免費(fèi)Python機(jī)器學(xué)習(xí)課程九:K均值聚類(lèi)
K聚類(lèi)是什么意思?
K均值聚類(lèi)是最流行和廣泛使用的無(wú)監(jiān)督學(xué)習(xí)模型。它也稱(chēng)為群集,因?yàn)樗ㄟ^(guò)群集數(shù)據(jù)來(lái)工作。與監(jiān)督學(xué)習(xí)模型不同,非監(jiān)督模型不使用標(biāo)記數(shù)據(jù)。
該算法的目的不是預(yù)測(cè)任何標(biāo)簽。而是更好地了解數(shù)據(jù)集并對(duì)其進(jìn)行標(biāo)記。
在k均值聚類(lèi)中,我們將數(shù)據(jù)集聚類(lèi)為不同的組。
這是k均值聚類(lèi)算法的工作原理
(1) 第一步是隨機(jī)初始化一些點(diǎn)。這些點(diǎn)稱(chēng)為簇質(zhì)心。
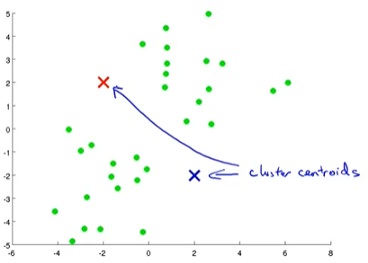
在上圖中,紅色和藍(lán)色點(diǎn)是群集質(zhì)心。
您可以選擇任意數(shù)量的群集質(zhì)心。但是簇質(zhì)心的數(shù)量必須少于數(shù)據(jù)點(diǎn)的總數(shù)。
(2) 第二步是群集分配步驟。在此步驟中,我們需要遍歷每個(gè)綠點(diǎn)。根據(jù)點(diǎn)是否更靠近紅色或藍(lán)色點(diǎn),我們需要將其分配給其中一個(gè)點(diǎn)。
換句話說(shuō),根據(jù)綠色點(diǎn)是紅色還是藍(lán)色來(lái)著色,具體取決于它是靠近藍(lán)色簇質(zhì)心還是紅色簇質(zhì)心。
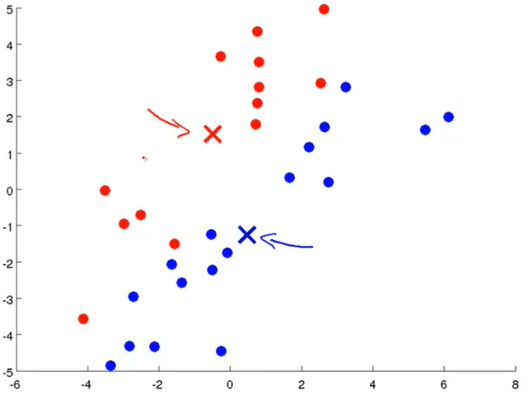
(3) 下一步是移動(dòng)群集質(zhì)心。現(xiàn)在,我們必須對(duì)分配給紅色聚類(lèi)質(zhì)心的所有紅點(diǎn)取平均值,然后將紅色聚類(lèi)質(zhì)心移至該平均值。我們需要對(duì)藍(lán)色簇質(zhì)心執(zhí)行相同的操作。
現(xiàn)在,我們有了新的簇質(zhì)心。我們必須回到編號(hào)2(集群分配步驟)。我們需要將點(diǎn)重新排列到新的群集質(zhì)心。在那之后重復(fù)第三。
數(shù)字2和3需要重復(fù)幾次,直到兩個(gè)聚類(lèi)質(zhì)心都位于合適的位置,如下圖所示。
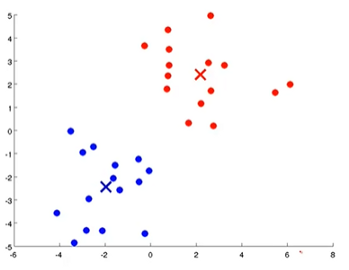
看,我們只是按照分配給它們的簇質(zhì)心對(duì)所有綠色點(diǎn)進(jìn)行了著色。藍(lán)色簇質(zhì)心位于藍(lán)色簇的中心,紅色簇質(zhì)心位于紅色簇的中心。
當(dāng)我們開(kāi)發(fā)該算法時(shí),將會(huì)稍微清楚一點(diǎn)。我們將對(duì)此進(jìn)行更詳細(xì)的討論。
開(kāi)發(fā)算法
我將用于此算法的數(shù)據(jù)集是從安德魯·伍(Andrew Ng)在Coursera的機(jī)器學(xué)習(xí)課程中獲得的。這是開(kāi)發(fā)k均值算法的分步指南:
(1) 導(dǎo)入必要的包和數(shù)據(jù)集
- import pandas as pd
- import numpy as np
- df1 = pd.read_excel('dataset.xlsx', sheet_name='ex7data2_X', header=None)
- df1.head()
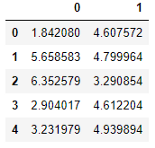
數(shù)據(jù)集只有兩列。我采用了兩個(gè)特色數(shù)據(jù)集,因?yàn)樗苋菀卓梢暬.?dāng)您看到視覺(jué)效果時(shí),該算法將對(duì)您更容易理解。但是,相同的算法也將適用于多維數(shù)據(jù)集。
我將DataFrame df1轉(zhuǎn)換為Numpy數(shù)組,因?yàn)槲覀儗⒃诖诉^(guò)程中處理其他數(shù)組:
- X = np.array(df1)
現(xiàn)在,我將按照上面討論的三個(gè)步驟進(jìn)行操作。
(2) 第一步是隨機(jī)初始化質(zhì)心。
我將從數(shù)據(jù)集中隨機(jī)初始化三個(gè)點(diǎn)。首先,我將在0和數(shù)據(jù)集長(zhǎng)度之間選擇三個(gè)數(shù)字。
- import randomrandominit_centroids = random.sample(range(0, len(df1)), 3)
- init_centroids
輸出:
- [95, 30, 17]
使用這三個(gè)數(shù)字作為索引,并獲取這些索引的數(shù)據(jù)點(diǎn)。
- centroids = []
- for i in init_centroids:
- centroids.append(df1.loc[i])
- centroids
輸出:
- [0 3.907793
- 1 5.094647
- Name: 95, dtype: float64,
- 0 2.660466
- 1 5.196238
- Name: 30, dtype: float64,
- 0 3.007089
- 1 4.678978
- Name: 17, dtype: float64]
這三點(diǎn)是我們最初的質(zhì)心。
我將它們轉(zhuǎn)換為二維數(shù)組。因?yàn)檫@是我比較熟悉的格式。
- centroids = np.array(centroids)
輸出:
- array([[3.90779317, 5.09464676],
- [2.66046572, 5.19623848],
- [3.00708934, 4.67897758]])
(3) 實(shí)施群集分配步驟。
在這一步中,我們將遍歷數(shù)據(jù)集中的所有數(shù)據(jù)點(diǎn)。
一個(gè)數(shù)據(jù)點(diǎn)表示一行數(shù)據(jù)
讓我們看一行數(shù)據(jù),了解如何將這些數(shù)據(jù)分配給集群。
我們將計(jì)算所有三個(gè)質(zhì)心的數(shù)據(jù)距離。然后將該數(shù)據(jù)點(diǎn)分配給距離最短的質(zhì)心。
如我們所見(jiàn),我們必須計(jì)算兩個(gè)點(diǎn)之間的許多距離。讓我們開(kāi)發(fā)一個(gè)計(jì)算距離的函數(shù)。
- def calc_distance(X1, X2):
- return(sum((X1 - X2)**2))**0.5
開(kāi)發(fā)一個(gè)函數(shù),將每個(gè)數(shù)據(jù)點(diǎn)分配給一個(gè)質(zhì)心。我們的"質(zhì)心"數(shù)組只有三個(gè)值。因此,我們有三個(gè)索引:0、1、2。我們將為每個(gè)數(shù)據(jù)點(diǎn)分配這些索引之一。
- def findClosestCentroids(ic, X):
- assigned_centroid = []
- for i in X:
- distance=[]
- for j in ic:
- distance.append(calc_distance(i, j))
- assigned_centroid.append(np.argmin(distance))
- return assigned_centroid
此功能是將數(shù)據(jù)點(diǎn)分配給群集的功能。讓我們使用此函數(shù)來(lái)計(jì)算每個(gè)數(shù)據(jù)點(diǎn)的質(zhì)心:
- get_centroids = findClosestCentroids(centroids, X)
- get_centroids
部分輸出:
- [2,
- 0,
- 0,
- 2,
- 1,
- 2,
- 2,
- 2,
- 1,
- 1,
- 2,
- 2,
- 2,
- 2,
- 2,
- 2,
- 0,
總輸出很長(zhǎng)。因此,我在這里顯示部分輸出。輸出中的第一個(gè)質(zhì)心為2,這意味著將其分配給質(zhì)心列表的索引2。
(4) 最后一步是根據(jù)數(shù)據(jù)點(diǎn)的平均值移動(dòng)質(zhì)心
在這一步中,我們將取每個(gè)質(zhì)心的所有數(shù)據(jù)點(diǎn)的平均值,然后將質(zhì)心移動(dòng)到該平均值。
例如,我們將在索引2處找到分配給質(zhì)心的所有點(diǎn)的平均值,然后將質(zhì)心2移至平均值。對(duì)索引0和1的質(zhì)心也執(zhí)行相同的操作。
讓我們定義一個(gè)函數(shù)來(lái)做到這一點(diǎn):
- def calc_centroids(clusters, X):
- new_centroids = []
- new_df = pd.concat([pd.DataFrame(X), pd.DataFrame(clusters, columns=['cluster'])],
- axis=1)
- for c in set(new_df['cluster']):
- current_cluster = new_df[new_df['cluster'] == c][new_df.columns[:-1]]
- cluster_mean = current_cluster.mean(axis=0)
- new_centroids.append(cluster_mean)
- return new_centroids
這些都是我們需要開(kāi)發(fā)的所有功能。
正如我之前所討論的,我們需要重復(fù)此群集分配過(guò)程,并多次移動(dòng)質(zhì)心,直到質(zhì)心處于合適的位置。
對(duì)于此問(wèn)題,我選擇重復(fù)此過(guò)程10次。我將在每次迭代后繼續(xù)繪制質(zhì)心和數(shù)據(jù),以直觀地向您展示其工作方式。
- for i in range(10):
- get_centroids = findClosestCentroids(centroids, X)
- centroids = calc_centroids(get_centroids, X)
- #print(centroids)
- plt.figure()
- plt.scatter(np.array(centroids)[:, 0], np.array(centroids)[:, 1], color='black')
- plt.scatter(X[:, 0], X[:, 1], alpha=0.1)
- plt.show()
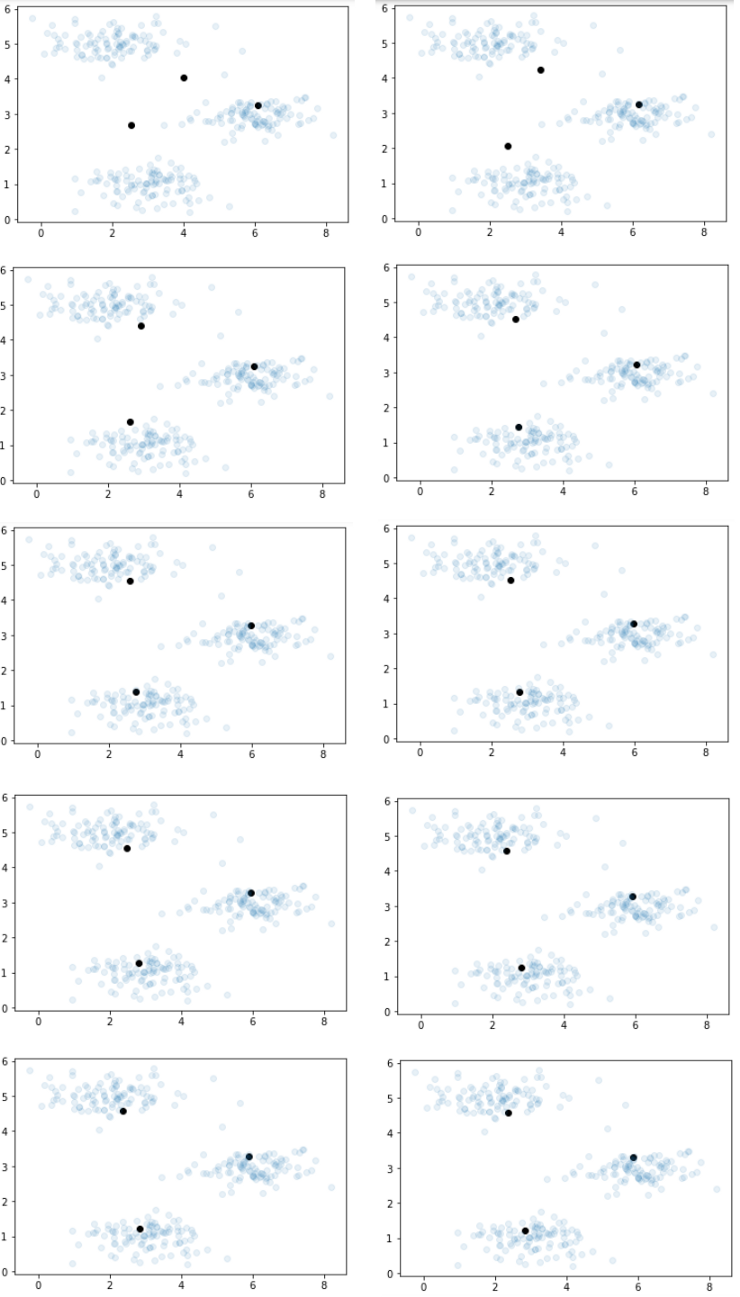
經(jīng)過(guò)五次迭代,將質(zhì)心設(shè)置為其最佳位置。因此,他們此后不再更改職位。
我建議,在嘗試降維之前,請(qǐng)運(yùn)行上面的所有代碼以使其學(xué)習(xí)好。
否則,您可能會(huì)感到不知所措!另外,由于我們已經(jīng)詳細(xì)解釋了該算法,因此我現(xiàn)在將加快執(zhí)行速度。
降維
我想解釋一下這種算法的至少一個(gè)用例。一種非常有用的用例是降維。
想一想圖像。圖像中可能有太多不同的像素。在任何計(jì)算機(jī)視覺(jué)問(wèn)題中,如果我們可以縮小圖片的尺寸,則設(shè)備讀取該圖片的速度將大大提高!是不是
我們可以使用剛剛開(kāi)發(fā)的算法來(lái)縮小圖片的尺寸。
我將使用青蛙的圖片來(lái)說(shuō)明這一點(diǎn):

> Image By Author
我將這張照片上傳到了與筆記本相同的文件夾中。讓我們導(dǎo)入這個(gè):
- import cv2
- im = cv2.imread('frog.png')
- im
輸出:
- array([[[ 2, 57, 20],
- [ 2, 57, 20],
- [ 2, 57, 21],
- ...,
- [ 0, 5, 3],
- [ 8, 12, 11],
- [ 91, 94, 93]], [[ 2, 56, 20],
- [ 1, 54, 20],
- [ 1, 56, 19],
- ...,
- [ 0, 2, 1],
- [ 7, 9, 8],
- [ 91, 92, 91]], [[ 2, 55, 20],
- [ 2, 53, 19],
- [ 1, 54, 18],
- ...,
- [ 2, 4, 2],
- [ 8, 11, 9],
- [ 91, 93, 91]], ..., [[ 6, 76, 27],
- [ 6, 77, 26],
- [ 6, 78, 28],
- ...,
- [ 6, 55, 18],
- [ 13, 61, 25],
- [ 94, 125, 102]], [[ 9, 79, 31],
- [ 11, 81, 33],
- [ 12, 82, 32],
- ...,
- [ 6, 56, 19],
- [ 14, 61, 27],
- [ 96, 126, 103]], [[ 43, 103, 63],
- [ 44, 107, 66],
- [ 46, 106, 66],
- ...,
- [ 37, 81, 50],
- [ 47, 88, 59],
- [118, 145, 126]]], dtype=uint8)
檢查數(shù)組的形狀,
- im.sgape
輸出:
- (155, 201, 3)
我將整個(gè)數(shù)組除以255,以使所有值從0到1。
然后將其重塑為155 * 201 x 3,使其成為二維數(shù)組。因?yàn)槲覀冎伴_(kāi)發(fā)了二維數(shù)組的所有函數(shù)。
- im = (im/255).reshape(155*201, 3)
如您在上方所見(jiàn),有許多不同的像素值。我們要減少它并僅保留10像素值。
讓我們初始化10個(gè)隨機(jī)索引,
- randomrandom_index = random.sample(range(0, len(im)), 10)
現(xiàn)在,像上一個(gè)示例一樣找到質(zhì)心:
- centroids = []
- for i in random_index:
- centroids.append(im[i])
- centroids = np.array(centroids)
輸出:
- array([[0.00392157, 0.21176471, 0.06666667],
- [0.03529412, 0.2627451 , 0.09803922],
- [0.29411765, 0.3254902 , 0.26666667],
- [0.00784314, 0.18431373, 0.05882353],
- [0.29019608, 0.49411765, 0.28235294],
- [0.5254902 , 0.61176471, 0.48627451],
- [0.04313725, 0.23921569, 0.09803922],
- [0.00392157, 0.23529412, 0.0745098 ],
- [0.00392157, 0.20392157, 0.04705882],
- [0.22352941, 0.48235294, 0.40784314]])
現(xiàn)在,我也將" im"轉(zhuǎn)換為數(shù)組,
- im = np.array(im)
數(shù)據(jù)準(zhǔn)備就緒。現(xiàn)在,我們可以繼續(xù)進(jìn)行集群過(guò)程。但是這次,我將不進(jìn)行可視化。因?yàn)閿?shù)據(jù)不再是二維的。因此,可視化并不容易。
- for i in range(20):
- get_centroids = findClosestCentroids(centroids, im)
- centroids = calc_centroids(get_centroids, im)
我們現(xiàn)在得到了更新的質(zhì)心。
- centroids
輸出:
- [0 0.017726
- 1 0.227360
- 2 0.084389
- dtype: float64,
- 0 0.119791
- 1 0.385882
- 2 0.247633
- dtype: float64,
- 0 0.155117
- 1 0.492051
- 2 0.331497
- dtype: float64,
- 0 0.006217
- 1 0.048596
- 2 0.019410
- dtype: float64,
- 0 0.258289
- 1 0.553290
- 2 0.406759
- dtype: float64,
- 0 0.728167
- 1 0.764610
- 2 0.689944
- dtype: float64,
- 0 0.073519
- 1 0.318513
- 2 0.170943
- dtype: float64,
- 0 0.035116
- 1 0.273665
- 2 0.114766
- dtype: float64,
- 0 0.010810
- 1 0.144621
- 2 0.053192
- dtype: float64,
- 0 0.444197
- 1 0.617780
- 2 0.513234
- dtype: float64]
這是最后一步。我們只會(huì)保留這10點(diǎn)。
如果還打印get_centroids,您將看到集群分配。
現(xiàn)在,我們要遍歷整個(gè)數(shù)組" im",并將數(shù)據(jù)更改為其相應(yīng)的簇質(zhì)心值。這樣,我們將僅具有這些質(zhì)心值。
我不想更改原始數(shù)組,而是要制作一個(gè)副本并在那里進(jìn)行更改。
- imim_recovered = im.copy()
- for i in range(len(im)):
- im_recovered[i] = centroids[get_centroids[i]]
您還記得,我們?cè)谝婚_(kāi)始就更改了圖像的尺寸,使其成為二維數(shù)組。我們現(xiàn)在需要將其更改為原始形狀。
- im_recoveredim_recovered = im_recovered.reshape(155, 201, 3)
在這里,我將并排繪制原始圖像和縮小后的圖像,以顯示差異:
- im1 = cv2.imread('frog.png')
- import matplotlib.image as mpimg
- fig,ax = plt.subplots(1,2)
- ax[0].imshow(im1)
- ax[1].imshow(im_recovered)

> Image by Author
看,我們?nèi)绱舜蟮販p小了圖像的尺寸。不過(guò),它看起來(lái)像只青蛙!但是計(jì)算機(jī)閱讀起來(lái)會(huì)快得多!
結(jié)論
在本文中,我解釋了k均值聚類(lèi)的工作原理以及如何從頭開(kāi)始開(kāi)發(fā)k均值聚類(lèi)算法。我還解釋了如何使用此算法來(lái)縮小圖像尺寸。請(qǐng)嘗試使用其他圖像。
這是我在本文中使用的數(shù)據(jù)集的鏈接。
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/kmean.xlsx
這個(gè)是代碼:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/k_mean_clustering_final.ipynb