除了獨熱編碼,你需要了解將分類特征轉換為數字特征的17種方法
"您知道哪個梯度提升?"
" Xgboost,LightGBM,Catboost,HistGradient。"
"您知道哪種分類編碼?"
"One Hot"
在數據科學采訪中聽到這樣的對話我不會感到驚訝。盡管如此,這還是很驚人的,因為只有一小部分數據科學項目涉及機器學習,而實際上所有這些項目都涉及一些分類數據。
分類編碼是將分類列轉換為一個(或多個)數字列的過程。
這是必要的,因為計算機更容易處理數字而不是字符串。這是為什么?因為使用數字很容易找到關聯(例如"更大","更小","兩倍","一半")。而給定字符串時,計算機只能說"相等"還是"不同"。
但是,盡管有分類編碼,但數據科學從業人員很容易忽略分類編碼。
分類編碼是一個令人驚訝地被低估的話題。
這就是為什么我決定加深對編碼算法的了解。我從一個名為" category_encoders"的Python庫開始(這是Github鏈接)。使用它很容易:
- !pip install category_encodersimport category_encoders as cece.OrdinalEncoder().fit_transform(x)
這篇文章是庫中包含的17種編碼算法的演練。對于每種算法,我用幾行代碼提供了簡短的解釋和Python實現。這樣做的目的不是要重新發明輪子,而是要了解算法是如何在后臺運行的。畢竟,
"您不了解它,直到您可以對其進行編碼"。
并非所有編碼均相等
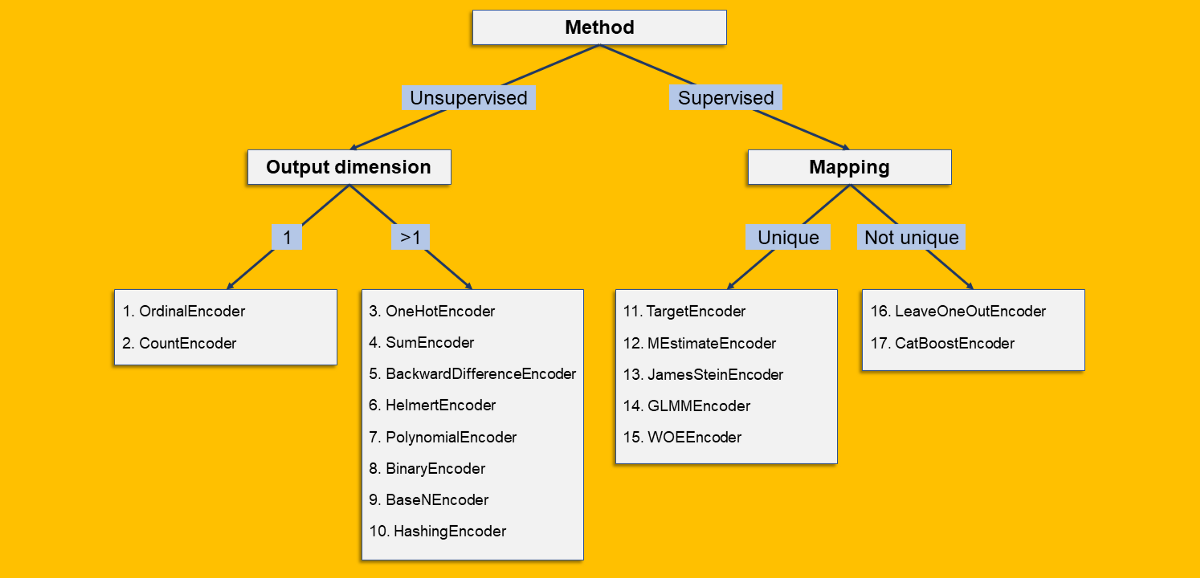
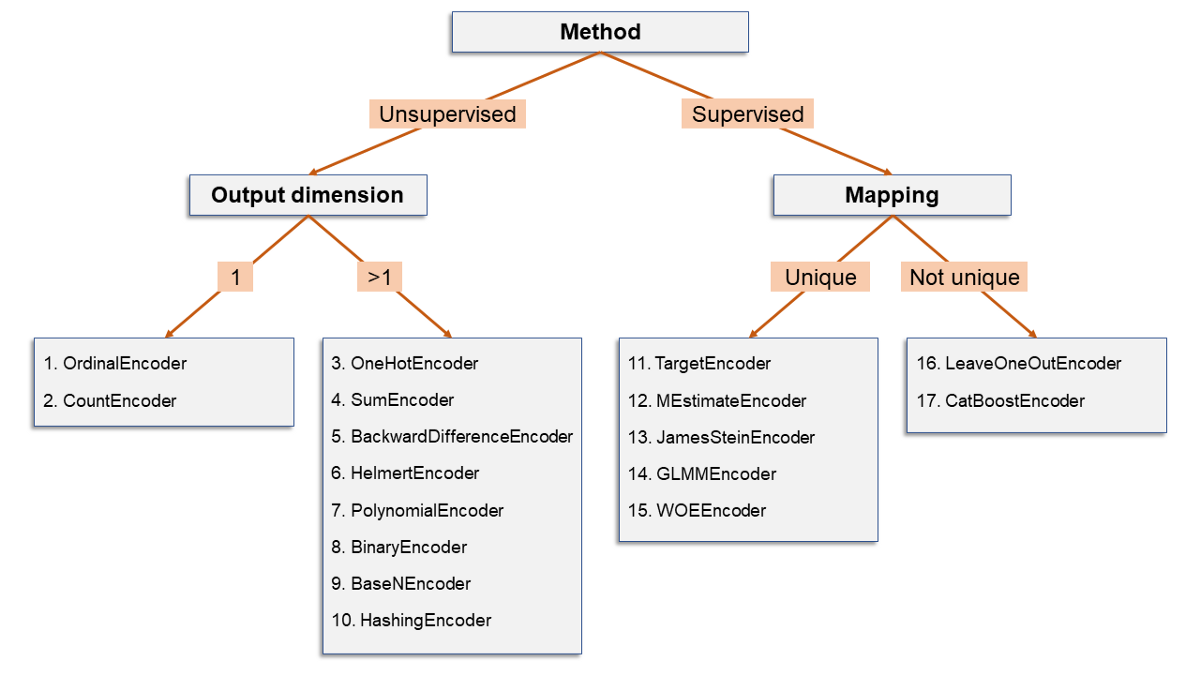
我已經根據其一些特征對17種編碼算法進行了分類。由于數據科學家喜歡決策樹,因此讓他們感到高興:
> [Image by Author]
以下是拆分所指的內容:
- 有監督/無監督:當編碼僅基于分類列時,則為無監督。否則,如果編碼基于原始列和第二個(數字)列的某些功能,那么它將受到監督。
- 輸出維:分類列的編碼可能會產生一個數字列(輸出維= 1)或許多數字列(輸出維> 1)。
- 映射:如果每個級別始終具有相同的輸出(無論是標量(例如OrdinalEncoder)還是數組(例如OneHotEncoder)),則映射是唯一的。相反,如果"允許"同一級別具有不同的可能輸出,則映射不是唯一的。
10分鐘內17種分類編碼算法
1. OrdinalEncoder
每個級別都映射到一個從1到L的整數(其中L是級別數)。在這種情況下,我們使用字母順序,但是任何其他自定義順序也是可以接受的。

> [Image by Author]
您可能會認為序數編碼是無意義的,尤其是在級別沒有固有順序的情況下。你是對的!實際上,它只是方便的一種表示形式,通常用于節省內存或用作其他類型編碼的中間步驟。
2. CountEncoder
每個級別都映射到承載該級別的觀測數量。
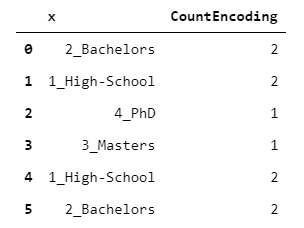
> [Image by Author]
該編碼可以用作指示每個級別的"可信度"的指標。例如,機器學習算法可以自動決定僅考慮其級別高于某個閾值的級別所帶來的信息。
3. OneHotEncoder
卓越(最常用)的編碼算法。每個級別都映射到一個虛擬列(即0/1列),指示該級別是否由該行承載。
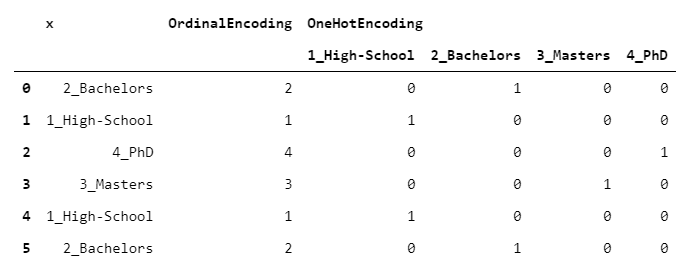
> [Image by Author]
這意味著,盡管您的輸入是單個列,但是您的輸出卻包含L列(原始列的每一級一個)。這就是為什么要謹慎處理一鍵編碼的原因:您最終可能會得到一個比原始數據幀大得多的數據幀。
一次性對數據進行熱編碼后,便可以使用任何預測算法。為了讓您一眼就能理解,我們對每個級別進行一次觀察。假設我們已經觀察到一個目標變量y,其中包含每個人的收入(以千美元計)。讓我們在數據上擬合線性回歸(OLS)。
為了使結果易于閱讀,我將OLS系數附加在桌子的側面。
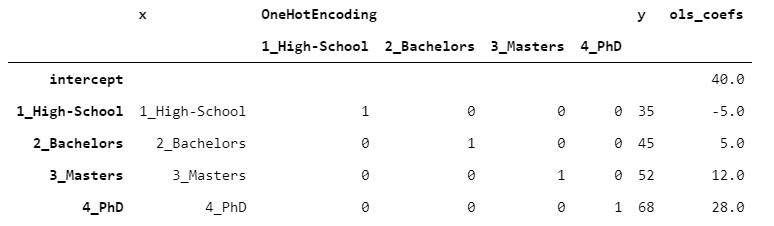
> [Image by Author]
在單熱編碼的情況下,截距沒有特殊含義,并且將系數添加到截距中以獲得估計。在這種情況下,由于每個級別只有一個觀測值,因此通過將截距和系數相加,我們可以獲得y的精確值(沒有錯誤)。
4. SumEncoder
最初的代碼看起來有些晦澀。但請放心:在這種情況下,了解編碼的獲取方式不是那么重要,而是如何使用它。
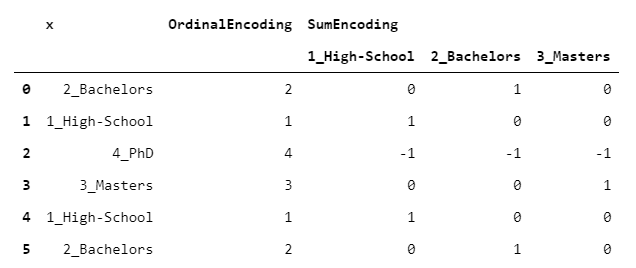
> [Image by Author]
SumEncoder(作為接下來的3個編碼器)屬于一個稱為"對比度編碼"的類。這些編碼設計用于回歸問題時具有特定的行為。換句話說,如果希望回歸系數具有某些特定屬性,則可以使用這些編碼之一。
特別是,當您希望回歸系數具有零和時,將使用SumEncoder。如果我們采用與上段相同的數據并適合OLS,則可以得到以下結果:
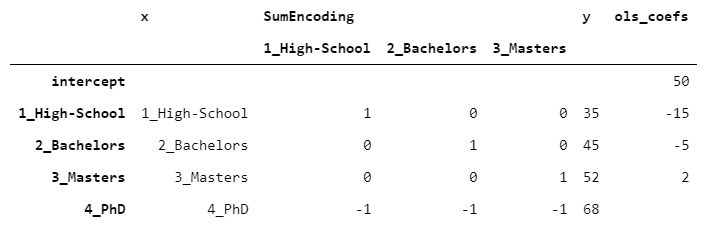
> [Image by Author]
這次,截距對應于y的平均值。此外,通過取最后一級的y并將其從截距(68-50)中減去,我們得到18,這與其余系數的總和(-15-5 + 2 = -18)正好相反。這正是我上面提到的求和編碼的屬性。
5. BackwardDifferenceEncoder
另一種對比編碼(如SumEncoder)。
該編碼器對于序數變量(即,其級別可以以有意義的方式進行排序的變量)很有用。BackwardDifferenceEncoder旨在比較相鄰級別。
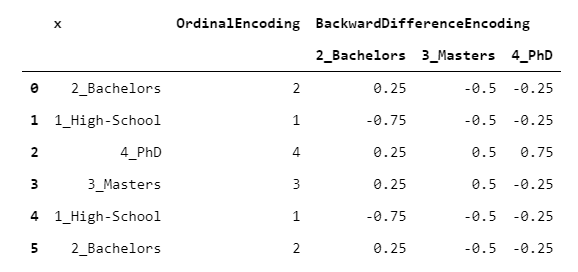
> [Image by Author]
假設您有一個普通變量(例如學歷),并且想知道它與數字變量(例如收入)之間的關系。比較目標變量的每兩個連續級別(例如,學士與高中,碩士與學士)可能很有趣。這就是BackwardDifferenceEncoder設計的目的。讓我們來看一個示例,上面的段落中的數據相同。
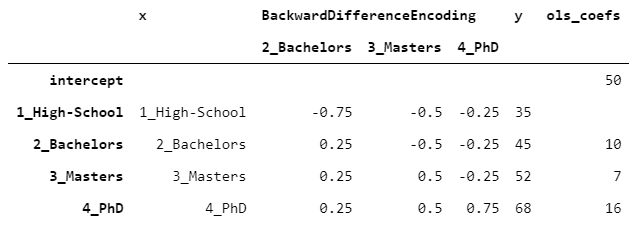
> [Image by Author]
截距與y的平均值重合。單身漢的系數為10,因為單身漢的y比高中的高10,而碩士的系數等于7,因為單身漢的y比高中的高7,依此類推。
6. HelmertEncoder
HelmertEncoder與BackwardDifferenceEncoder非常相似,但是不僅將其與上一個進行比較,還將每個級別與所有先前的級別進行比較。
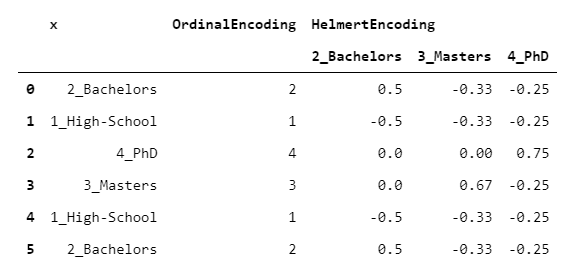
> [Image by Author]
讓我們看看從OLS模型可以得到什么:
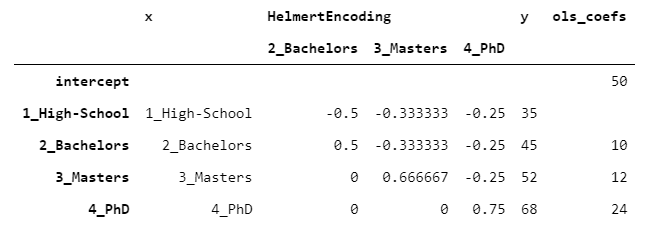
> [Image by Author]
PhD的系數為24,因為PhD比先前水平68-((35 + 45 + 52)/ 3)= 24的平均值高24。相同的推理適用于所有級別。
7. 多項式編碼器
另一種對比編碼。
顧名思義,PolynomialEncoder旨在量化目標變量相對于分類變量的線性,二次和三次行為。
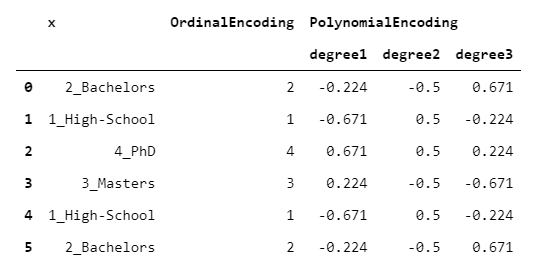
> [Image by Author]
我知道你在想什么數字變量如何與非數字變量具有線性(或二次或三次)關系?這是基于以下假設:基礎分類變量具有不僅可觀的而且均等間隔的級別。
因此,建議您僅在確信假設合理的情況下謹慎使用它。
8. BinaryEncoder
BinaryEncoder與OrdinalEncoder基本相同,唯一的區別是將整數轉換為二進制數,然后每個位置數字都進行一次熱編碼。
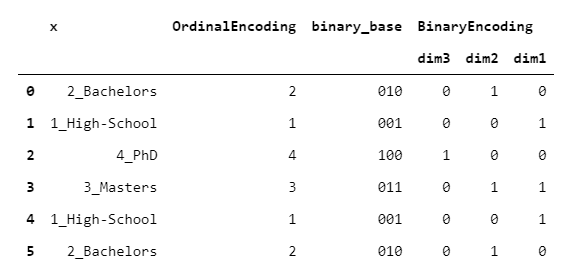
> [Image by Author]
輸出由偽列組成(就像OneHotEncoder一樣),但是它導致單熱點的尺寸減少。
老實說,我不知道這種編碼的任何實際應用(如果您愿意,請在下面發表評論!)。
9. BaseNEncoder
BaseNEncoder只是BinaryEncoder的概括。實際上,在BinaryEncoder中,數字以2為底,而在BaseNEncoder中,數字以n為底,n大于1。
讓我們看一個以base = 3為例的例子。
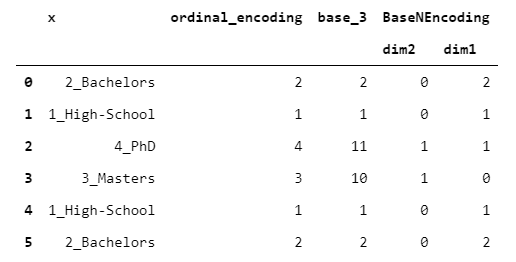
> [Image by Author]
老實說,我不知道這種編碼的任何實際應用(如果您愿意,請在下面發表評論!)。
10. HashingEncoder
在HashingEncoder中,使用某種哈希算法(例如SHA-256)對每個原始級別進行哈希處理。然后,將結果轉換為整數,并采用該整數相對于某個(大)除數的模塊。這樣,我們將每個原始字符串映射到1到divisor-1之間的整數。最后,通過此過程獲得的整數是一熱編碼的。
我們來看一個output_dimension = 10的示例。

> [Image by Author]
哈希的基本屬性是所得整數均勻分布。因此,如果將除數足夠大,則不可能將兩個不同的字符串映射到相同的整數。為什么這樣有用?實際上,這有一個非常實用的應用程序,稱為"哈希技巧"。
想象一下,您想使用Logistic回歸進行電子郵件垃圾郵件分類。您可以通過對數據集中的所有單詞進行一次熱編碼來做到這一點。主要缺點是您需要將映射存儲在單獨的字典中,并且模型尺寸會在出現新字符串時隨時更改。
使用哈希技巧可以輕松解決這些問題,因為通過對輸入進行哈希處理,您不再需要字典,并且輸出尺寸是固定的(僅取決于您最初選擇的除數)。而且,對于散列的屬性,您可以肯定的是,新字符串的編碼可能會與現有字符串不同。
11. TargetEncoder
假設您有兩個變量:一個類別(x)和一個數字(y)。假設您要將x轉換為數字變量。您可能希望使用y"攜帶"的信息。一個明顯的想法是對x的每個級別取y的平均值。在公式中:
這是合理的,但是這種方法存在一個大問題:某些小組可能太小或太不穩定而無法可靠。許多監督編碼通過選擇y的組均值和全局均值之間的中間方法來克服此問題:
其中w_i在0到1之間,具體取決于組平均值的"可信度"。
接下來的三種算法(TargetEncoder,MEstimateEncoder和JamesSteinEncoder)基于它們定義w_i的方式而有所不同。
在TargetEncoder中,權重取決于組的數字和稱為"平滑"的參數。當平滑為0時,我們僅依靠組均值。然后,隨著平滑度的增加,全局平均權重越來越大,從而導致更強的正則化。
讓我們看看結果如何隨著一些不同的平滑值而變化。
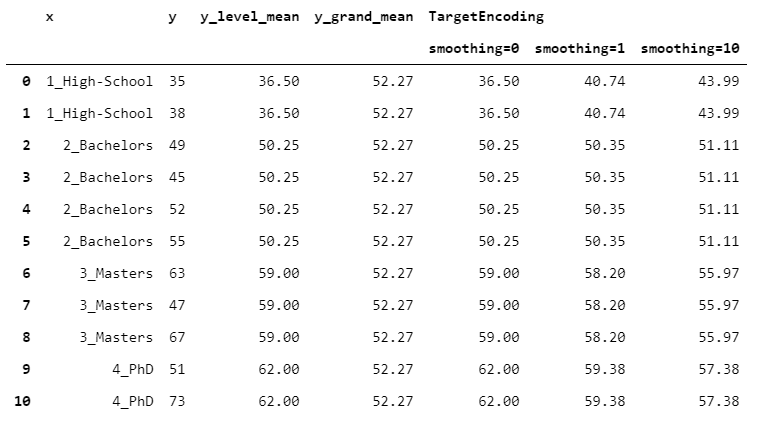
> [Image by Author]
12. MEstimateEncoder
MEstimateEncoder與TargetEncoder相似,但w_i取決于一個稱為" m"的參數,該參數設置全局平均值應按絕對值加權的大小。m很容易理解,因為它可以看作是多個觀察值:如果水平儀上有m個觀察儀,則水平儀的均值和總體平均權重相同。
讓我們看看不同m值的結果如何變化:
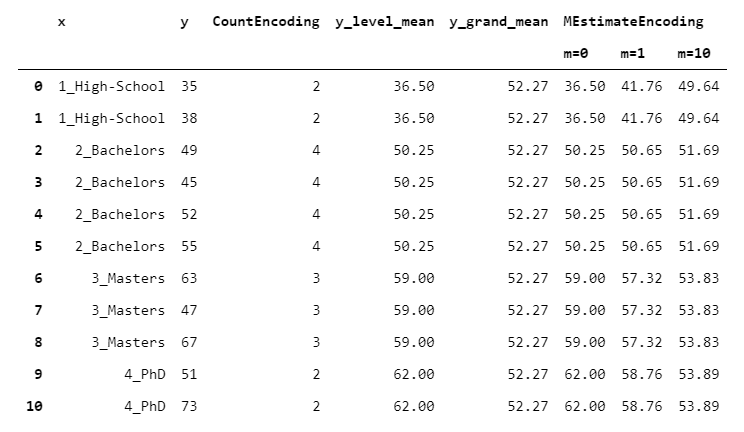
> [Image by Author]
13. JamesSteinEncoder
TargetEncoder和MEstimateEncoder既取決于組數字,也取決于用戶設置的參數值(分別是平滑和m)。這不方便,因為設置這些權重是一項手動任務。
下面是一個自然的問題:是否有一種方法可以在不需要任何人工干預的情況下設置最佳w_i?JamesSteinEncoder嘗試以統計為基礎的方式執行此操作。
直覺是,具有較高方差的組的均值應被較少信任。因此,組方差越高,權重越低(如果您想了解更多有關公式的信息,我建議克里斯·賽義德(Chris Said)發表此帖子)。
我們來看一個數字示例:
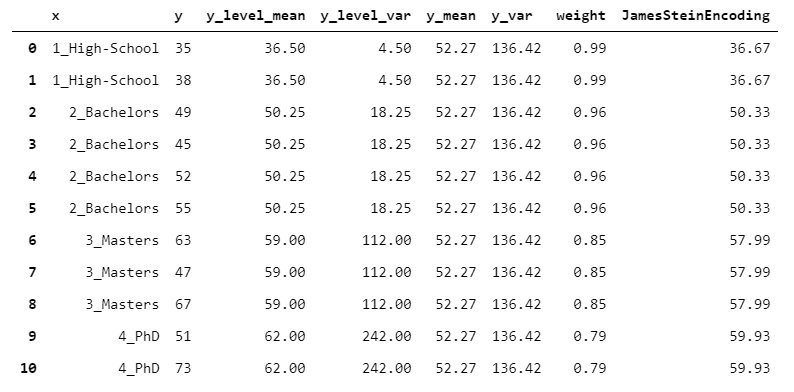
> [Image by Author]
JamesSteinEncoder具有兩個顯著優點:與最大似然估計器相比,它提供了更好的估計,并且不需要任何參數設置。
14. GLMMEncoder
GLMMEncoder采用完全不同的方法。基本上,它適合y上的線性混合效應模型。這種方法利用了以下事實:線性混合效應模型是專為處理同類觀察組而設計的(在此也有詳細說明)。因此,該想法是使模型不具有回歸變量(僅包含截距),并將級別用作組。
這樣,輸出就是截距和組的隨機效應之和。
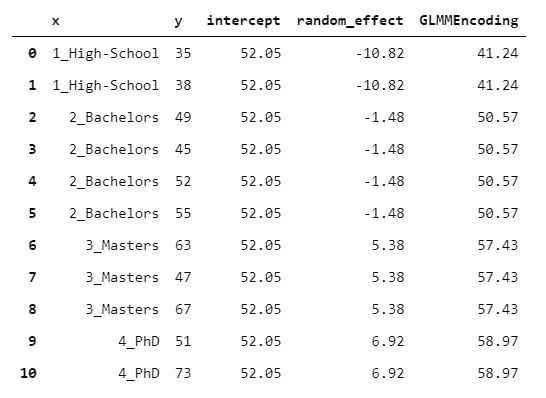
> [Image by Author]
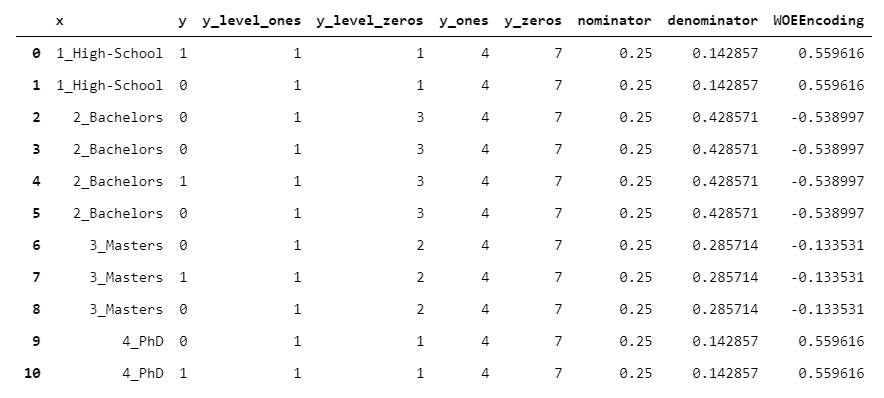
15. WOEEncoder
WOEEncoder(代表"證據權重"編碼器)只能用于二進制目標變量,即級別為0/1的目標變量。
證據權重背后的想法是,您有兩種分布:
- 1的分布(每組1個的數量/所有y中1的數量)
- 0的分布(每個組中的0個數/所有y中的0個數)
該算法的核心是將1s的分布除以0s的分布(對于每個組)。當然,該值越高,我們越有信心該組"偏向" 1,反之亦然。然后,取該值的對數。
> [Image by Author]
如您所見,由于公式中存在對數,因此無法直接解釋輸出。但是,它可以很好地用作機器學習的預處理步驟。
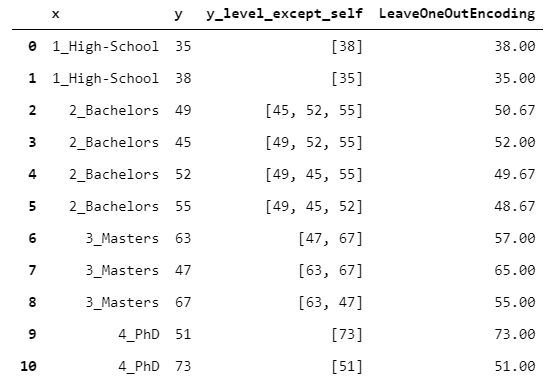
16. LeaveOneOutEncoder
到目前為止,所有15個編碼器都具有唯一的映射。
但是,如果您打算將編碼用作預測模型的輸入(例如,梯度增強),則可能會出現問題。實際上,假設您使用TargetEncoder。這意味著您將在X_train中引入有關y_train的信息,這可能會導致嚴重的過度擬合風險。
關鍵是:如何在限制過度擬合風險的同時保持監督編碼?LeaveOneOutEncoder提供了一個出色的解決方案。它執行原始目標編碼,但是對于每一行,它不考慮對該行觀察到的y值。這樣,避免了行泄漏。
> [Image by Author]
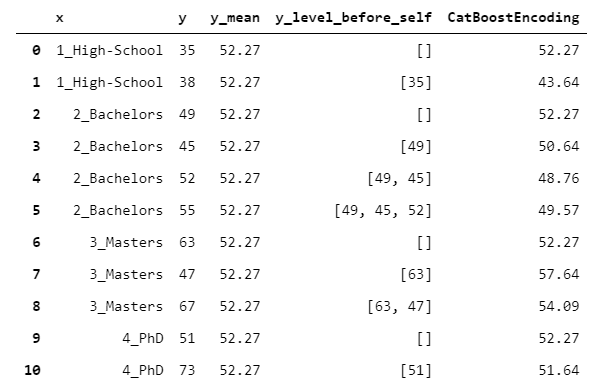
17. CatBoostEncoder
CatBoost是一種梯度增強算法(例如XGBoost或LightGBM),在各種問題上都表現得非常出色。此處對編碼算法進行了詳細說明(我們的實現略有簡化,但是對于掌握概念非常有用)。
CatboostEncoder的工作原理基本上與LeaveOneOutEncoder相似,但是遵循一種在線方法。
但是,如何在離線設置中模擬在線行為?假設您有一張桌子。然后,在桌子中間的某處劃一排。CatBoost的行為是假裝當前行上方的行先前已被及時觀察到,而下方行尚未被觀察到(即將來會被觀察到)。然后,該算法僅根據已經觀察到的行進行留一法編碼。
> [Image by Author]
這似乎很荒謬。為什么丟掉一些有用的信息?您可以將其視為對輸出進行隨機化的更極端嘗試(即減少過度擬合)。
您可以在此Github筆記本中找到帖子(以及更多內容)中的所有代碼。
感謝您的閱讀!我希望您發現這篇文章有用。