化。
使用
java:
- public class User implements Serializable {
- private static final long serialVersionUID=519067123721561165l;
- private int id;
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- }
kotlin:
- data class User(
- val id: Int
- ) : Serializable
這個變量如果不寫,系統也會自動生成。它的作用在于標示這個數據對象的一致性。
當序列化的時候,系統會把當前類的serialVersionUID寫入序列化的文件中,當反序列化的時候會去檢測這個serialVersionUID,看他是否和當前類的serialVersionUID一致,一樣則可以正常反序列化,如果不一樣就會報錯了。
如果我們不寫的話,在我們修改類的某些屬性之后,serialVersionUID就會改變。
所以我們手動指定serialVersionUID后,就能在修改類之后,讓系統認識序列化的過程中標示這是同一個類,從而保證最大限度來恢復數據。
原理
在Serializable的注釋中有提到,如果要想在序列化過程中做一些特殊的操作,可以實現這幾個特殊方法:
- writeObject(),負責寫入對象的特定類,以便相應的readObject方法可以恢復它
- readObject(),負責從流中讀取并恢復類字段
所以這兩個方法其實就是Serializable實現的關鍵。首先看看寫入方法writeObject(偽代碼):
- private void writeObject(){
- //獲取類的描述信息ObjectStreamClass(里面包含了類名稱、類字段、serialVersionUID等,用到大量反射)
- desc = ObjectStreamClass.lookup(cl, true);
- //寫入元數據TC_OBJECT,代表是一個新對象
- bout.writeByte(TC_OBJECT);
- //寫入描述信息(從父類寫到子類)
- writeClassDesc(desc, false);
- //寫入serialVersionUID,serialVersionUID為空的情況下,序列化機制就會調用一個函數根據類內部的屬性等計算出一個hash值
- getSerialVersionUID();
- //執行JVM的序列化操作
- defaultWriteFields();
- }
- private void defaultWriteFields(Object obj, ObjectStreamClass desc){
- //寫入基本數據類型
- bout.write(primVals, 0, primDataSize, false);
- //寫入引用數據類型(又重新調用了writeObject方法)
- Object[] objVals = new Object[desc.getNumObjFields()];
- for (int i = 0; i < objVals.length; i++) {
- writeObject(objVals[i],fields[numPrimFields + i].isUnshared());
- }
- }
寫入數據的流程基本就這些,可以看到Serializable序列化的過程,其實就是一個寫入流的過程。然后就可以根據情況將二進制流保持為文件,或者包裝成ByteArrayOutStream寫入到內存中進行傳輸。
所以Serializable使用的范圍比較廣,可以作為文件保存下來,也可以作為二進制流對象用于內存中的傳輸。但是由于用到反射、IO,而且大量的臨時變量會引起頻繁的GC,所以效率不算高。
所以,為了提高在Android中對象傳輸的效率呢,Android就采用了新的序列化方式——Parcelable。
Parcelable
Parcelable是Android為我們提供的序列化的接口,是為了解決Serializable在序列化的過程中消耗資源嚴重,而Android本身的內存比較緊缺的問題,但是用法較為繁瑣,主要用于內存中數據的傳輸。
使用
java:
- public class User implements Parcelable {
- private int id;
- protected User(Parcel in) {
- id = in.readInt();
- }
- @Override
- public void writeToParcel(Parcel dest, int flags) {
- dest.writeInt(id);
- }
- @Override
- public int describeContents() {
- return 0;
- }
- public static final Creator<User> CREATOR = new Creator<User>() {
- @Override
- public User createFromParcel(Parcel in) {
- return new User(in);
- }
- @Override
- public User[] newArray(int size) {
- return new User[size];
- }
- };
- public int getId() {
- return id;
- }
- public void setId(int id) {
- this.id = id;
- }
- }
- androidExtensions {
- experimental = true
- }
- @Parcelize
- data class User(val name: String) : Parcelable
原理
先說說Parcelable寫法中這幾個方法參數的意思:
- createFromParcel,User(Parcel in) ,代表從序列化的對象中創建原始對象
- newArray,代表創建指定長度的原始對象數組
- writeToParcel,代表將當前對象寫入到序列化結構中。
- describeContents,代表返回當前對象的內容描述。如果還有文件描述符,返回1,否則返回0。
好了,在了解Parcelable原理之前,我們先要了解下Parcel。
Parcel是一個容器,它主要用于存儲序列化數據,然后可以通過Binder在進程間傳遞這些數據
所以Parcel就是可以進行IPC通信的容器,同樣底層也是用到了Binder。(Binder在Android中真是無處不在啊)
- //寫入數據
- Parcel parcle = Parcel.Obtain();
- parcel.writeString(String val);
- //讀取數據
- parcel.setDataPosition(i);
- parcel.readString();
再往底層就是Binder的原理了,也就是將數據寫到內核的共享內存中,然后其他進程可以從共享內存中進行讀取。
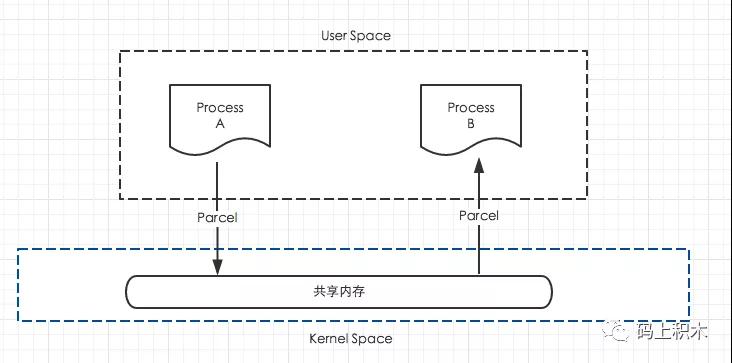
而Parcelable的實現就是基于這個Parcel容器,還記得剛才的幾個方法嗎:
- writeToParcel,寫入數據到Parcel容器。
- new User(in),從Parcel容器讀取數據。
Parcelable的原理就是如此啦。
思考問題
介紹完了兩種序列化方式,我們再來看看文章開頭的這些問題。
在java有Serializable的前提下,Android為什么設計出了Parcelable?
java中的序列化方式Serializable效率比較低,主要有以下原因:
- Serializable在序列化過程中會創建大量的臨時變量,這樣就會造成大量的GC。
- Serializable使用了大量反射,而反射操作耗時。
- Serializable使用了大量的IO操作,也影響了耗時。
所以Android就像重新設計了IPC方式Binder一樣,重新設計了一種序列化方式,結合Binder的方式,對上述三點進行了優化,一定程度上提高了序列化和反序列化的效率。
Serializable、Parcelable、Json等序列化方式我們該怎么選擇?
先說說序列化的用處,主要用在三個方面:
1、內存數據傳輸
內存傳輸方面,主要用Parcelable。一是因為Parcelable在內存傳輸的效率比Serializable高。二是因為在Android中很多傳輸數據的方法中,自帶了對于Serializable、Parcelable類型的傳輸方法。比如:
- Bundle.putParcelable,
- Intent putExtra(String name, Parcelable value)
等等吧,基本上對象傳輸的方法都支持了,所以這也是Parcelable的優勢。
2、 數據持久化(本地存儲)
如果只針對Serializable和Parcelable兩種序列化方式,需要選擇Serializable。
首先,Serializable本身就是存儲到二進制文件,所以用于持久化比較方便。而Parcelable序列化是在內存中操作,如果進程關閉或者重啟的時候,內存中的數據就會消失,那么Parcelable序列化用來持久化就有可能會失敗,也就是數據不會連續完整。而且Parcelable還有一個問題是兼容性,每個Android版本可能內部實現都不一樣,知識用于內存中也就是傳遞數據的話是不影響的,但是如果持久化可能就會有問題了,低版本的數據拿到高版本可能會出現兼容性問題。
但是實際情況,對于Android中的對象本地化存儲,一般是以數據庫、SP的方式進行保存。
3、 網絡傳輸
而對于網絡傳輸的情況,一般就是使用JSON了。主要有以下幾點原因:
- 輕量級,沒有多余的數據。
- 與語言無關,所以能兼容所有平臺語言。
- 易讀性,易解析。
Parcelable一定比Serializable快嗎?
正常情況下,對象在內存中進行傳輸確實是Parcelable比較快,但是Serializable是有緩存的概念的,有人做了一個比較有趣的實驗:
當序列化一個超級大的對象圖表(表示通過一個對象,擁有通過某路徑能訪問到其他很多的對象),并且每個對象有10個以上屬性時,并且Serializable實現了writeObject()以及readObject(),在平均每臺安卓設備上,Serializable序列化速度大于Parcelable 3.6倍,反序列化速度大于1.6倍.
具體原因就是因為Serilazable的實現方式中,是有緩存的概念的,當一個對象被解析過后,將會緩存在HandleTable中,當下一次解析到同一種類型的對象后,便可以向二進制流中,寫入對應的緩存索引即可。但是對于Parcel來說,沒有這種概念,每一次的序列化都是獨立的,每一個對象,都當作一種新的對象以及新的類型的方式來處理。
具體過程可以看看這篇:https://juejin.cn/post/6854573218334769166
為什么Java提供了Serializable的序列化方式,而不是直接使用json或者xml?
我覺得是歷史遺留問題。
有的人可能會想到各種理由,比如可以標記哪些類可以被序列化。又或者可以通過UID來標示反序列化為同一個對象。等等。
但是我覺得最大的問題還是歷史遺留問題,在以前,json還沒有成為大家認同的數據結構,所以Java就設計出了Serializable的序列化方式來解決對象持久化和對象傳輸的問題。然后Java中各種API就會依賴于這種序列化方式,這么些年過去了,Java體系的龐大也造成難以改變這個問題,牽一發而動全身。
為什么我這么說呢?
主要有兩點依據:
- 曾經Oracle Java平臺組的架構師說過,刪除Java的序列化機制并且提供給用戶可以選擇的序列化方式(比如json)是他們計劃中的一部分,因為Java序列化也造成了很多Java漏洞。具體可以參見文章:https://www.infoworld.com/article/3275924/oracle-plans-to-dump-risky-java-serialization.html
- 因為在Serializable類的介紹注釋中,明確說到推薦大家選擇JSON 和 GSON庫,因為它簡潔、易讀、高效。
- <h3>Recommended Alternatives</h3>
- <strong>JSON</strong> is concise, human-readable and efficient. Android
- includes both a {@link android.util.JsonReader streaming API} and a {@link
- org.json.JSONObject tree API} to read and write JSON. Use a binding library
- like <a href="http://code.google.com/p/google-gson/">GSON</a> to read and
- write Java objects directly.
Android體系架構
連載文章、腦圖、面試專題:
https://github.com/JiMuzz/Android-Architecture
參考
https://developer.android.google.cn/reference/android/os/Parcel?hl=en https://blog.csdn.net/lwj_zeal/article/details/90743500 https://juejin.cn/post/6854573218334769166#heading http://blog.sina.com.cn/s/blog_6e07f1eb0100rsax.html https://www.zhihu.com/question/283510695 https://www.infoworld.com/article/3275924/oracle-plans-to-dump-risky-java-serialization.html
本文轉載自微信公眾號「碼上積木」,可以通過以下二維碼關注。轉載本文請聯系碼上積木公眾號。
















