Hive 中的四種排序詳解,再也不會混淆用法了
本文轉載自微信公眾號「Java大數據與數據倉庫」,作者劉不二。轉載本文請聯系Java大數據與數據倉庫公眾號。
Hive 中的四種排序
排序操作是一個比較常見的操作,尤其是在數據分析的時候,我們往往需要對數據進行排序,hive 中和排序相關的有四個關鍵字,今天我們就看一下,它們都是什么作用。
數據準備
下面我們有一份溫度數據,tab 分割
- 2008 32.0
- 2008 21.0
- 2008 31.5
- 2008 17.0
- 2013 34.0
- 2015 32.0
- 2015 33.0
- 2015 15.9
- 2015 31.0
- 2015 19.9
- 2015 27.0
- 2016 23.0
- 2016 39.9
- 2016 32.0
建表加載數據
- create table ods_temperature(
- `year` int,
- temper float
- )
- row format delimited fields terminated by '\t';
- load data local inpath '/Users/liuwenqiang/workspace/hive/temperature.data' overwrite into table ods_temperature;
1. order by(全局排序)
order by會對輸入做全局排序,因此只有一個Reducer(多個Reducer無法保證全局有序),然而只有一個reducer,會導致當輸入規模較大時,消耗較長的計算時間。
- 降序:desc
- 升序:asc 不需要指定,默認是升序
需要注意的是它受hive.mapred.mode的影響,在嚴格模式下,必須使用limit 對排序的數據量進行限制,因為數據量很大只有一個reducer的話,會出現OOM 或者運行時間超長的情況,所以嚴格模式下,不適用limit 則會報錯,更多請參考Hive的嚴格模式和本地模式。
- Error: Error while compiling statement: FAILED: SemanticException 1:39 Order by-s without limit are disabled for safety reasons. If you know what you are doing, please set hive.strict.checks.orderby.no.limit to false and make sure that hive.mapred.mode is not set to 'strict' to proceed. Note that you may get errors or incorrect results if you make a mistake while using some of the unsafe features.. Error encountered near token 'year' (state=42000,code=40000)
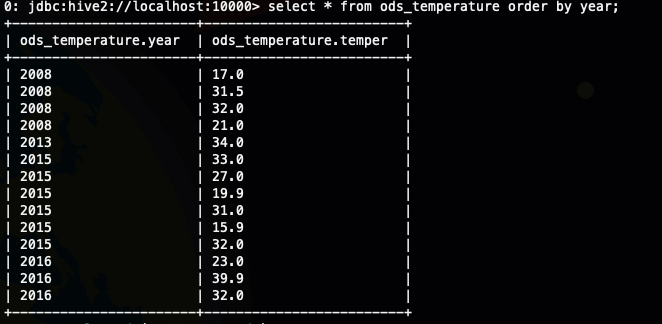
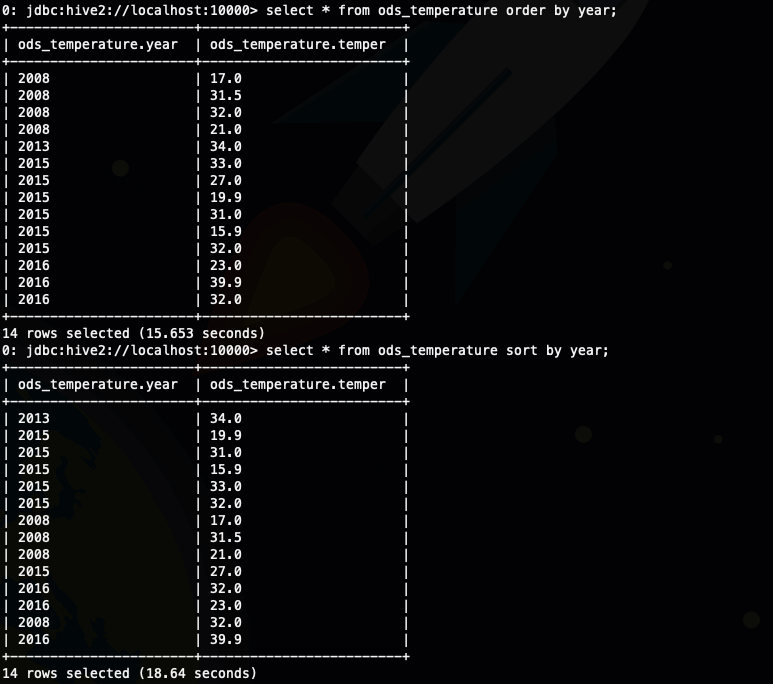
接下來我們看一下order by的排序結果select * from ods_temperature order by year;
2. sort by(分區內排序)
不是全局排序,其在數據進入reducer前完成排序,也就是說它會在數據進入reduce之前為每個reducer都產生一個排序后的文件。因此,如果用sort by進行排序,并且設置mapreduce.job.reduces>1,則sort by只保證每個reducer的輸出有序,不保證全局有序。
它不受Hive.mapred.mode屬性的影響,sort by的數據只能保證在同一個reduce中的數據可以按指定字段排序。使用sort by你可以指定執行的reduce個數(通過set mapred.reduce.tasks=n來指定),對輸出的數據再執行歸并排序,即可得到全部結果。
- set mapred.reduce.tasks=3;
- select * from ods_temperature sort by year;
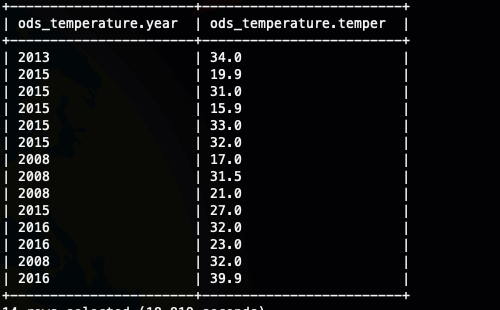
發現上面的輸出好像看不出來啥,只能看到不是有序的,哈哈,那我們換一種方法,將數據輸出到文件,因為我們設置了reduce數是3,那應該會有三個文件輸出。
- set mapred.reduce.tasks=3;
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t' select * from ods_temperature sort by year;
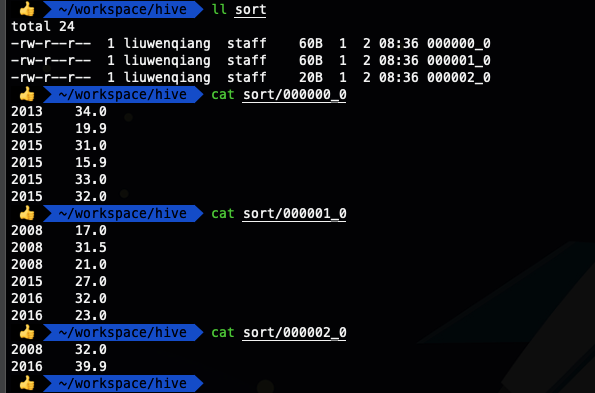
可以看出這下就清楚多了,我們看到一個分區內的年份并不同意,那個年份的數據都有。
sort by 和order by 的執行效率
首先我們看一個現象,一般情況下我們認為sort by 應該是比 order by 快的,因為 order by 只能使用一個reducer,進行全部排序,但是當數據量比較小的時候就不一定了,因為reducer 的啟動耗時可能遠遠數據處理的時間長,就像下面的例子order by 是比sort by快的。
sort by 中的limt
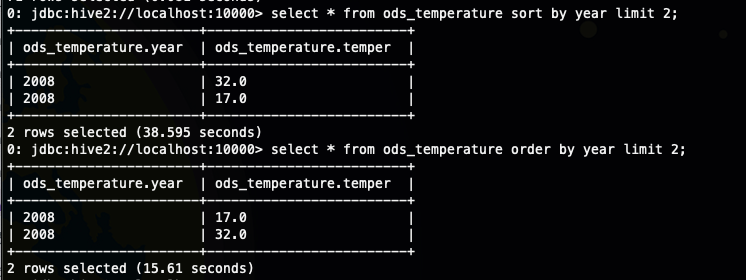
可以在sort by 用limit子句減少數據量,使用limit n 后,傳輸到reduce端的數據記錄數就減少到 n *(map個數),也就是說我們在sort by 中使用limit 限制的實際上是每個reducer 中的數量,然后再根據sort by的排序字段進行order by,最后返回n 條數據給客戶端,也就是說你在sort by 用limit子句,最后還是會使用order by 進行最后的排序。
order by 中使用limit 是對排序好的結果文件去limit 然后交給reducer,可以看到sort by 中limit 子句會減少參與排序的數據量,而order by 中的不行,只會限制返回客戶端數據量的多少。
從上面的執行效率,我們看到sort by limit 幾乎是 order by limit 的兩倍了 ,大概猜出來應該是多了某個環節。
接下來我們分別看一下order by limit 和 sort by limit 的執行計劃
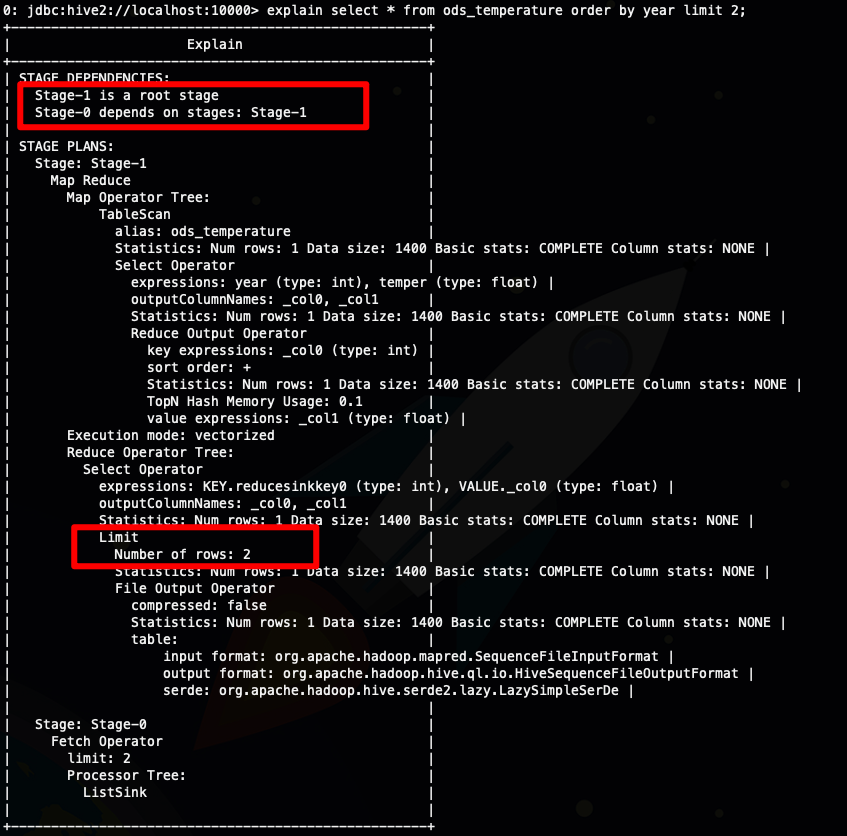
- explain select * from ods_temperature order by year limit 2;
- explain select * from ods_temperature sort by year limit 2;
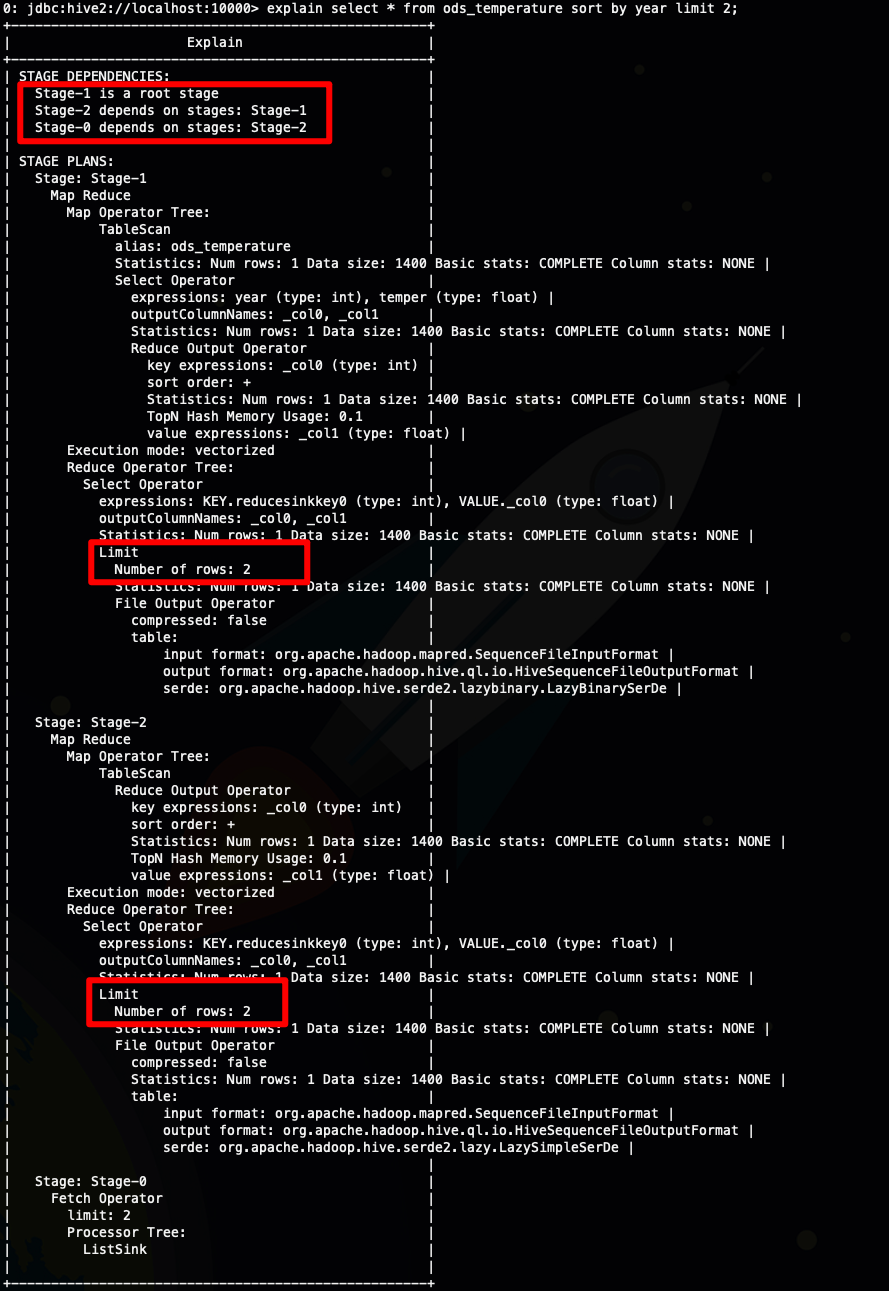
從上面截圖我圈出來的地方可以看到
sort by limit 比 order by limit 多出了一個stage(order limit)
sort by limit 實際上執行了兩次limit ,減少了參與排序的數據量
3. distribute by(數據分發)
distribute by是控制在map端如何拆分數據給reduce端的。類似于MapReduce中分區partationer對數據進行分區
hive會根據distribute by后面列,將數據分發給對應的reducer,默認是采用hash算法+取余數的方式。
sort by為每個reduce產生一個排序文件,在有些情況下,你需要控制某寫特定的行應該到哪個reducer,這通常是為了進行后續的聚集操作。distribute by剛好可以做這件事。因此,distribute by經常和sort by配合使用。
例如上面的sort by 的例子中,我們發現不同年份的數據并不在一個文件中,也就說不在同一個reducer 中,接下來我們看一下如何將相同的年份輸出在一起,然后按照溫度升序排序
首先我們嘗試一下沒有distribute by 的SQL的實現
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t' select * from ods_temperature sort by temper ;
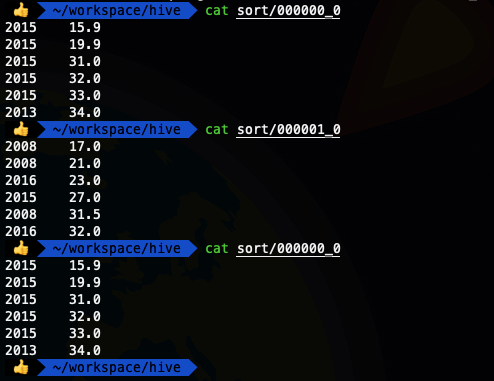
發現結果并沒有把相同年份的數據分配在一起,接下來我們使用一下distribute by
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
- select * from ods_temperature distribute by year sort by temper ;
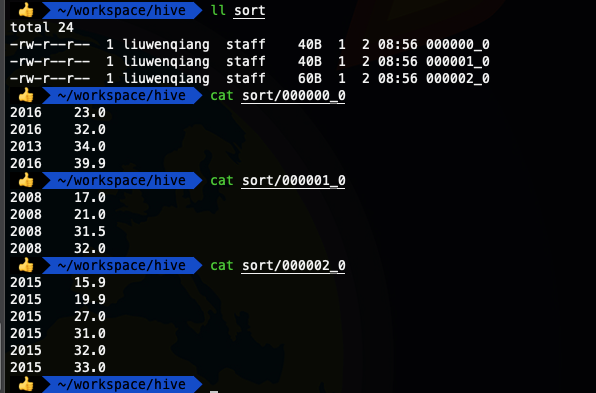
這下我們看到相同年份的都放在了一下,可以看出2013 和 2016 放在了一起,但是沒有一定順序,這個時候我們可以對 distribute by 字段再進行一下排序
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
- select * from ods_temperature distribute by year sort by year,temper ;
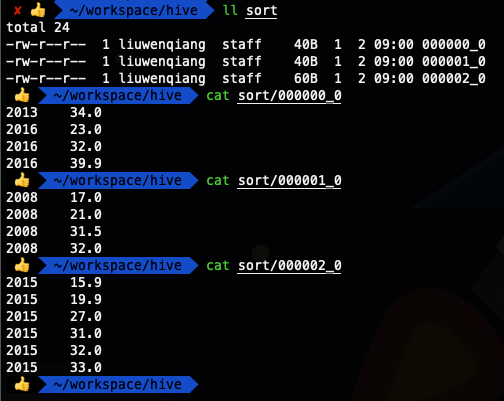
4. cluster by
cluster by除了具有distribute by的功能外還兼具sort by的功能。但是排序只能是升序排序,不能指定排序規則為ASC或者DESC。
當分區字段和排序字段相同cluster by可以簡化distribute by+sort by 的SQL 寫法,也就是說當distribute by和sort by 字段相同時,可以使用cluster by 代替distribute by和sort by
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
- select * from ods_temperature distribute by year sort by year ;
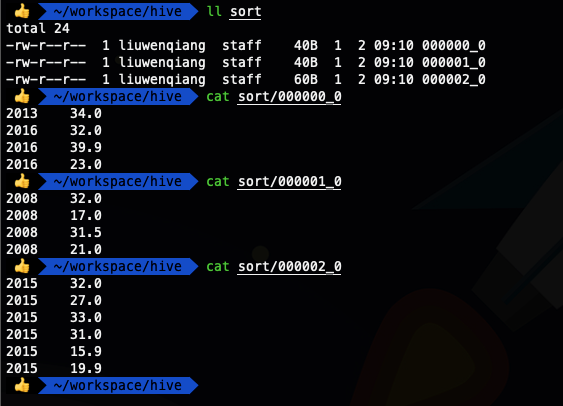
- insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields terminated by '\t'
- select * from ods_temperature cluster by year;
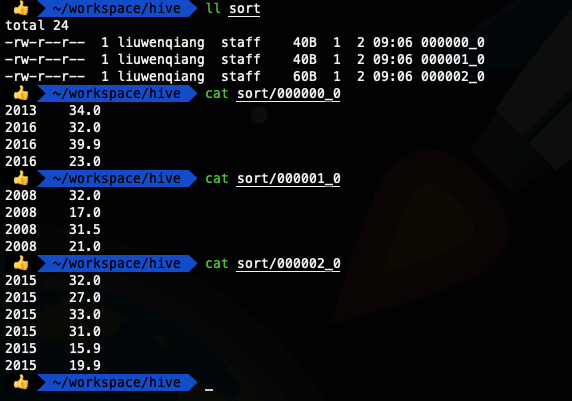
我們看到上面兩種SQL寫法的輸出結果是一樣的,這也就證明了我們的說法,當distribute by和sort by 字段相同時,可以使用cluster by 代替distribute by和sort by
當你嘗試給cluster by 指定排序方向的時候,你就會得到如下錯誤。
- Error: Error while compiling statement: FAILED: ParseException line 2:46 extraneous input 'desc' expecting EOF near '<EOF>' (state=42000,code=40000)
總結
order by 是全局排序,可能性能會比較差;
sort by分區內有序,往往配合distribute by來確定該分區都有那些數據;
distribute by 確定了數據分發的規則,滿足相同條件的數據被分發到一個reducer;
cluster by 當distribute by和sort by 字段相同時,可以使用cluster by 代替distribute by和sort by,但是cluster by默認是升序,不能指定排序方向;
sort by limit 相當于每個reduce 的數據limit 之后,進行order by 然后再limit ;