













聊聊圖解多線程
進程與線程
「進程」
進程的本質是一個正在執行的程序,程序運行時系統會創建一個進程,并且「給每個進程分配獨立的內存地址空間,用來保證每個進程地址不會相互干擾」。
同時,在 CPU 對進程做時間片的切換時,保證進程切換過程中仍然要從進程切換之前運行的位置處開始執行。所以進程通常還會包括程序計數器、堆棧指針。
相對好理解點的案例:電腦上開啟QQ就是開啟一個進程、打開IDEA就是開啟一個進程、打開瀏覽器就是開啟一個進程.....
當我們的電腦開啟你太多的運用(QQ,微信,瀏覽器、PDF、word、IDEA等)后,電腦就很容易出現卡頓,甚至死機,這里最主要原因就是CPU一直不停地切換導致的。
下圖是單核CPU情況下,多進程之間的切換:
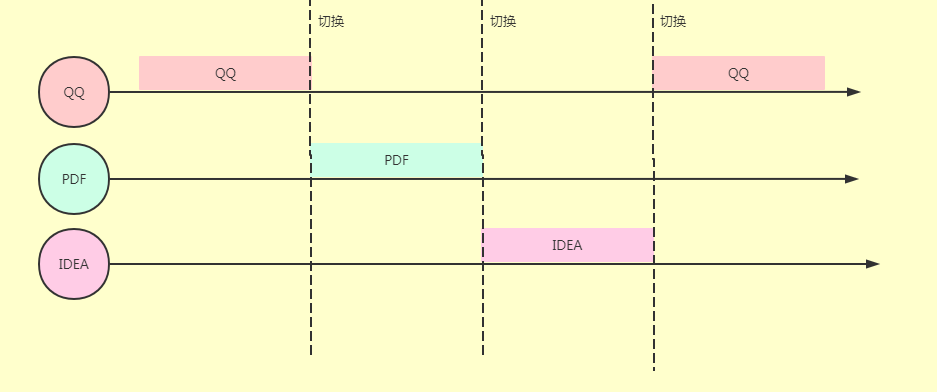
有了進程以后,可以讓操作系統從宏觀層面實現多應用并發。
而并發的實現是通過 CPU 時間片不端切換執行的,對于單核 CPU來說,在任意一個時刻只會有一個進程在被CPU 調度。
線程的生命周期
既然是生命周期,那么就很有可能會有階段性的或者狀態的,比如人的一生一樣:
精子和卵子結合---> 嬰兒---> 小孩--> 成年--> 中年--> 老年-->去世
線程狀態
關于線程的生命周期網上有不一樣的答案,有說五種也有說六種。
Java中線程確實有6種,這是有理有據的,可以看看java.lang.Thread類中有個這么一個枚舉。
- public enum State {
- NEW,
- RUNNABLE,
- BLOCKED,
- WAITING,
- TIMED_WAITING,
- TERMINATED;
- }
這就是Java線程對應的狀態,組合起來就是Java中一個線程的生命周期。下面是這個枚舉的注釋:
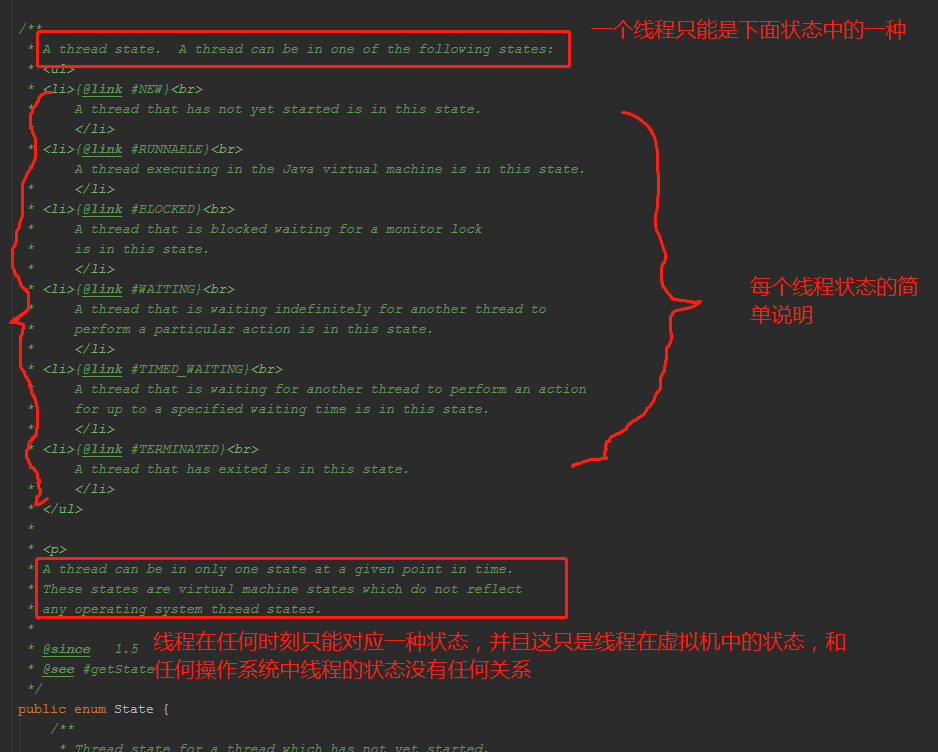
每種狀態簡單說明:
- NEW(初始):線程被創建后尚未啟動。
- RUNNABLE(運行):包括了操作系統線程狀態中的Running和Ready,也就是處于此狀態的線程可能正在運行,也可能正在等待系統資源,如等待CPU為它分配時間片。
- BLOCKED(阻塞):線程阻塞于鎖。
- WAITING(等待):線程需要等待其他線程做出一些特定動作(通知或中斷)。
- TIME_WAITING(超時等待):該狀態不同于WAITING,它可以在指定的時間內自行返回。
- TERMINATED(終止):該線程已經執行完畢。
線程生命周期
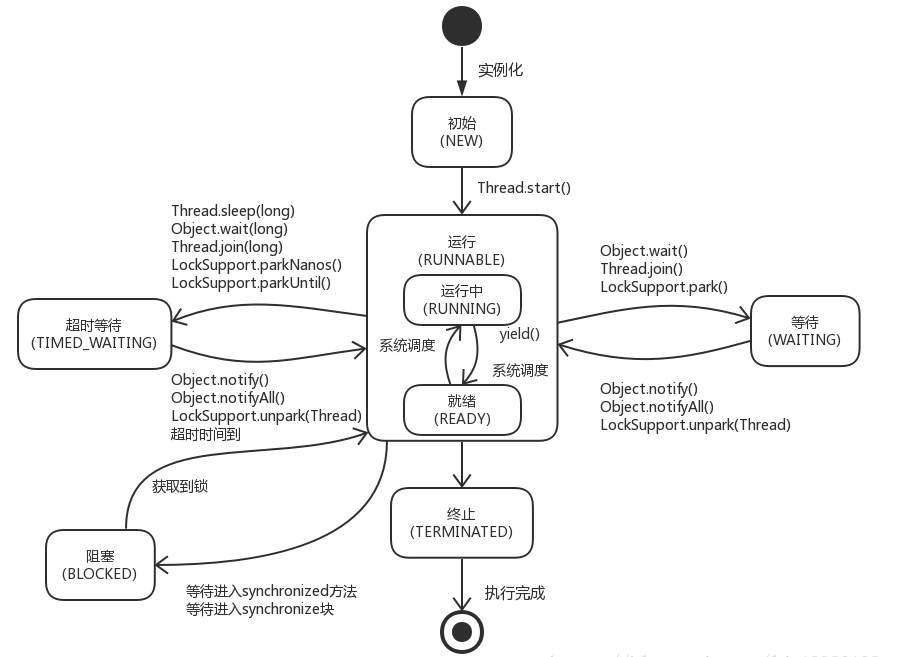
借用網上的這張圖,這張圖描述的很清楚了,這里就不在啰嗦。
何為線程安全?
我們經常會聽說某個類是線程安全,某個類不是線程安全的。那么究竟什么叫做線程安全呢?
我們引用《Java Concurrency in Practice》里面的定義:
在不使用額外同步的情況下,多個線程訪問一個對象時,不論線程之間如何交替執行或者在調用方進行任何其它的協調操作,調用這個對象的行為都能得到正確的結果,那么這個對象是線程安全的。
也可以這么理解:
多個線程訪問同一個對象時,如果不用考慮這些線程在運行時環境下的調度和交替執行,也不需要進行額外的同步,或者在調用方進行任何其他操作,調用這個對象的行為都可以獲得正確的結果,那么這個對象就是線程安全的。或者說:一個類或者程序所提供的接口對于線程來說是原子操作或者多個線程之間的切換不會導致該接口的執行結果存在二義性,也就是說我們不用考慮同步的問題。
可以簡單的理解為:“你隨便怎么調用,出了問題算我輸”。
這個定義對于類來說是十分嚴格的,即使是Java API中標為線程安全的類也很難滿足這個要求。
比如Vector是標記為線程安全的,但實際上并不能滿足這個條件,舉個例子:
- public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
- public synchronized E get(int index) {
- if (index >= elementCount)
- throw new ArrayIndexOutOfBoundsException(index);
- return elementData(index);
- }
- public synchronized void removeElementAt(int index) {
- modCount++;
- if (index >= elementCount) {
- throw new ArrayIndexOutOfBoundsException(index + " >= " +
- elementCount);
- }
- else if (index < 0) {
- throw new ArrayIndexOutOfBoundsException(index);
- }
- int j = elementCount - index - 1;
- if (j > 0) {
- System.arraycopy(elementData, index + 1, elementData, index, j);
- }
- elementCount--;
- elementData[elementCount] = null; /* to let gc do its work */
- }
- //....基本上所有方法都是synchronized修飾的
- }
來看下面一個案例:
判斷Vector中第0個元素是不是空字符,如果是空字符就將其刪除。
- package com.java.tian.blog.utils;
- import java.util.Vector;
- public class SynchronizedDemo{
- static Vector<String> vct = new Vector<String>();
- public void remove() {
- if("".equals(vct.get(0))) {
- vct.remove(0);
- }
- }
- public static void main(String[] args) {
- vct.add("");
- SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
- new Thread(new Runnable() {
- @Override
- public void run() {
- synchronizedDemo.remove();
- }
- },"線程1").start();
- new Thread(new Runnable() {
- @Override
- public void run() {
- synchronizedDemo.remove();
- }
- },"線程2").start();
- }
- }
上面的邏輯看起來沒有問題,實際上是有可能導致錯誤的:假設第0個元素是空字符,判斷的時候得到的結果是true。
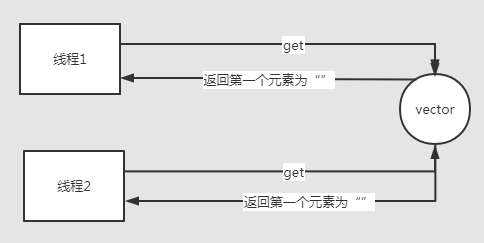
兩個線程同時執行上面的remove方法,(「極端的情況」)都「可能」get到的是"",然后都去刪除第0個元素,這個元素有可能已經被其它線程刪除了,因此Vector不是絕對線程安全的。(上面這個案例只是做演示而已,在你的業務代碼里面這么寫的話,線程安全真的就不能靠Vector來保證了)。
通常情況下我們說的線程安全都是相對線程安全,相對線程安全只要求調用單個方法的時候不需要同步就可以得到正確的結果,但數多個方法組合調用的時候也是有可能導致多線程問題的。
如果想讓上面的操作執行正確,我們需要在調用Vector方法的時候添加額外的同步操作:
- package com.java.tian.blog.utils;
- import java.util.Vector;
- public class SynchronizedDemo {
- static Vector<String> vct = new Vector<String>();
- public void remove() {
- synchronized (vct) {
- //synchronized (SynchronizedDemo.class) {
- if ("".equals(vct.get(0))) {
- vct.remove(0);
- }
- }
- }
- public static void main(String[] args) {
- vct.add("");
- SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
- new Thread(new Runnable() {
- @Override
- public void run() {
- synchronizedDemo.remove();
- }
- }, "線程1").start();
- new Thread(new Runnable() {
- @Override
- public void run() {
- synchronizedDemo.remove();
- }
- }, "線程2").start();
- }
- }
根據Vector的源代碼可知:Vector的每個方法都使用了synchronized關鍵字修飾,因此鎖對象就是這個對象本身。在上面的代碼中我們嘗試獲取的也是vct對象的鎖,可以和vct對象的其它方法互斥,因此這樣做可以保證得到正確的結果。
如果Vector內部使用的是其它鎖同步的,并封裝了鎖對象,那么我們無論如何都無法正確執行這個“先判斷后修改”的操作。
假設被封裝的對象鎖為obj,get()和remove()方法對應的鎖都是obj,而整個操作過程獲取的是vct的鎖,一個線程調用get()方法成功后就釋放了obj的鎖,這時這個線程只持有vct的鎖,而其它線程可以獲得obj的鎖并搶先一步刪除了第0個元素。
Java為開發者提供了很多強大的工具類,這些工具類里面有的是線程安全的,有的不是線程安全的。在這里我們列舉幾個面試常考的:
線程安全的類:Vector、Hashtable、StringBuffer
非線程安全的類:ArrayList、HashMap、StringBuilder
有人可能會反問:為什么Java不把所有的類都設計成線程安全的呢?這樣對于我們開發者來說豈不是更爽嗎?我們就不用考慮什么線程安全問題了。
事情都是具有兩面性的,獲得線程安全但是性能會有所下降,畢竟鎖的開銷是擺在那里的。線程不安全但是性能會有所提升,具體場景還得看業務更偏向于哪一個。
一個問題引發的思考:
- public class SynchronizedDemo {
- static int count;
- public void incre() {
- try {
- //每個線程都睡一會,模仿業務代碼
- Thread.sleep(100 );
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- count++;
- }
- public static void main(String[] args) {
- SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
- for (int i = 0; i < 1000; i++) {
- new Thread(new Runnable() {
- @Override
- public void run() {
- synchronizedDemo.incre();
- }
- }).start();
- }
- try {
- //讓主線程等待所有線程執行完畢
- Thread.sleep(2000L);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(count);
- }
- }
上面這段代碼輸出的結果是不確定的,結果是小于等于1000。
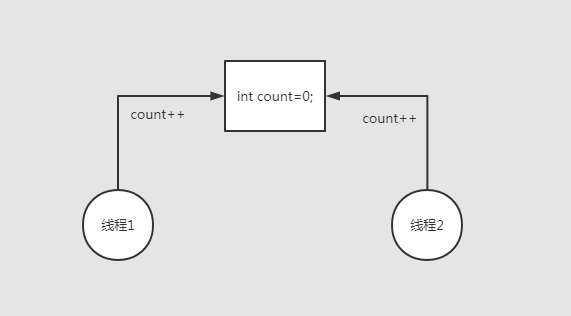
1000線程都去對count進行++操作。
對象內存布局
對象在內存中的存儲可以分為 3 塊區域,分別是對象頭、實例數據和對齊填充。
其中,對象頭包括兩部分內容,一部分是對象本身的運行時數據,像 GC 分代年齡、哈希碼、鎖狀態標識等等,官方稱之為“Mark Word”,如果忽略壓縮指針的影響,這部分數據在 32 位和 64 位的虛擬機中分別占 32 位和 64 位。
但是對象需要存儲的運行時數據很多,32 位或者 64 位都不一定能存的下,考慮到虛擬機的空間效率,這個 Mark Word 被設計成一個非固定的數據結構,它會根據對象的狀態復用自己的存儲空間,對象處于不同狀態的時候,對應的 bit 表示的含義可能會不一樣,見下圖,以 32 位 Hot Spot 虛擬機為例:
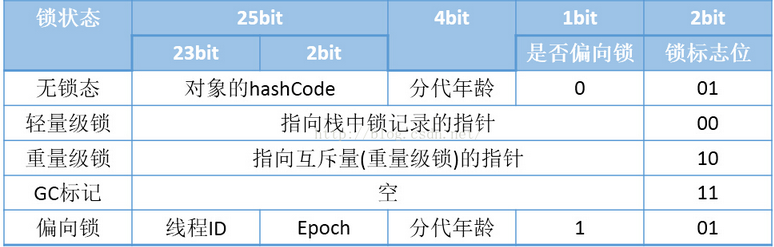
從上圖中我們可以看出,如果對象處于未鎖定狀態(無鎖態),那么 Mark Word 的 25 位用于存儲對象的哈希碼,4 位用于存儲對象分代年齡,1 位固定為 0,兩位用于存儲鎖標志位。
這個圖對于理解后面提到的輕量級鎖、偏向鎖是非常重要的,當然我們現在可以先著重考慮對象處于重量級鎖狀態下的情況,也就是鎖標志位為 10。同時我們看到,無鎖態和偏向鎖狀態下,2 位鎖標志位都是“01”,留有 1 位表示是否可偏向,我們姑且叫它“偏向位”。
「注」:對象頭的另一部分則是類型指針,虛擬機可以通過這個指針來確認該對象是哪個類的實例。但是我們要注意,并不是所有的虛擬機都必須以這種方式來確定對象的元數據信息。對象的訪問定位一般有句柄和直接指針兩種,如果使用句柄的話,那么對象的元數據信息可以直接包含在句柄中(當然也包括對象實例數據的地址信息),也就沒必要將這些元數據和實例數據存儲在一起了。至于實例數據和對齊填充,這里暫不做討論。
前面我們提到了,Java 中的每個對象都與一個 monitor 相關聯,當鎖標志位為 10 時,除了 2bit 的標志位,指向的就是 monitor 對象的地址(還是以 32 位虛擬機為例)。這里我們可以翻閱一下 OpenJDK 的源碼,如果我們需要下載openJDK的源碼:
找到。這里先看一下markOpp.hpp文件。該文件的相對路徑為:
- openjdk\hotspot\src\share\vm\oops
下圖是文件中的注釋部分:
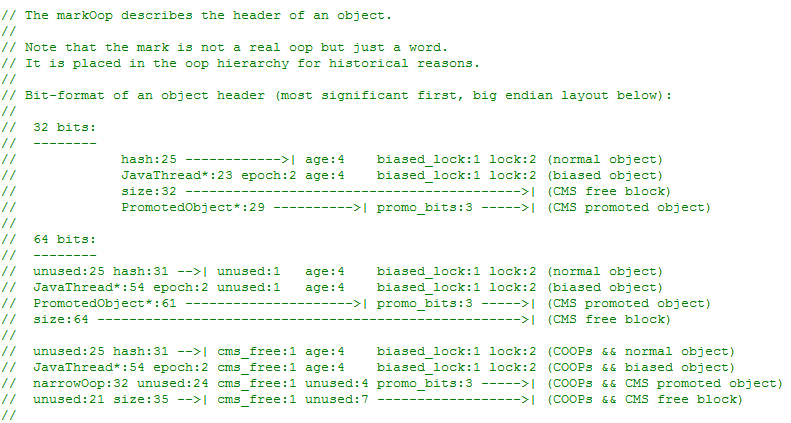
我們可以看到,其中描述了 32 位和 64 位下 Mark World 的存儲狀態。也可以看到64位下,前25位是沒有使用的。

我們也可以看到 markOop.hpp 中定義的鎖狀態枚舉,對應我們前面提到的無鎖、偏向鎖、輕量級鎖、重量級鎖(膨脹鎖)、GC 標記等:
- enum { locked_value = 0,//00 輕量級鎖
- unlocked_value = 1,//01 無鎖
- monitor_value = 2,//10 重量級鎖
- marked_value = 3,//11 GC標記
- biased_lock_pattern = 5 //101 偏向鎖,1位偏向標記和2位狀態標記(01)
- };
從注釋中,我們也可以看到對其的簡要描述,后面會我們詳細解釋:

這里我們的重心還是是重量級鎖,所以我們看看源碼中 monitor 對象是如何定義的,對應的頭文件是 objectMonitor.hpp,文件路徑為:
- openjdk\hotspot\src\share\vm\runtime
我們來簡單看一下這個 objectMonitor.hpp 的定義:
- // initialize the monitor, exception the semaphore, all other fields
- // are simple integers or pointers
- ObjectMonitor() {
- _header = NULL;
- _count = 0;
- _waiters = 0,//等待線程數
- _recursions = 0;//重入次數
- _object = NULL;
- _owner = NULL;//持有鎖的線程(邏輯上,實際上除了THREAD,還可能是Lock Record)
- _WaitSet = NULL;//線程wait之后會進入該列表
- _WaitSetLock = 0 ;
- _Responsible = NULL ;
- _succ = NULL ;
- _cxq = NULL ;//等待獲取鎖的線程列表,和_EntryList配合使用
- FreeNext = NULL ;
- _EntryList = NULL ;//等待獲取鎖的線程列表,和_cxq配合使用
- _SpinFreq = 0 ;
- _SpinClock = 0 ;
- OwnerIsThread = 0 ;//當前持有者是否為THREAD類型,如果是輕量級鎖膨脹而來,還沒有enter的話,
- //_owner存儲的可能會是Lock Record
- _previous_owner_tid = 0;
- }
簡單的說,當多個線程競爭訪問同一段同步代碼塊時,如果線程獲取到了 monitor,那么就會把 _owner 設置成當前線程,如果是重入的話,_recursions 會加 1,如果獲取 monitor 失敗,則會進入 _cxq隊列。
鎖被釋放時,_cxq中的線程會被移動到 _EntryList中,并且喚醒_EntryList 隊首線程。當然,選取喚醒線程有幾個不同的策略(Knob_QMode),還是后面結合源碼解析。
「注」:_cxq和 _EntryList本質上是ObjectWaiter 類型,它本質上其實是一個雙向鏈表 (具有前后指針),只是在使用的時候不一定要當做雙向鏈表使用,比如 _cxq 是當做單向鏈表使用的,_EntryList是當做雙向鏈表使用的。
什么場景會導致線程的上下文切換?
導致線程上下文切換的有兩種類型:
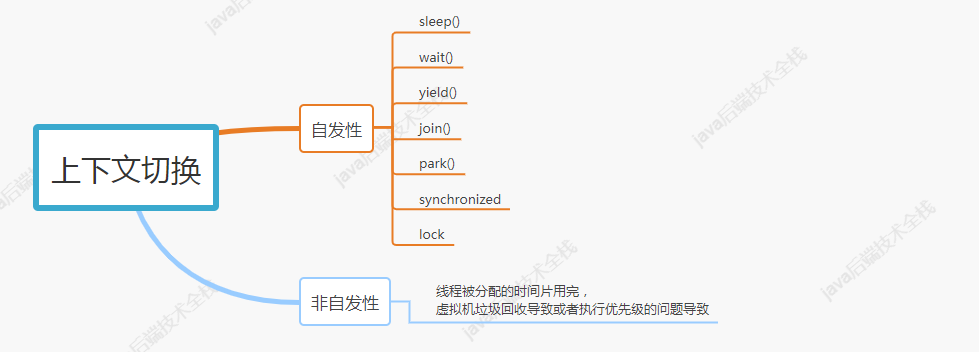
自發性上下文切換是指線程由 Java 程序調用導致切出,在多線程編程中,執行調用上圖中的方法或關鍵字,常常就會引發自發性上下文切換。
非自發性上下文切換指線程由于調度器的原因被迫切出。常見的有:線程被分配的時間片用完,虛擬機垃圾回收導致或者執行優先級的問題導致。
waity /notify
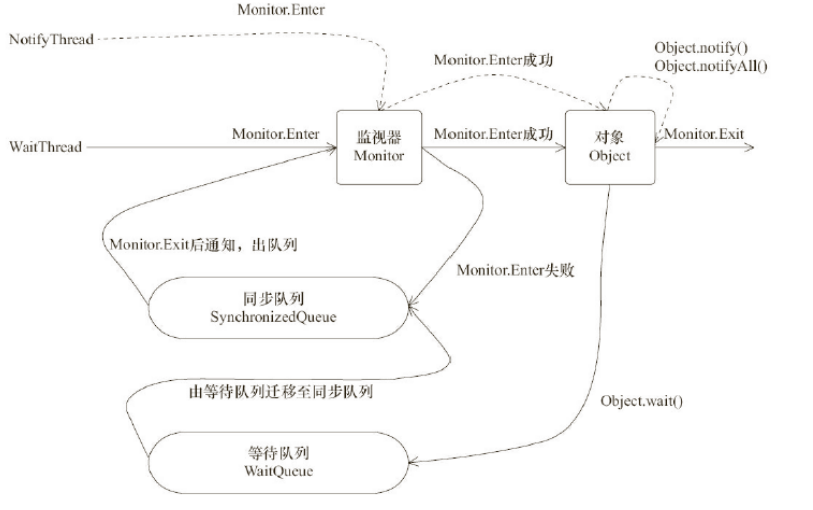
注意兩個隊列:
等待隊列:notifyAll/notify喚醒的就是等待隊列中的線程;
同步線程:就是競爭鎖的所有線程,等待隊列中的線程被喚醒后進入同步隊列。
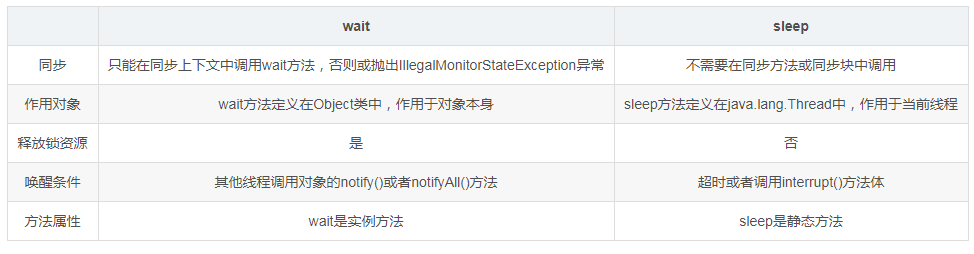
sleep與wait的區別
sleep
- 讓當前線程休眠指定時間。
- 休眠時間的準確性依賴于系統時鐘和CPU調度機制。
- 不釋放已獲取的鎖資源,如果sleep方法在同步上下文中調用,那么其他線程是無法進入到當前同步塊或者同步方法中的。
- 可通過調用interrupt()方法來喚醒休眠線程。
- sleep是Thread里的方法
wait
- 讓當前線程進入等待狀態,當別的其他線程調用notify()或者notifyAll()方法時,當前線程進入就緒狀態
- wait方法必須在同步上下文中調用,例如:同步方法塊或者同步方法中,這也就意味著如果你想要調用wait方法,前提是必須獲取對象上的鎖資源
- 當wait方法調用時,當前線程將會釋放已獲取的對象鎖資源,并進入等待隊列,其他線程就可以嘗試獲取對象上的鎖資源。
- wait是Object中的方法
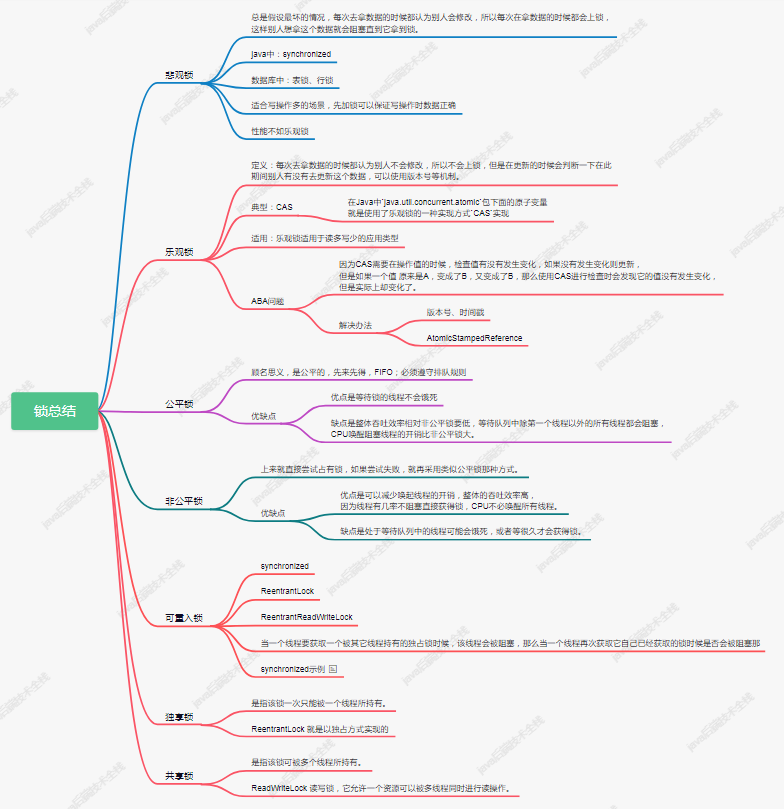
樂觀鎖、悲觀鎖、可重入鎖.....
作為一個Java開發多年的人來說,肯定多多少少熟悉一些鎖,或者聽過一些鎖。今天就來做一個鎖相關總結。
悲觀鎖和樂觀鎖
悲觀鎖
顧名思義,他就是很悲觀,把事情都想的最壞,是指該鎖只能被一個線程鎖持有,如果A線程獲取到鎖了,這時候線程B想獲取鎖只能排隊等待線程A釋放。
在數據庫中這樣操作:
- select user_name,user_pwd from t_user for update;
樂觀鎖
顧名思義,樂觀,人樂觀就是什么是都想得開,船到橋頭自然直。樂觀鎖就是我都覺得他們都沒有拿到鎖,只有我拿到鎖了,最后再去問問這個鎖真的是我獲取的嗎?是就把事情給干了。
典型的代表:CAS=Compare and Swap 先比較哈,資源是不是我之前看到的那個,是那我就把他換成我的。不是就算了。
在Java中java.util.concurrent.atomic包下面的原子變量就是使用了樂觀鎖的一種實現方式CAS實現。
通常都是 使用version、時間戳等來比較是否已被其他線程修改過。
使用悲觀鎖還是使用樂觀鎖?
在樂觀鎖與悲觀鎖的選擇上面,主要看下兩者的區別以及適用場景就可以了。
「響應效率」
如果需要非常高的響應速度,建議采用樂觀鎖方案,成功就執行,不成功就失敗,不需要等待其他并發去釋放鎖。樂觀鎖并未真正加鎖,效率高。一旦鎖的粒度掌握不好,更新失敗的概率就會比較高,容易發生業務失敗。
「沖突頻率」
如果沖突頻率非常高,建議采用悲觀鎖,保證成功率。沖突頻率大,選擇樂觀鎖會需要多次重試才能成功,代價比較大。「重試代價」
如果重試代價大,建議采用悲觀鎖。悲觀鎖依賴數據庫鎖,效率低。更新失敗的概率比較低。
樂觀鎖如果有人在你之前更新了,你的更新應當是被拒絕的,可以讓用戶從新操作。悲觀鎖則會等待前一個更新完成。這也是區別。
公平鎖和非公平鎖
公平鎖
顧名思義,是公平的,先來先得,FIFO;必須遵守排隊規則。不能僭越。多個線程按照申請鎖的順序去獲得鎖,線程會直接進入隊列去排隊,永遠都是隊列的第一位才能得到鎖。
在ReentrantLock中默認使用的非公平鎖,但是可以在構建ReentrantLock實例時候指定為公平鎖。
- ReentrantLock fairSyncLock = new ReentrantLock(true);
假設線程 A 已經持有了鎖,這時候線程 B 請求該鎖將會被掛起,當線程 A 釋放鎖后,假如當前有線程 C 也需要獲取該鎖,那么在公平鎖模式下,獲取鎖和釋放鎖的步驟為:
- 線程A獲取鎖--->線程A釋放鎖
- 線程B獲取鎖--->線程B釋放鎖;
- 線程C獲取鎖--->線程釋放鎖;
「優點」
所有的線程都能得到資源,不會餓死在隊列中。
「缺點」
吞吐量會下降很多,隊列里面除了第一個線程,其他的線程都會阻塞,CPU喚醒阻塞線程的開銷會很大。
非公平鎖
顧名思義,老子才不管你們誰先排隊的,也就是平時大家在生活中很討厭的。生活中排隊的很多,上車排隊、坐電梯排隊、超市結賬付款排隊等等。但是不是每個人都會遵守規則站著排隊,這就對站著排隊的人來說就不公平了。等搶不到后再去乖乖排隊。
多個線程去獲取鎖的時候,會直接去嘗試獲取,獲取不到,再去進入等待隊列,如果能獲取到,就直接獲取到鎖。
上面說過在ReentrantLock中默認使用的非公平鎖,兩種方式:
- ReentrantLock fairSyncLock = new ReentrantLock(false);
或者:
- ReentrantLock fairSyncLock = new ReentrantLock();
都可以實現非公平鎖。
「優點」
可以減少CPU喚醒線程的開銷,整體的吞吐效率會高點,CPU也不必取喚醒所有線程,會減少喚起線程的數量。
「缺點」
大家可能也發現了,這樣可能導致隊列中間的線程一直獲取不到鎖或者長時間獲取不到鎖,導致餓死。
獨享鎖和共享鎖
獨享鎖
獨享鎖也叫排他鎖/互斥鎖,是指該鎖一次只能被一個線程鎖持有。如果線程T對數據A加上排他鎖后,則其他線程不能再對A加任何類型的鎖。獲得排他鎖的線程既能讀數據又能修改數據。JDK中的synchronized和JUC中Lock的實現類就是互斥鎖。
共享鎖
共享鎖是指該鎖可被多個線程所持有。如果線程T對數據A加上共享鎖后,則其他線程只能對A再加共享鎖,不能加排他鎖。獲得共享鎖的線程只能讀數據,不能修改數據。
對于ReentrantLock而言,其是獨享鎖。但是對于Lock的另一個實現類ReadWriteLock,其讀鎖是共享鎖,其寫鎖是獨享鎖。
- 讀鎖的共享鎖可保證并發讀是非常高效的,讀寫,寫讀 ,寫寫的過程是互斥的。
- 獨享鎖與共享鎖也是通過AQS來實現的,通過實現不同的方法,來實現獨享或者共享。
可重入鎖
若當前線程執行中已經獲取了鎖,如果再次獲取該鎖時,就會獲取不到被阻塞。
- public class RentrantLockDemo {
- public synchronized void test(){
- System.out.println("test");
- }
- public synchronized void test1(){
- System.out.println("test1");
- test();
- }
- public static void main(String[] args) {
- RentrantLockDemo rentrantLockDemo = new RentrantLockDemo();
- //線程1
- new Thread(() -> rentrantLockDemo.test1()).start();
- }
- }
當一個線程執行test1()方法的時候,需要獲取rentrantLockDemo的對象鎖,在test1方法匯總又會調用test方法,但是test()的調用是需要獲取對象鎖的。
可重入鎖也叫「遞歸鎖」,指的是同一線程外層函數獲得鎖之后,內層遞歸函數仍然有獲取該鎖的代碼,但不受影響。
ThreadLocal設計原理
ThreadLocal名字中有個Thread表示線程,Local表示本地,我們就理解為線程本地變量了。
先看看ThreadLocal的整體:
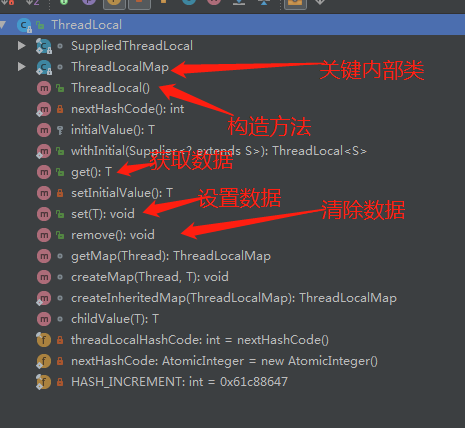
最關心的三個公有方法:set、get、remove。
構造方法
- public ThreadLocal() {
- }
構造方法里沒有任何邏輯處理,就是簡單的創建一個實例。
set方法
源碼為:
- public void set(T value) {
- //獲取當前線程
- Thread t = Thread.currentThread();
- //這是什么鬼?
- ThreadLocalMap map = getMap(t);
- if (map != null)
- map.set(this, value);
- else
- createMap(t, value);
- }
先看看ThreadLocalMap是個什么東東:
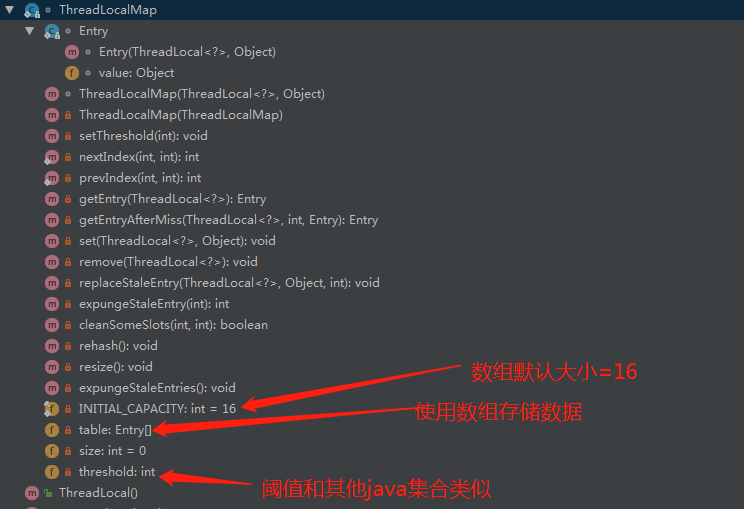
ThreadLocalMap是ThreadLocal的靜態內部類。
set方法整體為:


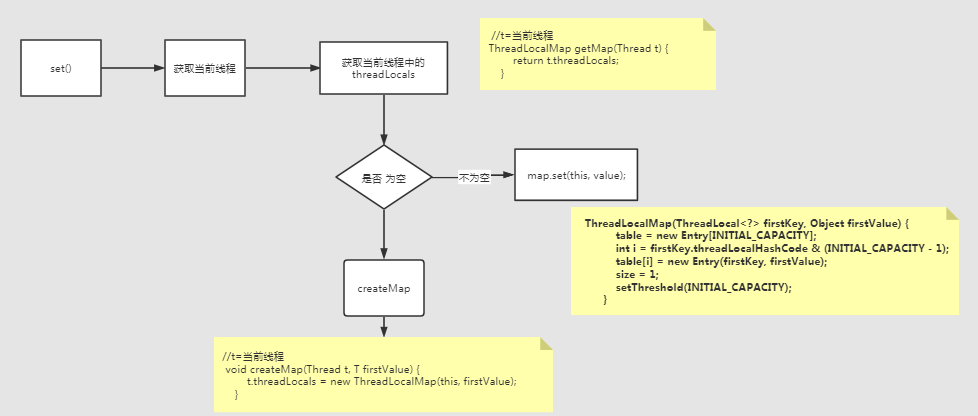
ThreadLocalMap構造方法:
- //這個屬性是ThreadLocal的,就是獲取hashcode(這列很有學問,但是我們的目的不是他)
- private final int threadLocalHashCode = nextHashCode();
- private Entry[] table;
- private static final int INITIAL_CAPACITY = 16;
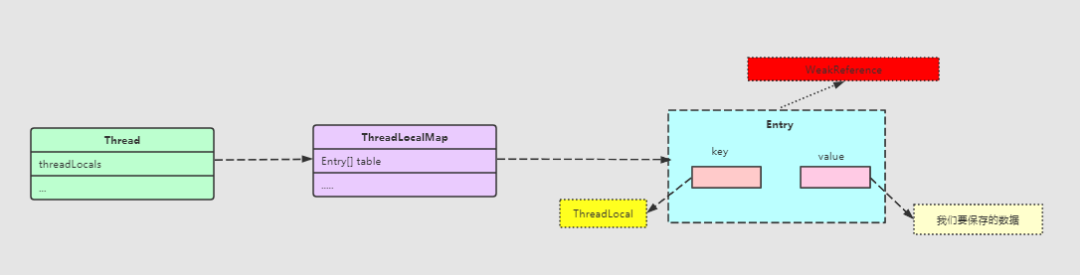
- //Entry是一個弱引用
- static class Entry extends WeakReference<ThreadLocal<?>> {
- Object value;
- Entry(ThreadLocal<?> k, Object v) {
- super(k);
- value = v;
- }
- }
- ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
- //數組默認大小為16
- table = new Entry[INITIAL_CAPACITY];
- //len 為2的n次方,以ThreadLocal的計算的哈希值按照Entry[]取模(為了更好的散列)
- int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
- table[i] = new Entry(firstKey, firstValue);
- size = 1;
- //設置閾值(擴容閾值)
- setThreshold(INITIAL_CAPACITY);
- }
然后我們看看map.set()方法中是如何處理的:
- private void set(ThreadLocal<?> key, Object value) {
- Entry[] tab = table;
- int len = tab.length;
- //len 為2的n次方,以ThreadLocal的計算的哈希值按照Entry[]取模
- int i = key.threadLocalHashCode & (len-1);
- //找到ThreadLocal對應的存儲的下標,如果當前槽內Entry不為空,
- //即當前線程已經有ThreadLocal已經使用過Entry[i]
- for (Entry e = tab[i];
- e != null;
- e = tab[i = nextIndex(i, len)]) {
- ThreadLocal<?> k = e.get();
- // 當前占據該槽的就是當前的ThreadLocal ,更新value結束
- if (k == key) {
- e.value = value;
- return;
- }
- //當前卡槽的弱引用可能會回收了,key:null value:xxxObject ,
- //需清理Entry原來的value ,便于垃圾回收value,且將新的value 放在該槽里,結束
- if (k == null) {
- replaceStaleEntry(key, value, i);
- return;
- }
- }
- //在這之前沒有ThreadLocal使用Entry[i],并進行值存儲
- tab[i] = new Entry(key, value);
- //累計Entry所占的個數
- int sz = ++size;
- // 清理key 為null 的Entry ,可能需要擴容,擴容長度為原來的2倍,并需要進行重新hash
- if (!cleanSomeSlots(i, sz) && sz >= threshold){
- rehash();
- }
從上面這個set方法,我們就大致可以把這三個進行一個關聯了:
Thread、ThreadLocal、ThreadLocalMap。
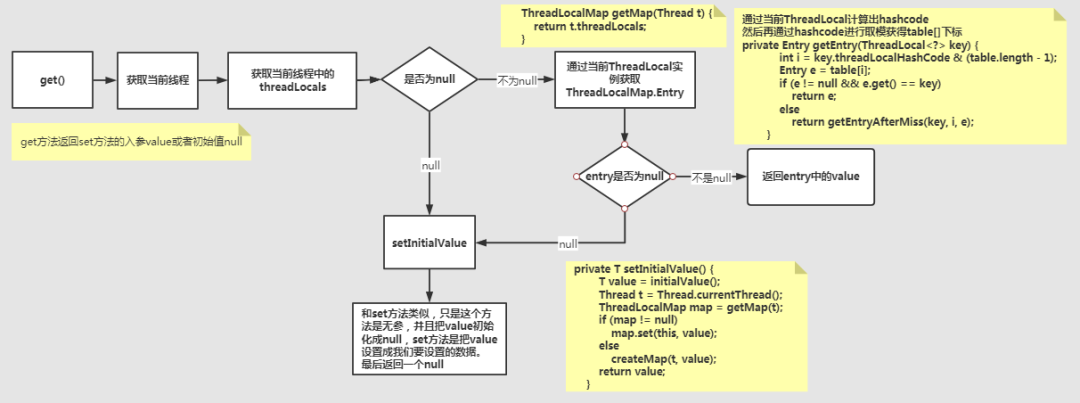
get方法

remove方法
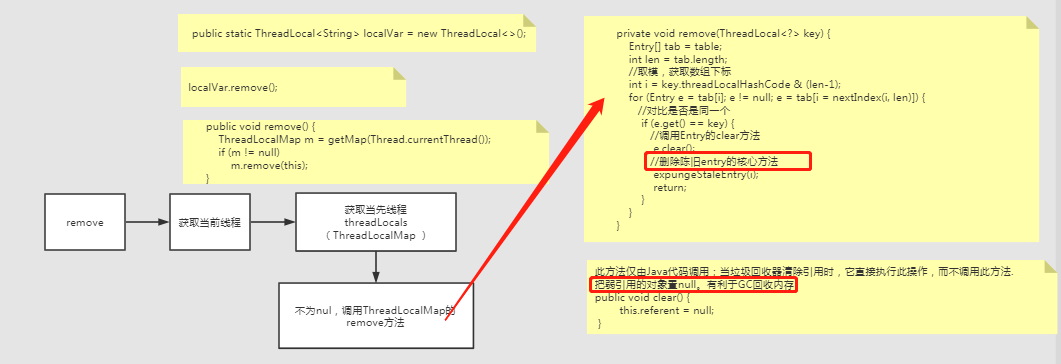
expungeStaleEntry方法代碼里有點大,所以這里就貼了出來。
- //刪除陳舊entry的核心方法
- private int expungeStaleEntry(int staleSlot) {
- Entry[] tab = table;
- int len = tab.length;
- tab[staleSlot].value = null;//刪除value
- tab[staleSlot] = null;//刪除entry
- size--;//map的size自減
- // 遍歷指定刪除節點,所有后續節點
- Entry e;
- int i;
- for (i = nextIndex(staleSlot, len);
- (e = tab[i]) != null;
- i = nextIndex(i, len)) {
- ThreadLocal<?> k = e.get();
- if (k == null) {//key為null,執行刪除操作
- e.value = null;
- tab[i] = null;
- size--;
- } else {//key不為null,重新計算下標
- int h = k.threadLocalHashCode & (len - 1);
- if (h != i) {//如果不在同一個位置
- tab[i] = null;//把老位置的entry置null(刪除)
- // 從h開始往后遍歷,一直到找到空為止,插入
- while (tab[h] != null){
- h = nextIndex(h, len);
- }
- tab[h] = e;
- }
- }
- }
- return i;
- }
本文轉載自微信公眾號「Java后端技術全棧」,可以通過以下二維碼關注。轉載本文請聯系Java后端技術全棧公眾號。






















