













DALL·E發布兩天就被復現?官方論文沒出,大神們就在復現了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
沒想到,OpenAI剛公布DALL·E,就已經有人在復現了。

雖然還是個半成品,不過大體框架已經搭建好了,一位第三方作者Philip Wang正在施工中。
DALL·E是前兩天剛公布的文字轉圖像網絡框架,目前只公布了項目結果,甚至連官方論文都還沒出。
論文還沒出,就開始復現了
論文復現的依據,來自一位叫做Yannic Kilcher的博主制作的油管視頻。
他在視頻中,對DALL·E的原理結構進行了猜測。
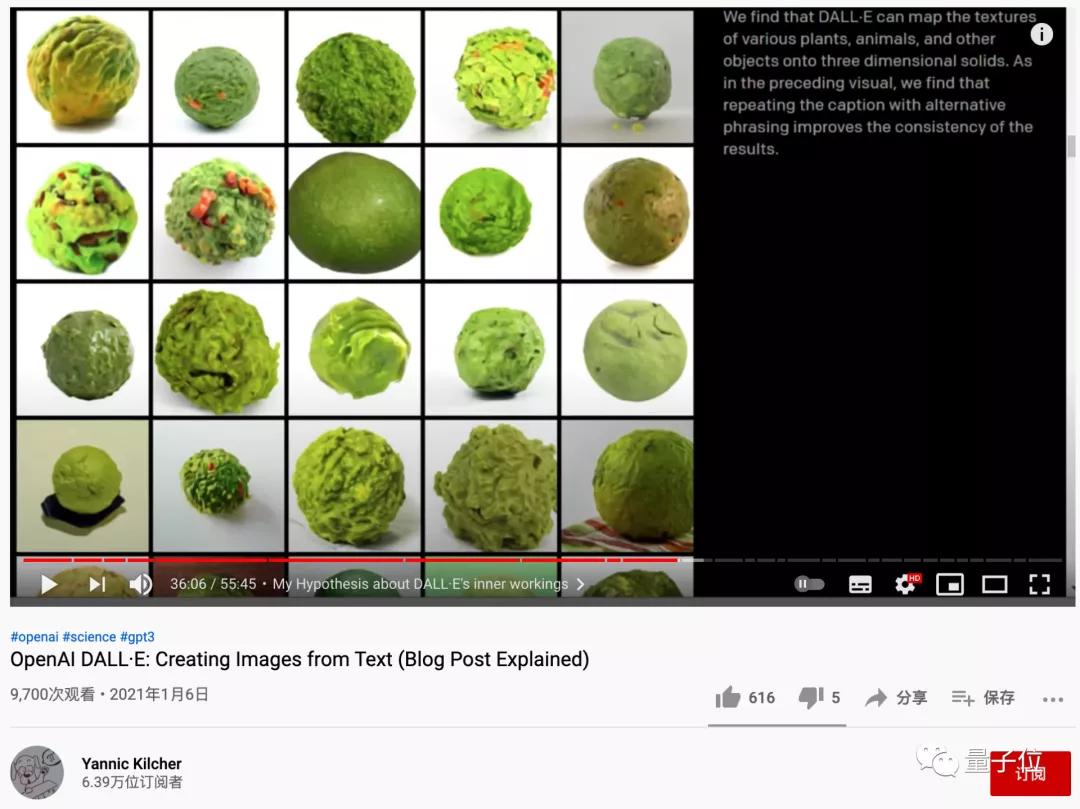
他表示,這些猜測并不代表真實情況,也許DALL·E的論文出來后,會顛覆他的預想。
Yannic認為,DALL·E應該是VQ-VAE模型、和類似于GPT-3的語言模型的結合。
GPT-3這類語言模型,有著非常強大的語言建模能力,可以對輸入的文字描述進行很好的拆分理解。
而VAE模型,則是一種強大的圖像生成Transformer,在訓練完成后,模型會去掉編碼器(encoder)的部分,只留下解碼器,用于生成圖像。
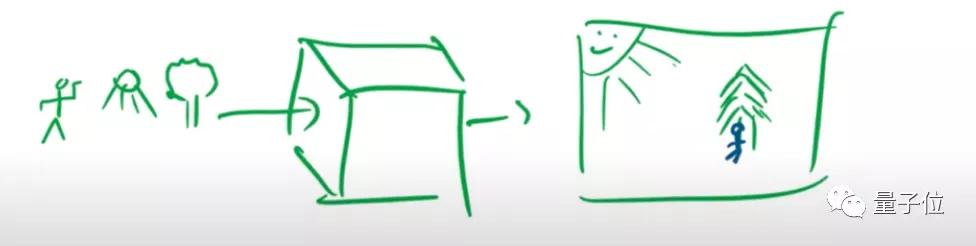
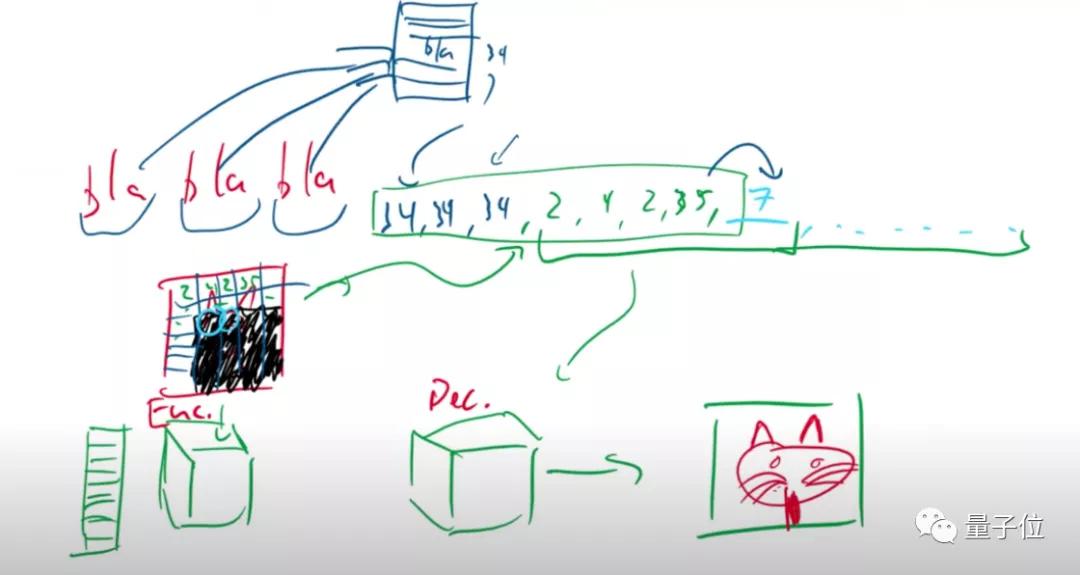
將二者結合的話,就能像下圖中的那個小方塊一樣,將輸入的各種物體,根據理解的文字,結合成具有實際意義的一幅畫面。
例如,輸入人、太陽和樹,模型就能輸出“太陽下,樹底坐著一個人”所描繪的圖像。
要怎么實現?
先簡單分析一下VQ-VAE的模型原理。
與VAE相似,這也是一個Transformer結構的模型,編碼器對圖像進行編碼后,將編碼數據送入隱空間,解碼器再從隱空間中,對圖像進行重構。
相比于VAE,VQ-VAE隱變量的每一維都是離散整數,也就是說,它的隱空間其實是一個編碼簿(codebook),包含提取出的各種向量信息。
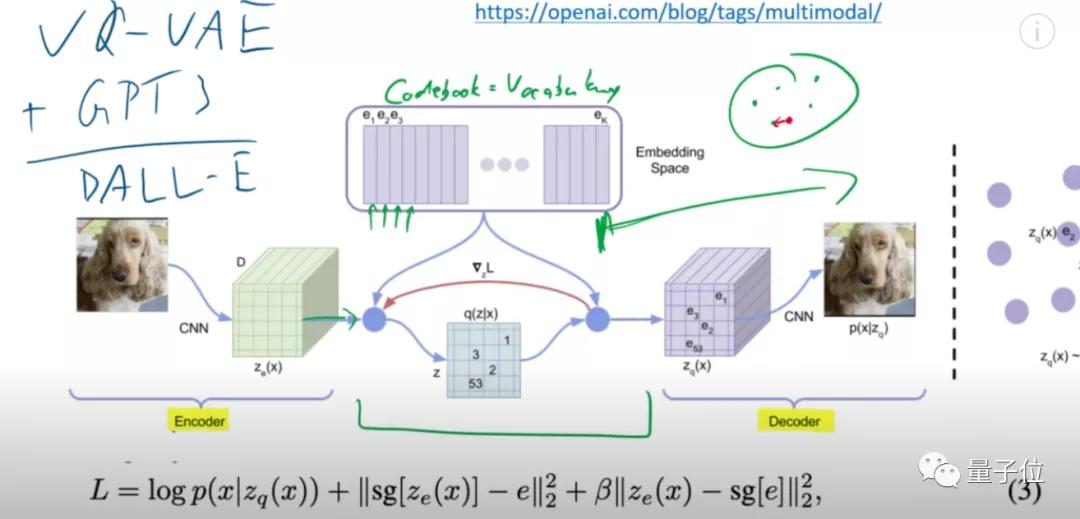
在DALL·E里,這個編碼簿,本質上可以等價為一個詞匯表(vocabulary)。
這個詞匯表,專門用來存儲對圖像的各種描述。
對輸入圖像進行編碼時,本質上是將圖像分成各種像素塊。
期間,會產生各種各樣的圖像信息。
假設天藍色的格子,包含“天空”的描述信息,那么在重建時,解碼器讀取到“天空”信息,就會分配頂端的一系列像素,用來生成天空。
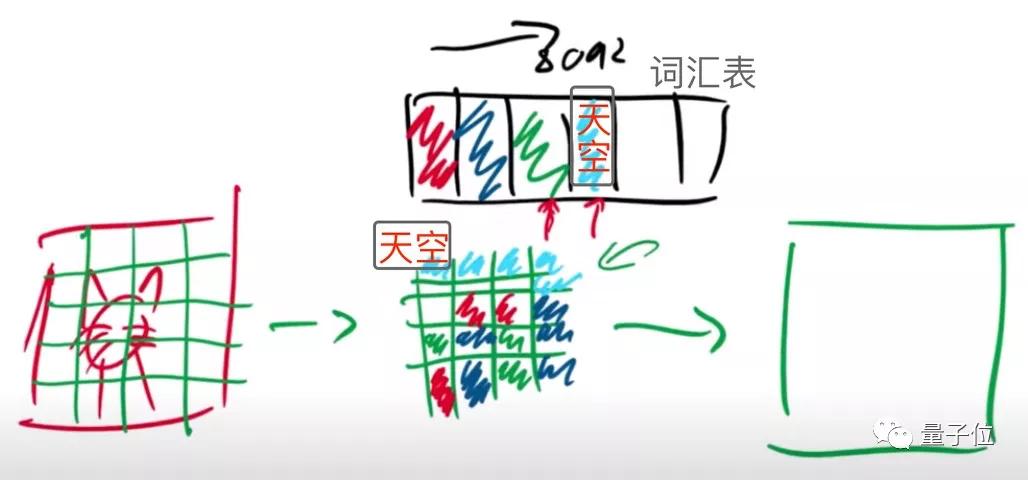
在完成VQ-VAE的訓練后,模型就得到了一個只有解碼器看得懂的編碼簿。
屆時,將由類似于GPT-3的語言模型,對輸入的文字進行解碼,轉換成只有編碼簿才能看懂的向量信息。
然后,編碼簿會將這些信息進行排序,依次列出每個像素塊應該生成的數據,并告訴解碼器。
解碼器會合成這些像素數據,得到最終的圖像。
為了實現這樣的目標,既要對類似于GPT-3的語言模型進行訓練,也要提前對VQ-VAE模型進行預訓練。
而且,還需要對二者融合后的模型進行訓練。
這位作者復現的DALL·E,也是依據這個視頻解析的原理復現的。
有關項目本身
目前,DALL·E的復現項目還沒有完成,作者仍然在加工中(WIP),不過已經有700多個Star。
作者希望寫出一個PyTorch版本的DALL·E,現在的框架中,已經包含了VAE的訓練、CLIP的訓練,以及VAE和CLIP融合后的模型預訓練。
此外,還包括DALL·E的訓練、和將預訓練VAE模型融合進DALL·E模型中的部分。
上述模塊訓練完成后,就能用DALL·E來做文字生成圖像了。
目前,作者正在進行DALL·E模塊部分的代碼復現。
作者承諾,完成DALL·E的部分后,會把CLIP模型也一起補上。
作者介紹
Philip Wang,本碩畢業于康奈爾大學,博士畢業于密歇根大學醫學院。
他的研究興趣是AI(深度學習方向),以及醫療健康,目前GitHub上已有1.7k個followers。
關于DALL·E本身,視頻解析博主Yannic也表示,之所以能取得這么好的效果,并不全是因為模型設計。

DALL·E,極可能也像GPT-3一樣,用了樣本量龐大的數據集,來對模型進行訓練。
網友表示,難以想象訓練這個玩意所用的GPU數量,氣候又要變暖了。

所以要想完全復現這個項目,最難的其實是硬件部分?(手動狗頭)
項目地址:
https://github.com/lucidrains/DALLE-pytorch
DALL·E視頻解析:
https://www.youtube.com/watch?v=j4xgkjWlfL4
























