老少皆宜的Kafka長文,讓你明白什么叫本分
本文轉載自微信公眾號「小姐姐味道」,作者小姐姐養的狗。轉載本文請聯系小姐姐味道公眾號。
看完本文,你將明白為什么一個簡單的消息隊列,能夠有那么多的知識點;能夠了解到Kafka的主要功能和應用場景;能夠了解到Kafka的主要技術術語。了解到什么叫本分!
作為一個分布式消息系統,Kafka要有本分思想。它要搞清楚自己的定位,明白是為誰創造什么樣的價值,依賴誰活著,自己的職責又是什么。
很少有系統在這么有壓迫力的連環問下保持冷靜,不過Kafka頂住了,它是真的勇士。
Kafka的本分核心,就是當作消息隊列用。那么消息隊列是什么呢?如果這個問題沒法搞懂,就證明Kafka的思想覺悟并不是很高,還需要繼續去思考、去深造。
為了弄清楚這個問題,我們采訪了一位送牛奶的工人。
1. 送奶工的故事
牛奶好喝而且有營養,不管是牛奶子里捏出來的新鮮牛奶還是合成的牛奶,所以小區里有很多人訂。
每天清晨,送奶工人都拉著一車牛奶開始送奶。剛開始,他按照本子上的門牌號,一家家的敲門,然后把牛奶塞進客戶手里。有時候,客戶不在家,他只好翻出通訊錄找到客戶的電話號碼進行溝通。但過了不久,隨著業務做的越來越大,送奶工對這份工作的評價只有一句話:*費力不討好。
有的客戶睡眼朦朧的開門,投訴他打擾生活;有的女客戶披著睡衣就來接奶,投訴他的眼光猥瑣;有的客戶上班比較早,但在送奶工的路線規劃上,卻是奶最后送到的,于是投訴他配送不及時。
好在送奶工以前是個程序員,稍一思考,他說服老板:給每一家客戶,配備一個奶箱。他的工作,只需要定時把鮮奶放入箱子里即可。至于客戶什么時候去拿,拿去洗臉了還是搓手了,他并不關心。
從此,他再也沒看到睡衣下若隱若現的胴體。
我們注意到,上面的場景,有兩個主要的參與方:送奶工和客戶。在加入奶箱之前,他們的交互是阻塞的,信息處理是低效的,而且存在嚴重的耦合問題,以至于送奶工看了不該看的東西。
當然,加入奶箱之后,交互邏輯就發生了變化,這是需要適應的;而且,奶箱是有成本的,如果業務量并不是很大,加這個玩意反而會增加成本。
我們來稍微see一下下:上面的奶箱,就是消息系統。每一個奶箱,就是一條消息隊列。牛奶工,就是生產者;客戶,就是消費者;而牛奶,就是消息。客戶一直不取走奶,就是消息積壓。客戶和你發消息,確認奶已經收到,就是ACK...
2. 最簡單的廣義消息系統
消息系統!就是提供一個中間層,生產者只需要把消息提交到特定的中間層,消費者只需要從中間層去拿信息就可以了。
所以,它最簡單的表現形式,就是數據庫。
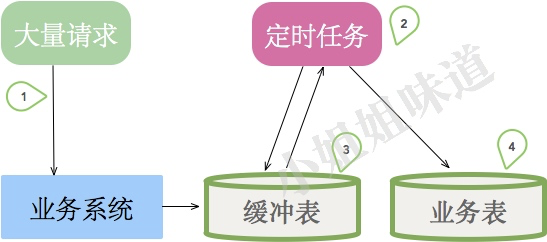
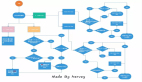
上圖是一些小系統的典型架構。考慮訂單的業務場景,有大量的請求指向我們的業務系統,如果直接經過復雜的業務邏輯進入業務表,將會有大量請求超時失敗。所以我們加入了一張中間緩沖表,用來承接用戶的請求。然后,有一個定時任務,不斷的從緩沖表中獲取數據,進行真正的復雜的業務邏輯處理。
不要懷疑,這其實就是最簡陋的消息系統,只不過它存在不少問題。
- 定時任務的輪詢間隔不好控制。業務處理容易延遲。
- 無法橫向擴容處理能力,且會引入分布式鎖、順序性保證等問題。
- 當其他業務也需要這些訂單數據的時候,業務邏輯就必須要加入到定時任務里。
當訪問量增加、業務邏輯復雜化的時候,更高的消息模型就呼之欲出了。
3. 消息系統的基本要求
我們對消息系統的本分要求有下面這些:
- 性能要高 包含消息投遞和消息消費,都要快。一般通過增加分片數獲取并行處理能力。數據庫顯然是有瓶頸的。
- 消息要可靠 在某些場景,不能丟消息。生產、消費、MQ端都不能丟消息。一般通過增加副本,強制刷盤來解決。數據庫顯然也要通過主從來做備份的。
- 擴展性要好 能夠陪你把項目做大,陪你到天荒地老。增加節點集群增大后,不能降低性能。數據庫的擴展性肯定是存疑的,你可能會引入一些復雜的分庫分表組件。
- 生態成熟 監控、運維、多語言支持、社區的活躍。這決定了你用的消息隊列值不值得你信賴。
甚至有更多,xjjdog有另外一篇文章去說明它:分布式消息系統,設計要點。畫龍畫虎難畫骨
要求這么多,但模型又如此簡單,它的難點到底在哪里呢?為什么有些同學看到Kafka就頭疼呢?
4. 要你本分,到底多難
既然消息系統的模型就是一個簡單的生產者消費者模型,那為什么現在的消息系統都那么的復雜呢?其實,它的復雜性,主要體現在分布式這三個字上,和消息隊列的關系不大,它需要處理一些所有分布式系統都要面臨的問題。
4.1 副本
單機上的任何數據都是不可信的,因為硬盤會壞,會斷電,會被挖光纜。所以一般通過冗余多個副本來保證數據的安全。副本的另外一個作用,就是提供額外的計算能力,比如某些請求,會落到副本上。副本越多,可用性越高。
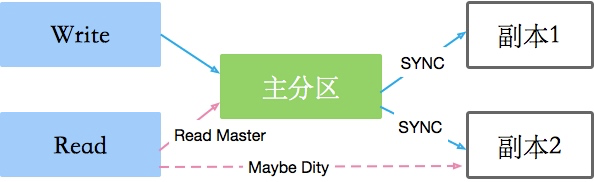
而加入副本以后,就涉及到數據的同步問題。即使是最快的局域網,也會存在延遲,更不用說機器性能差異引起的同步延遲。這就存在一個問題,讀副本的請求讀到的數據,可能不是最新的,這就是數據的一致性發生了改變。當然有些手段能保證數據的一致性,但副本越多,延遲越大。
副本的加入還會引入主從的問題。主節點死掉以后,要有副本節點頂上去,這個過程的協調需要時間,其間部分不可用。
所有的消息系統,需要有大量的代碼去處理這些異常情況。
4.2 分區
而當一類數據足夠大(比如說某張表),在其上的操作已經非常耗時的情況下,就需要對此類數據進行切割,將其分布到多臺機器上。這個切割過程就是Sharding,通過一定規則的分片來減少單次查詢數據的規模,增加集群容量。
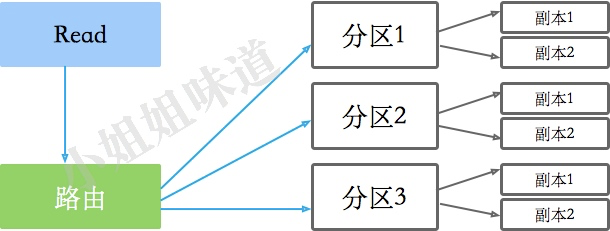
針對一個分片的數據,只能有一個寫入的地方,這就是master,其他副本都是從master復制數據。
副本能夠增加讀操作的并行讀,但會讀到臟數據。如果你想要讀到的數據是一致的,可以采用同步寫副本的方式,比如KAFKA的ack=-1,只有全部同步成功了,才認為本次提交成功。
但如果你的副本太多,這個過程會非常的慢。你可能想要通過分配寫入和讀取的副本個數來協調寫入和讀取的效率,Quorum的R+W>N就是一個權衡策略。
5. Kafka名詞解釋
我們反過來再看Kafka的名詞定義,就簡單的多了。
Kafka是一個分布式消息(存儲)系統。分布式系統通過分片增加并行度;通過副本增加可靠性,kafka也不例外。它的結構逃不出我們上面介紹的基本分布式理論。如果你把副本、分區、主題通道,生產者、消費者這些名詞放在一塊的話,圖就可以變得非常大。
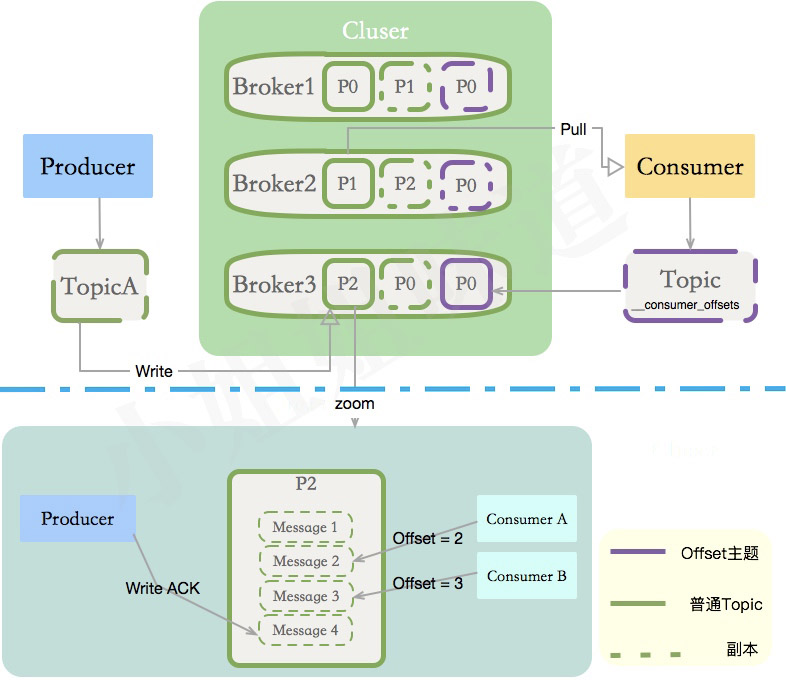
你在一臺機器上安裝了Kafka,那么這臺機器就叫Broker,KAFKA集群包含了一個或者多個這樣的實例。這只是一個命名而已,并沒有什么特定含義。
負責往KAFKA寫入數據的組件就叫做Producer,消息的生產者一般寫在業務系統里。和我們的送奶工是一個維度。
發送到KAFKA的消息可能有多種,如何區別其分類?就是Topic的概念。一個主題分布式化后,可能會存在多個Broker上。
將Topic拆成多個段,增加并行度后,拆成的每個部分叫做Partition,分區一般平均分布在所有機器上。
那些消費Kafka中數據的應用程序,就叫做Consumer,我們給某個主題的某個消費業務起一個名字,這么名字就叫做Consumer Group
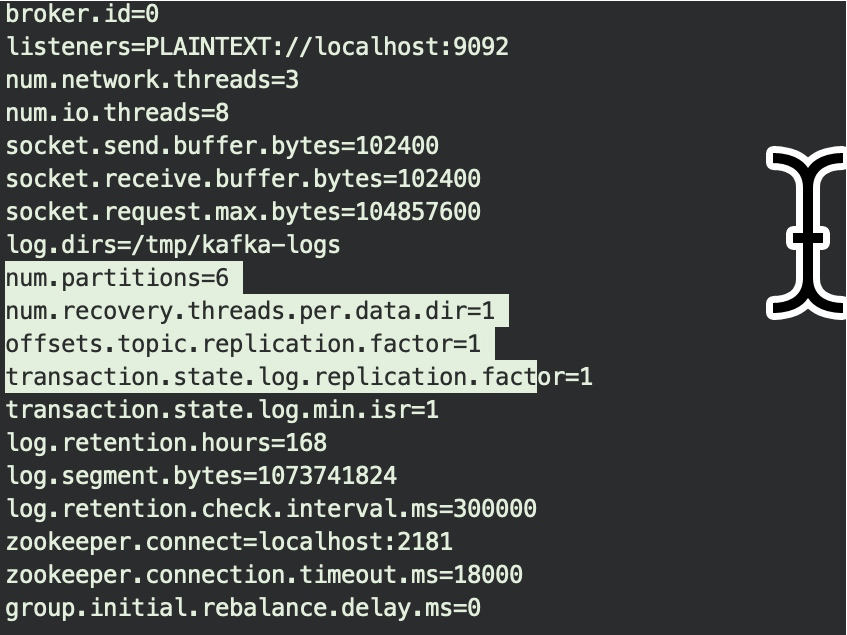
再看一下Kafka Server的配置文件,最重要的兩個參數:partitions和replication.factor,其實就非常好理解了。
再來說一個最重要的概念。Kafka解決副本之間的同步,采用的是ISR,這是一個面試Kafka必考的點之一。
ISR全稱"In-Sync Replicas",是保證HA和一致性的重要機制。副本數對Kafka的吞吐率是有一定的影響,但極大的增強了可用性。一般2-3個為宜。
副本有兩個要素,一個是數量要夠多,一個是不要落在同一個實例上。ISR是針對與Partition的,每個分區都有一個同步列表。N個replicas中,其中一個replica為leader,其他都為follower, leader處理partition的所有讀寫請求,其他的都是備份。與此同時,follower會被動定期地去復制leader上的數據。
如果一個flower比一個leader落后太多,或者超過一定時間未發起數據復制請求,則leader將其從ISR中移除。
當ISR中所有Replica都向Leader發送ACK時,leader才commit。
6. 消息系統的作用
說了這么多,是時候把消息隊列的作用,使用計算機的術語解釋一下了:
削峰 用于承接超出業務系統處理能力的請求,使業務平穩運行。這能夠大量節約成本,比如某些秒殺活動,并不是針對峰值設計容量。
緩沖 在服務層和緩慢的落地層作為緩沖層存在,作用與削峰類似,但主要用于服務內數據流轉。比如批量短信發送。
解耦 項目伊始,并不能確定具體需求。消息隊列可以作為一個接口層,解耦重要的業務流程。只需要遵守約定,針對數據編程即可獲取擴展能力。
冗余 消息數據能夠采用一對多的方式,供多個毫無關聯的業務使用。
健壯性 消息隊列可以堆積請求,所以消費端業務即使短時間死掉,也不會影響主要業務的正常進行。
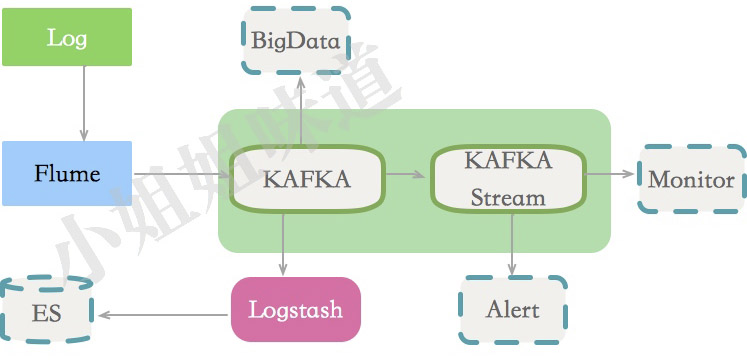
但是,由于Kafka是個優秀的小伙,它內卷的非常可以,就能做更多的事情。它的本分范圍更加大,包括但不限于:
- 傳遞業務消息
- 用戶活動日志 • 監控項等
- 日志
- 流處理,比如某些聚合
- Commit Log,作為某些重要業務的冗余
- Event Source,實踐溯源,DDD中的概念
下面是一個日志方面的典型使用場景。
7. KAFKA為什么快
一般用到Kafka,都是奔著它的速度去的,這一度讓人認為它只能處理一些日志類的消息。事實上,Kafka就連最復雜的事務消息都支持,也算是被它的速度所掩蓋的一個光彩。
那么,它為什么那么快呢?總結下來有以下幾點原因:
- Cache Filesystem Cache PageCache緩存
- 順序寫 由于現代的操作系統提供了預讀和寫技術,磁盤的順序寫大多數情況下比隨機寫內存還要快
- Zero-copy 零拷⻉,少了一次內存交換
- Batching of Messages 批量量處理。合并小的請求,然后以流的方式進行交互,直頂網絡上限
- Pull 拉模式 使用拉模式進行消息的獲取消費,與消費端處理能力相符
主要就這5點,至于什么壓縮,JVM性能優化之類的,都是小兒科,上不了臺面。
End
可以看到,Kafka是一個全能的選手,既能做消息處理,又能做數據存儲。它無怨無悔的工作,雖然效率奇高,也要一刻不停歇的工作,體現了打工人最悲催的命運。
它的分布式系統設計也是非常棒的,這是它的設計者為它量身定做的一套體系:一臺Kafka節點倒下了,會有更多的Kafka節點頂上來,經過十幾秒的陣痛,然后就可以徹底的忘掉它的犧牲。
Kafka是一個本分的分布式消息系統,但也不要無限的壓迫它。只給它分配了1核cpu、512M的內存,這是要磨練它在艱苦環境下不屈不撓的本分意志,啊!
丟了數據還罵ta不穩定,你的良心不會痛么?
作者簡介:小姐姐味道 (xjjdog),一個不允許程序員走彎路的公眾號。聚焦基礎架構和Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。我的個人微信xjjdog0,歡迎添加好友,進一步交流。