網工的Python之路:Concurrent.Futures
我在去年寫的兩篇專欄文章中已經介紹過多線程(threading)和異步IO(asyncio),并向大家舉例講解了網工要如何將它們應用在我們平常的網絡運維中來提升Python腳本的工作效率。這篇文章來介紹下另外一個可以實現并發編程的Python標準庫:concurrent.futures。
基本概念
網工在自學Python的時候肯定或多或少聽說過同步(Synchronous)、異步(Asynchronous)、單線程(Single Threaded)、多線程(Multi Threaded)、多進程(Multiprocessing)、多任務(Multitasking) 、并發(Concurrent)、并行(Parallesim)、協程(Coroutine)、I/O密集型(I/O-bound)、CPU密集型(CPU-bound)等術語,如何區分它們對學習Python的網工來說是一個難點,開篇講concurrent.futures之前先把上述這些術語之間的關系和區別給大家大致捋一下:
1. 同步(Synchronous) VS 異步(Asynchronous)
所謂同步,可以理解為每當系統執行完一段代碼或者函數后,系統將一直等待該段代碼或函數返回的值或消息,直到系統接收到返回的值或消息后才繼續往下執行下一段代碼或者函數,在等待返回值或消息的期間,程序處于阻塞狀態,系統將不做任何事情。而異步則恰恰相反,系統在執行完一段代碼或者函數后,不用阻塞性地等待返回的值或消息,而是繼續執行下一段代碼或函數,在同一時間段里執行多個任務(而不是傻傻地等著一件事情做完并且直到結果出來了以后才去做下件事情),將多個任務并發(注意不是并行),從而提高程序的執行效率。如果你有讀過數學家華羅庚的《統籌方法》,一定不會對其中所舉的例子感到陌生:同樣是沏茶的步驟,因為燒水需要一段時間,你不用等水煮沸了過后才來洗茶杯、倒茶葉(類似“同步”),而是在等待燒水的過程中就把茶杯洗好,把茶葉倒好,等水燒開了就能直接泡茶喝了,這里燒水、洗茶杯、倒茶葉三個任務是在同一個時間段內并發完成的,這就是一種典型的“異步”。對我們網工來說,paramiko, netmiko, telnetlib, pexpect, ciscolib等第三方模塊默認都是基于同步的,基于異步的模塊有asyncio, asyncping, netdev等等(pexpect也支持異步,但是必須手動調,默認狀態下是同步)。
2. 線程(Thread) VS 進程(Process)
所謂線程是指操作系統能夠進行運算調度的最小單位。線程依托于進程存在,是進程中的實際運作單位,一個進程可以有多個線程,每條線程可以并發執行不同的任務。
3. 單線程(Single Threaded) VS 多線程 (Multi Threaded)
我們也可以引用同樣的例子來說明單線程和多線程的區別。在上面講到的華羅庚《統籌方法》里沏茶的這個例子中,如果只有一個人來完成燒水、洗茶杯、倒茶葉三項任務的話,因為此時只有一個勞動力,我們就可以把它看成是單線程(同步、異步IO都是基于單線程的)。假設我們能找來三個人分別負責燒水、洗茶杯、倒茶葉,那我們就可以把它看成是多線程,每一個勞動力代表一個線程,但是由于多線程的Global Interpreter Lock機制(俗稱的GIL全局鎖)的存在,實際上這三個勞動力并不是同時開工的,從并發的性能和效率的角度來看,多線程實際上是弱于基于單線程的異步IO的,這點我們已經在之前的兩篇文章里通過實驗驗證了。
講到單線程和多線程,還需要講下異步IO和多線程之間的區別:
- 異步IO是單線程,而多線程顧名思義就是多線程。
- 異步IO和多線程的區別在于它們的機制不一樣,多線程使用的是搶占式多任務處理(Pre-emptive Multitasking) 。在這種搶占式環境下,操作系統本身具有掌控所有任務(也就是程序)的能力,能隨心所欲地剝奪每個任務的時間片來提供給其他任務,也就是有一個幕后大boss掌控一切。而異步IO的機制為協作式多任務處理(Cooperative Multitasking), 這種機制沒有幕后大boss,在協作式環境下,每個任務被調度的前提是當前任務主動放棄時間片。
- 異步IO的核心是協程(Coroutine),這個是多線程不具備的。協程是一種輕量級線程,它是一種特殊的生成器函數,它可以在return語句被執行前停止該函數當前正在執行的任務,并且能在一段時間內間接地將執行權交給另外一個協程函數。協程強調的是合作,而不是多線程強調的搶占,asyncio是Python中唯一支持協程的標準庫。
4. 并發(Concurrent) VS 并行 (Parallesim)
并發是一個籠統的概念,在Python里,在邏輯上同時發生的任務有多種稱謂:多線程,異步IO(多任務),多進程,它們都是并發的一種。深入地說,只有調用多核CPU的多進程(Multiprocessing)是用來處理在物理上同時發生的任務的,這個叫并行。基于單核CPU的多線程和異步IO(多任務)同一時間內只能處理一件事件(但是它們有自己獨特的機制來加快處理不同事件的能力),這個叫做并發。
借用某知乎網友舉的例子來說明同步、并發、并行三者之間的區別。
當你吃飯的時候突然有人給你打電話,如果此時你:
- 不接聽電話,繼續吃飯,等把飯吃完過后再來回電話,這個叫做同步。
- 接聽電話后放下筷子停止進食,等通話完畢后再接著吃,這個叫做并發。
- 接聽電話的同時繼續進食,這個叫做并行。
綜上,并行是并發的一種,但是并發并不等于并行。
5. I/O密集型(I/O bound) VS CPU密集型(CPU bound)
I/O密集型(I/O bound) 是指不會特別消耗 CPU 資源,但是I/O比較頻繁的任務和操作,比如文件的讀寫、網絡通信、數據庫訪問等等。
CPU密集型(CPU bound)是指需要大量耗費CPU資源的任務和操作,比如計算、解壓縮、加密解密等等。
異步和多線程適合I/O密集型場景, 多進程適合CPU密集型場景。
上述內容可以歸納總結成下表:
- 并發類型切換機制CPU數量適用場景代表Python庫多線程(搶占式多任務處理)操作系統決定何時切換任務1個I/O密集型_thread(已淘汰), threading,
- cocurrent.futures, nornir異步(協作式多任務處理)任務本身決定何時切換1個I/O密集型asyncio, netdev, aiohttp, aioping, gevent,
- tornado, twisted多進程 (并行)所有任務同時運行多個CPU密集型multiprocessing
好了,說了那么多下面進入本篇正文:concurrent.futures。
什么是Concurrent.futures
Concurrent.futures是Python中的一個標準庫,顧名思義它是并發編程的一種,根據Python官方的定義,concurrent.futures是一種高級接口,它同時融合了多線程和多進程的特點,并將兩者簡化。Concurrent.futures從Python3.2中被引入,它的誕生時間晚于threading和multiprocessing兩個標準庫,但是早于誕生于Python3.4的asyncio標準庫。
Future對象
在concurrent.futures中引入了future這個對象,關于future的中文翻譯目前為止我聽說過未來、期程等,但還沒有一個統一的說法(Python中文官方文檔上也沒有說明),所以這里我們還是用future來講。
主線程(或進程)可以通過future對象獲取某一個線程(進程)執行的狀態或者某一個任務執行的狀態及返回值。
執行器對象
Concurrent.futures中還有一個重要的對象叫做執行器(Executor),分為ThreadPoolExecutor和ProcessPoolExecutor兩種,你基本可以把它倆看成是multiprocessing庫中的線程池和進程池(支持多進程的multiprocessing標準庫以前沒講過,我準備下篇文章中再講),前面提到了,concurrent.futures相較于multiprocessing以及threading兩個庫來說它的優勢在于其語法更簡單,學習成本更低。
理論的東西先講到這里,接下來直接做實驗說明concurrent.futures怎么用,為了做對比,我會用單線程同步、threading、concurrent.futures分別舉三個例子。首先來看最原始的單線程同步:
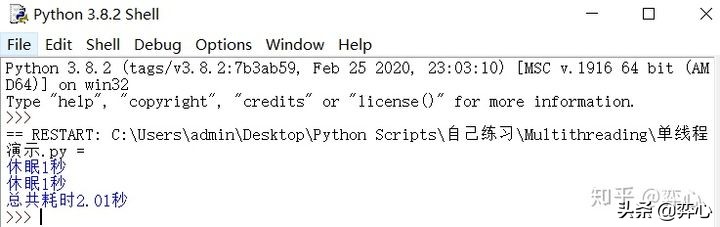
1. 單線程同步實驗:
- import time
- def do_something():
- print ('休眠1秒')
- time.sleep(1)
- start_time = time.perf_counter()
- do_something()
- do_something()
- end_time = time.perf_counter()-start_time
- print (f'總共耗時{round(end_time, 2)}秒')
這里我們自定義一個叫做do_something()的函數,它的任務很簡單,就是打印出內容“休眠1秒”,然后使用time.sleep(1)來讓程序休眠1秒。然后我們調用兩次do_something()函數,打印出耗時,因為是單線程同步,所以兩次執行do_something()的總耗時為2.01秒。
2. Threading實驗
- import threading
- import time
- def do_something():
- time.sleep(1)
- start_time = time.perf_counter()
- threads = []
- for i in range(1,11):
- t = threading.Thread(target=do_something, name=f'線程{str(i)}')
- print (f'{t.name}開始運行')
- print ('休眠1秒')
- t.start()
- threads.append(t)
- for thread in threads:
- thread.join()
- end_time = time.perf_counter()-start_time
- print (f'總共耗時{round(end_time, 2)}秒')
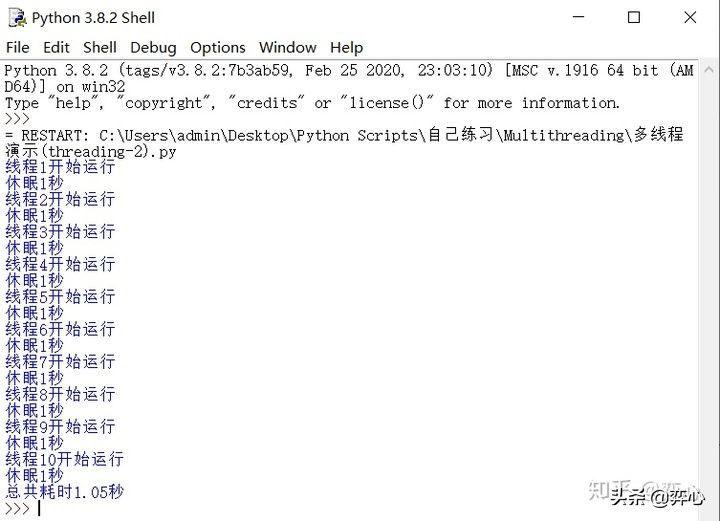
這里我們用threading來總共執行10次do_something(),如果按單線程同步的方法的話,總計會耗費10秒+才能完成,而通過threading模塊我們使用多線程讓這10次do_something()并發執行,所以僅僅只用到了1.05秒便宣告完成。
3. Concurrent.futures實驗(分為三種代碼)
因為涉及到不同的知識點,Concurrent.futures實驗的代碼我將分三種來寫,首先來看第一段代碼:
- from concurrent.futures import ThreadPoolExecutor
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完畢'
- start_time = time.perf_counter()
- executor = ThreadPoolExecutor()
- f1 = executor.submit(do_something, 1)
- f2 = executor.submit(do_something, 1)
- print (f1.result())
- print (f2.result())
- print (f'task1是否完成: {f1.done()}')
- print (f'task2是否完成: {f1.done()}')
- end_time = time.perf_counter()-start_time
- print (f'總共耗時{round(end_time,2)}秒')
代碼講解(只講和concurrent.futures有關的知識點):
這里我們使用from concurrent.futures import ThreadPoolExecutor來調用concurrent.futures的線程池處理器對象
- from concurrent.futures import ThreadPoolExecutor
這里注意我們在do_something()函數后面加了參數seconds,并在最后面加了一個return '休眠完畢',它們的作用等會兒會講到:
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完畢'
在concurent.futures中,ThreadPoolExecutor是Executor下面的兩個子類之一(另一個是ProcessPoolExecutor),它使用線程池來執行異步調用,這里我們將ThreadPoolExecutor()賦值給一個叫做executor的變量。
- executor = ThreadPoolExecutor()
然后我們使用ThreadPoolExecutor下面的submit()函數來創建線程,submit()函數中包含了要調用的任務,即do_something(),以及該函數要調用的參數(也就是dosmeting()里面的seconds),這里我們放1,表示休眠一秒鐘,所以寫成submit(do_something, 1),因為submit()函數返回的值為future類型的對象,所以這里我們把future簡寫為f, 分別賦值給f1和f2兩個變量,表示并發執行兩次do_something()函數。
- f1 = executor.submit(do_something, 1)
- f2 = executor.submit(do_something, 1)
前面講到了,future對象的作用是幫助主線程(或進程)獲取某一個線程(進程)執行的狀態或者某一個任務執行的狀態及返回值,為了向大家演示,這里我對f1和f2兩個future對象分別調用了result()和done()兩個函數并將它們的結果打印出來。
- print (f1.result())
- print (f2.result())
- print (f'task1是否完成: {f1.done()}')
- print (f'task2是否完成: {f1.done()}')
在future中,result()的作用是告知你任務走到了哪一步,是否有異常,如果任務沒有異常正常完成的話,那么result()會返回自定義函數下面return的內容(也就是我們do_someting()最下面的return'休眠完畢'),如果任務執行過程中遇到異常 ,那么result()則會返回異常的具體內容。 done()則返回一個布爾值,來告訴你任務是否完成,如果完成,則返回True,反之則返回False。
接下來看腳本運行效果:
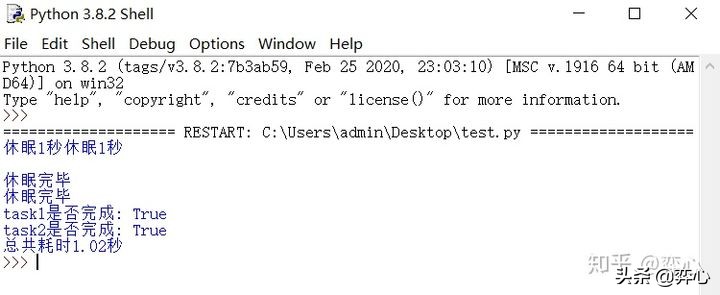
可以看到同步需要2秒+完成的兩次任務通過concurrent.futures縮短為1.02秒完成(這個時間不定,如果你多跑腳本幾次,你會看到1.01秒,1.02秒,1.03秒,1.04秒等幾種,這個和當前電腦的性能有關系)。注意這里的兩個“休眠完畢”是print (f1.result()) 和print (f2.result())打印出來的, “task1是否完成: True”和“task2是否完成: True”是 print (f'task1是否完成: {f1.done()}')和print (f'task2是否完成: {f1.done()}')打印出來的。
接下來我們再看concurrent.futures的第二段實驗代碼:
- from concurrent.futures import ThreadPoolExecutor, as_completed
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完畢'
- start_time = time.perf_counter()
- executor=ThreadPoolExecutor()
- results = [executor.submit(do_something, 1) for i in range(10)]
- for f in as_completed(results):
- print (f.result())
- end_time = time.perf_counter()-start_time
- print (f'總共耗時{round(end_time,2)}秒')
代碼講解(只講和concurrent.futures有關的知識點):
這里我們從concurrent.futures中新導入了一個函數叫做as_completed,它的作用后面會講到。
- from concurrent.futures import ThreadPoolExecutor, as_completed
第一段代碼缺乏靈活性,因為我們是通過手動的方式創建了f1和f2兩個線程,如果我們要并發運行do_something()這個任務100次,顯然我們不可能去手動創建f1, f2, f3......f100這100個變量。這里我們可以用list comprehension的方式創建一個列表,讓do_something()這個函數并發運行10次。
- results = [executor.submit(do_something, 1) for i in range(10)]
在concurrent.futures中,as_completed(fs)函數的作用是針對給定的 future 迭代器 fs,在其完成后,返回完成后的迭代器(類型仍然為future)。這里的fs即為我們創建的列表results。因為concurrent.futures.as_completed(results)返回的值是迭代器,因此我們可以使用for循環來遍歷它,然后對其中的元素(均為future類型)調用前面講到的result()函數并打印
- for f in as_completed(results):
- print (f.result())
執行代碼看效果,可以看到10次do_something()任務1.06秒便完成了。

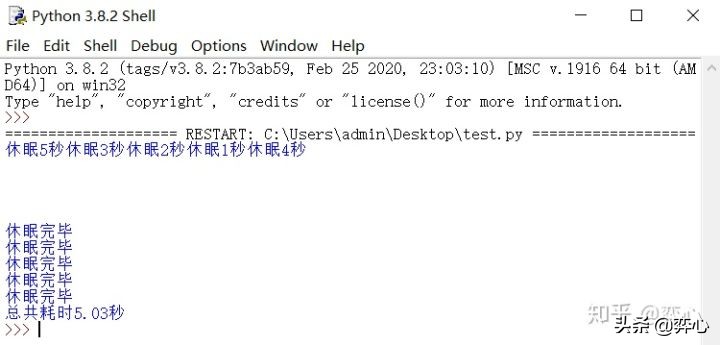
concurrent.futures的第三段實驗代碼:
- from concurrent.futures import ThreadPoolExecutor
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完畢'
- start_time = time.perf_counter()
- executor=ThreadPoolExecutor()
- sec = [5,4,3,2,1]
- results = executor.map(do_something, sec)
- for result in results:
- print (result)
- end_time = time.perf_counter()-start_time
- print (f'總共耗時{round(end_time,2)}秒')
代碼講解(只講和concurrent.futures有關的知識點):
- 除了通過list comprehension來指定N次并發運行do_something(seconds)外,我們還可以通過concurrent.futures.ThreadPoolExecutor()下面的map()函數來達到目的,map()函數和submit()函數的用法類似,都可以用來創建線程,然后并發執行任務并返回future對象,但是它比submit()函數更靈活。它們的區別是:map()函數傳入的第二個參數為一個可遍歷的對象,這個可遍歷的對象里的元素可以用來作為函數的參數。比如說這里我們定義了sec = [5,4,3,2,1]這個列表,該列表作為map()函數的第二個參數被傳入(executor.map(do_something, sec)),因為該列表總共有5個元素,因此我們這里創建并且并發了5個線程來分5次執行do_something(seconds),第一次列表中的元素5作為參數被傳入do_something(seconds), 也就是第一個線程執行后將休眠5秒,第二次列表中的元素4作為參數被傳入do_something(seconds), 也就是第二個線程執行后將休眠4秒,以此類推。
- executor=ThreadPoolExecutor()
- sec = [5,4,3,2,1]
- results = executor.map(do_something, sec)
接下來看腳本運行效果:因為5次任務是并發執行的,所以程序消耗了5秒,4秒,3秒,2秒,1秒中的最大值,總共耗時5.03秒完成。