圖文理解 Spark 3.0 的動(dòng)態(tài)分區(qū)裁剪優(yōu)化
本文轉(zhuǎn)載自微信公眾號(hào)「過往記憶大數(shù)據(jù)」,作者過往記憶大數(shù)據(jù) 。轉(zhuǎn)載本文請(qǐng)聯(lián)系過往記憶大數(shù)據(jù)公眾號(hào)。
Spark 3.0 為我們帶來了許多令人期待的特性。動(dòng)態(tài)分區(qū)裁剪(dynamic partition pruning)就是其中之一。本文將通過圖文的形式來帶大家理解什么是動(dòng)態(tài)分區(qū)裁剪。
Spark 中的靜態(tài)分區(qū)裁剪
在介紹動(dòng)態(tài)分區(qū)裁剪之前,有必要對(duì) Spark 中的靜態(tài)分區(qū)裁剪進(jìn)行介紹。在標(biāo)準(zhǔn)數(shù)據(jù)庫術(shù)語中,裁剪意味著優(yōu)化器將避免讀取不包含我們正在查找的數(shù)據(jù)的文件。例如我們有以下的查詢 SQL:
- Select * from iteblog.Students where subject = 'English';
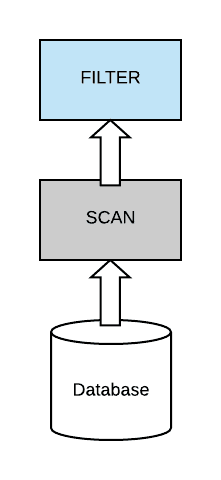
在這個(gè)簡(jiǎn)單的查詢中,我們?cè)噲D匹配和識(shí)別 Students 表中 subject = English 的記錄。比較愚蠢的做法是先把數(shù)據(jù)全部 scan 出來,然后再使用 subject = 'English' 去過濾。如下圖所示:
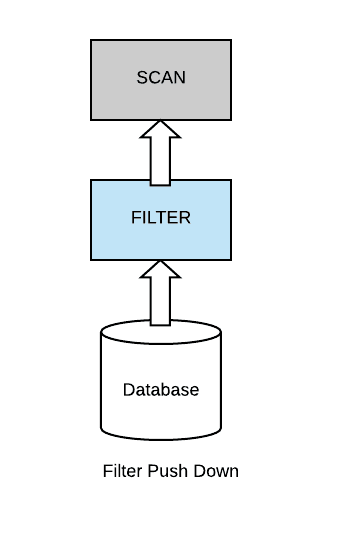
比較好的實(shí)現(xiàn)是查詢優(yōu)化器將過濾器下推到數(shù)據(jù)源,以便能夠避免掃描整個(gè)數(shù)據(jù)集,Spark 就是這么來做的,如下圖所示:
在靜態(tài)分區(qū)裁剪技術(shù)中,我們的表首先是分區(qū)的,分區(qū)過濾下推的思想和上面的 filter push down 一致。因?yàn)樵谶@種情況下,如果我們的查詢有一個(gè)針對(duì)分區(qū)列的過濾,那么在實(shí)際的查詢中可以跳過很多不必要的分區(qū),從而大大減少數(shù)據(jù)的掃描,減少磁盤I/O,從而提升計(jì)算的性能。
然而,在現(xiàn)實(shí)中,我們的查詢語句不會(huì)是這么簡(jiǎn)單的。通常情況下,我們會(huì)有多張維表,小表需要與大的事實(shí)表進(jìn)行 join。因此,在這種情況下,我們不能再應(yīng)用靜態(tài)分區(qū)裁剪,因?yàn)?filter 條件在 join 表的一側(cè),而對(duì)裁剪有用的表在 Join 的另一側(cè)。比如我們有以下的查詢語句:
- Select * from iteblog.Students join iteblog.DailyRoutine
- where iteblog.DailyRoutine.subject = 'English';
對(duì)于上面的查詢,比較垃圾的查詢引擎最后的執(zhí)行計(jì)劃如下:
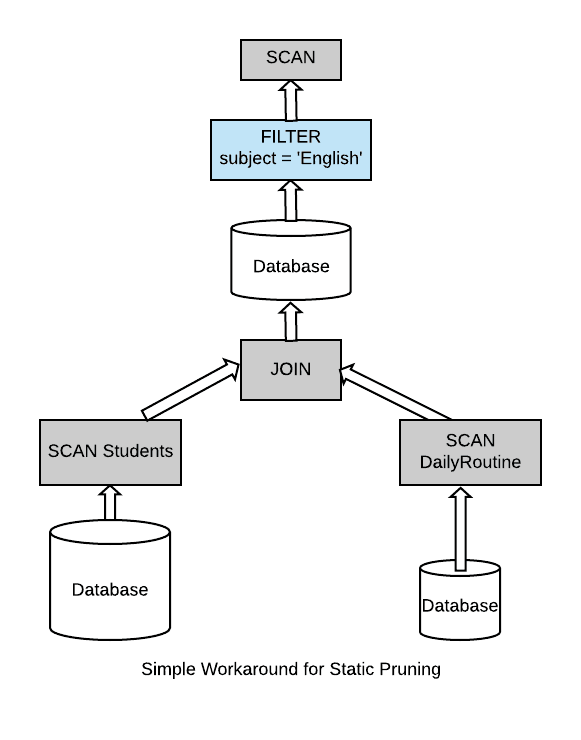
它把兩張表的數(shù)據(jù)進(jìn)行關(guān)聯(lián),然后再過濾。在數(shù)據(jù)量比較大的情況下效率可想而知。一些比較好的計(jì)算引擎可以進(jìn)行一些優(yōu)化,比如:
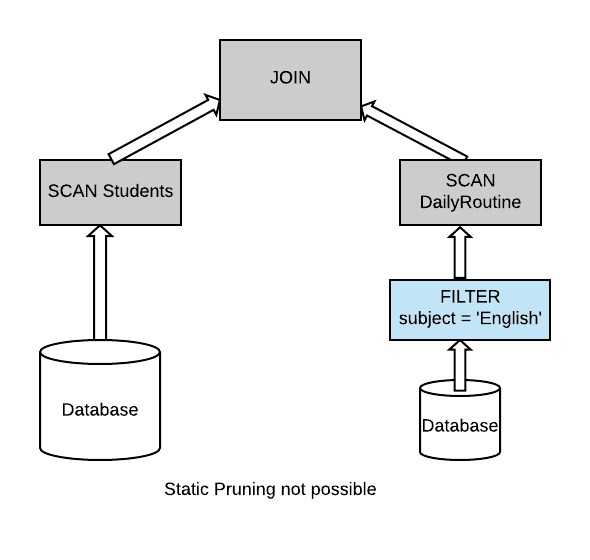
其能夠在一張表里面先過濾一些無用的數(shù)據(jù),再進(jìn)行 Join,效率自然比前面一種好。但是如果是我們?nèi)藖砼鋵?shí)我們可以把 subject = 'English' 過濾條件下推到 iteblog.Students 表里面,這個(gè)正是 Spark 3.0 給我們帶來的動(dòng)態(tài)分區(qū)裁剪優(yōu)化。
動(dòng)態(tài)分區(qū)裁剪
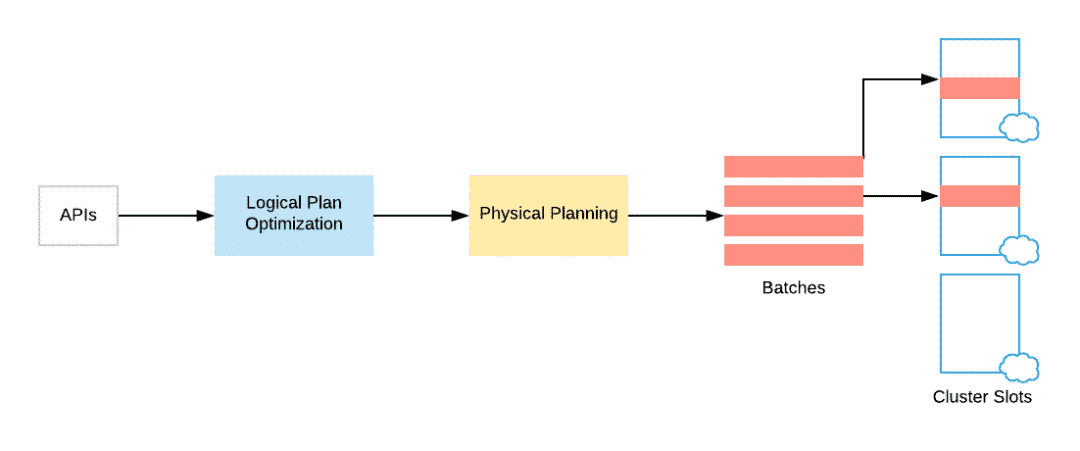
在 Spark SQL 中,用戶通常用他們喜歡的編程語言并選擇他們喜歡的 API 來提交查詢,這也就是為什么有 DataFrames 和 DataSet。Spark 將這個(gè)查詢轉(zhuǎn)化為一種易于理解的形式,我們稱它為查詢的邏輯計(jì)劃(logical plan)。在此階段,Spark 通過應(yīng)用一組基于規(guī)則(rule based)的轉(zhuǎn)換(如列修剪、常量折疊、算子下推)來優(yōu)化邏輯計(jì)劃。然后,它才會(huì)進(jìn)入查詢的實(shí)際物理計(jì)劃(physical planning)。在物理規(guī)劃階段 Spark 生成一個(gè)可執(zhí)行的計(jì)劃(executable plan),該計(jì)劃將計(jì)算分布在集群中。本文我將解釋如何在邏輯計(jì)劃階段實(shí)現(xiàn)動(dòng)態(tài)分區(qū)修剪。然后,我們將研究如何在物理計(jì)劃階段中進(jìn)一步優(yōu)化它。
邏輯計(jì)劃階段優(yōu)化
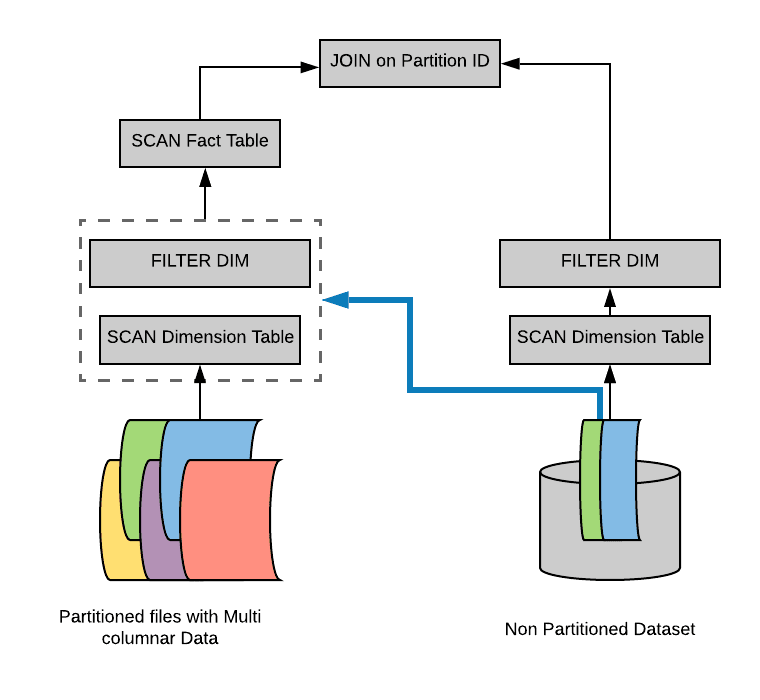
假設(shè)我們有一個(gè)具有多個(gè)分區(qū)的事實(shí)表(fact table),為了方便說明,我們用不同顏色代表不同的分區(qū)。另外,我們還有一個(gè)比較小的維度表(dimension table),我們的維度表不是分區(qū)表。然后我們?cè)谶@些數(shù)據(jù)集上進(jìn)行典型的掃描操作。在我們的例子里面,假設(shè)我們只讀取維度表里面的兩行數(shù)據(jù),而這兩行數(shù)據(jù)其實(shí)對(duì)于另外一張表的兩個(gè)分區(qū)。所以最后執(zhí)行 Join 操作時(shí),帶有分區(qū)的事實(shí)表只需要讀取兩個(gè)分區(qū)的數(shù)據(jù)就可以。
因此,我們不需要實(shí)際掃描整個(gè)事實(shí)表。為了做到這種優(yōu)化,一種簡(jiǎn)單的方法是通過維度表構(gòu)造出一個(gè)過濾子查詢(比如上面例子為 select subject from iteblog.DailyRoutine where subject = 'English'),然后在掃描事實(shí)表之前加上這個(gè)過濾子查詢。
通過這種方式,我們?cè)谶壿嬘?jì)劃階段就知道事實(shí)表需要掃描哪些分區(qū)。
但是,上面的物理計(jì)劃執(zhí)行起來還是比較低效。因?yàn)槔锩嬗兄貜?fù)的子查詢,我們需要找出一種方法來消除這個(gè)重復(fù)的子查詢。為了做到這一點(diǎn),Spark 在物理計(jì)劃階段做了一些優(yōu)化。
物理計(jì)劃階段優(yōu)化
如果維度表很小,那么 Spark 很可能會(huì)以 broadcast hash join 的形式執(zhí)行這個(gè) Join。Broadcast Hash Join 的實(shí)現(xiàn)是將小表的數(shù)據(jù)廣播(broadcast)到 Spark 所有的 Executor 端,這個(gè)廣播過程和我們自己去廣播數(shù)據(jù)沒什么區(qū)別,先利用 collect 算子將小表的數(shù)據(jù)從 Executor 端拉到 Driver 端,然后在 Driver 端調(diào)用 sparkContext.broadcast 廣播到所有 Executor 端;另一方面,大表也會(huì)構(gòu)建 hash table(稱為 build relation),之后在 Executor 端這個(gè)廣播出去的數(shù)據(jù)會(huì)和大表的對(duì)應(yīng)的分區(qū)進(jìn)行 Join 操作,這種 Join 策略避免了 Shuffle 操作。具體如下:
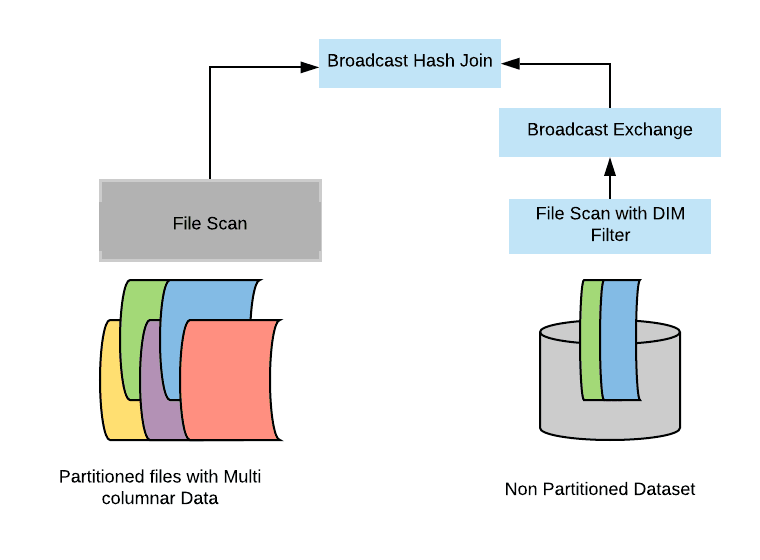
我們已經(jīng)知道了 broadcast hash join 實(shí)現(xiàn)原理。其實(shí)動(dòng)態(tài)分區(qū)裁剪優(yōu)化就是在 broadcast hash join 中大表進(jìn)行 build relation 的時(shí)候拿到維度表的廣播結(jié)果(broadcast results),然后在 build relation 的時(shí)候(Scan 前)進(jìn)行動(dòng)態(tài)過濾,從而達(dá)到避免掃描無用的數(shù)據(jù)效果。具體如下:
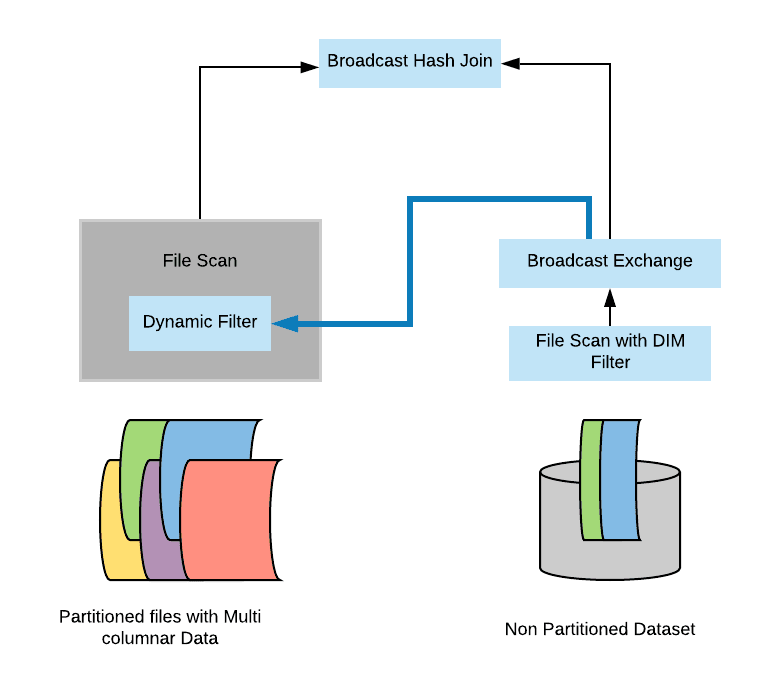
好了,以上就是動(dòng)態(tài)分區(qū)裁剪在邏輯計(jì)劃和物理計(jì)劃的優(yōu)化。
動(dòng)態(tài)分區(qū)裁剪適用條件
并不是什么查詢都會(huì)啟用動(dòng)態(tài)裁剪優(yōu)化的,必須滿足以下幾個(gè)條件:
- spark.sql.optimizer.dynamicPartitionPruning.enabled 參數(shù)必須設(shè)置為 true,不過這個(gè)值默認(rèn)就是啟用的;
- 需要裁減的表必須是分區(qū)表,而且分區(qū)字段必須在 join 的 on 條件里面;
- Join 類型必須是 INNER, LEFT SEMI (左表是分區(qū)表), LEFT OUTER (右表是分區(qū)表), or RIGHT OUTER (左表是分區(qū)表)。
- 滿足上面的條件也不一定會(huì)觸發(fā)動(dòng)態(tài)分區(qū)裁減,還必須滿足 spark.sql.optimizer.dynamicPartitionPruning.useStats 和 spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio 兩個(gè)參數(shù)綜合評(píng)估出一個(gè)進(jìn)行動(dòng)態(tài)分區(qū)裁減是否有益的值,滿足了才會(huì)進(jìn)行動(dòng)態(tài)分區(qū)裁減。評(píng)估函數(shù)實(shí)現(xiàn)請(qǐng)參見 org.apache.spark.sql.dynamicpruning.PartitionPruning#pruningHasBenefit。
本文主要翻譯自:https://blog.knoldus.com/dynamic-partition-pruning-in-spark-3-0/