













為Web開發人員準備的七項數據庫優化技巧
譯文【51CTO.com快譯】通常,諸如MySQL等時下流行的數據庫管理系統(DBMS),都是由Web托管方(如云服務平臺)提供的。這些數據庫往往被設置成為默認、或通用的運行模式,且不一定適合用戶系統的真實運行環境。為此,我們有必要對其進行適當的優化。
不過,一提到數據庫優化,您也許會馬上想到更高的查詢效率、更高的整體性能等方面。其實,優化的好處遠不至于此。在具體實現方法上,數據庫管理人員往往也需要與Web開發團隊通力合作,根據目標系統的實際情況,更改相應的配置策略和規則。本文將為Web開發人員列出七項數據庫優化的常見技巧,以方便參考與實踐。
1.刪除未使用的表
通常,當您在應用中刪除或停用了某個插件后,與之對應的數據庫表并未隨之自動消除。而且,它們會保留全量的用戶信息、默認選項、以及其他數據。這些被遺留下來的數據集,不但是系統受到各種攻擊的安全隱患,而且很可能會拖慢服務器與系統的整體性能。
如果您使用的是WordPress,那么可以通過安裝一個名為“插件垃圾收集器”(Plugins Garbage Collector)的插件,來掃描并發現目標數據庫中任何未在使用的數據表,以供您選擇并刪除它們。
當然,如果您更喜歡命令行操作的話,則可以使用如下圖所示的UPDATE_TIME字符串,直接查找那些非活躍的數據表。

StackOverflow中的UPDATE_TIME字符串示例。來源:StackOverflow。
不過,某些插件在訪問數據集后,可能無法更新目標數據表,因此您需要在刪除數據庫表之前,再三確認它們是否的確不再被使用、或沒有被某處所調用到。而且作為一項預防性的辦法,在做任何修改之前,您最好事先手動創建目標數據庫的一個備份。當然,托管類型的云端服務通常都會提供針對服務器的自動化備份,您只需事先了解如何從中進行恢復便可。
2. 創建一個執行計劃
執行計劃(execution plan)的主要功能是:展示出在創建和執行某個查詢時,所涉及到的各種檢索數據的方法,其中包含:它查詢了哪些表,先查詢的是哪張表,后查詢的又是哪張表,是否使用了索引,以及查詢是否高效等信息。因此,典型的執行計劃包括以下方面:
- 操作的類型
- 操作的排序
- 可使用的索引
- 通過統計來估算行數
- 通過結果來估算行數
下圖是一個ApexSQL執行計劃的圖形化示例:
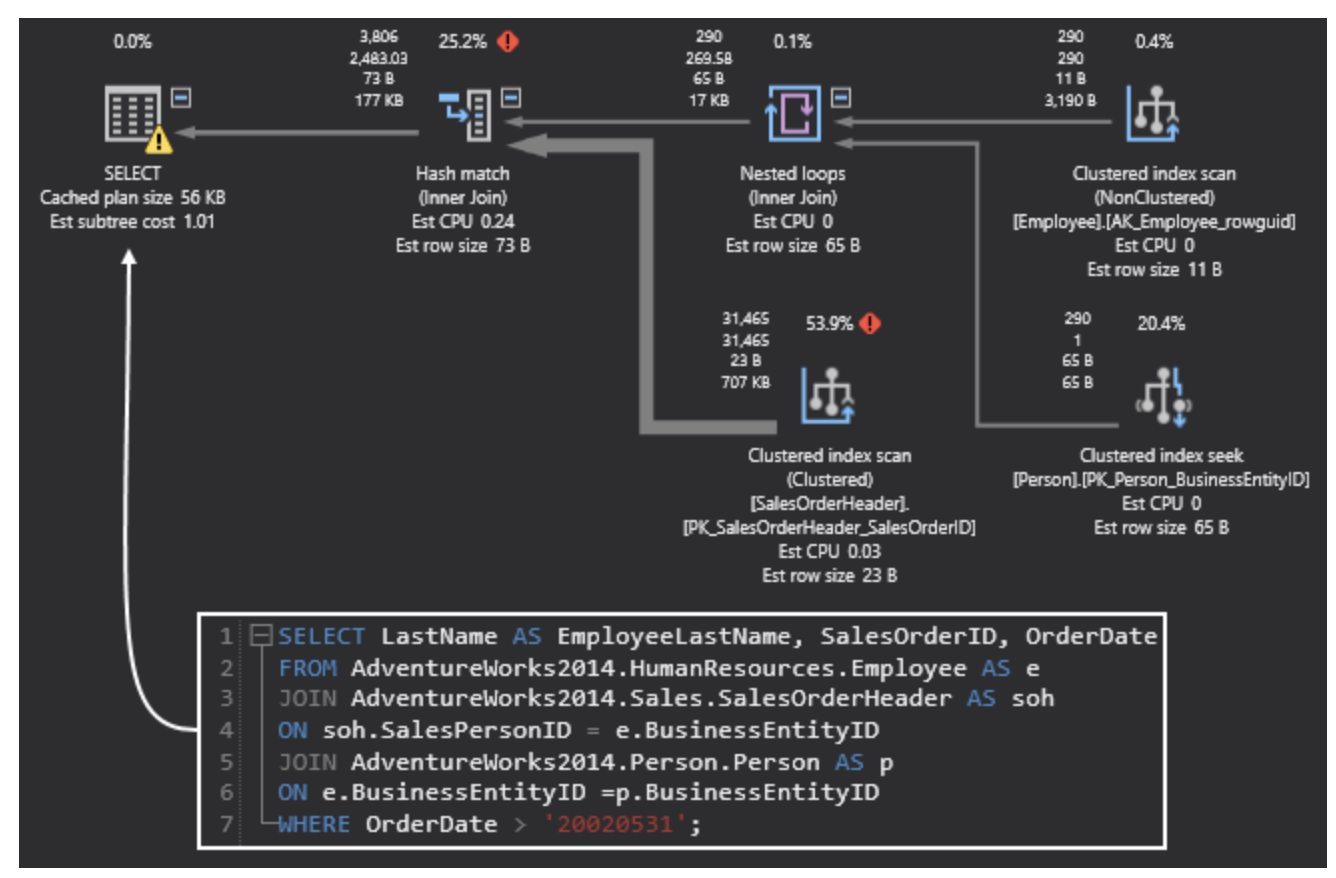
ApexSQL的執行計劃示例。來源:ApexSQL。
可見,只有當您獲得一個適當的執行計劃,才能構建出實用的索引,進一步優化目標數據庫,同時也為后續的優化打下基礎。
3. 適當的索引
從概念上說,索引能夠允許您更快地訪問數據庫,并加速查詢。相反,如果您未能合理地使用索引,那么查詢的處理過程就會變得緩慢。當然,過分地索引(over-indexing)數據庫,是不會給系統帶來任何好處的。
目前,Web開發人員經常使用兩種類型的數據庫索引:聚合(clustered index)和非聚合索引(non-clustered index)。

來源:DataSchool。
聚合方式使用主鍵來組織表中的數據。也就是說,在主鍵被定義后,索引將會被自動地創建出來。

定義主鍵。來源:DataSchool。
非聚合索引的主要目的是:通過創建能夠更易于搜索的列,進而加快查詢的效率。

創建索引。來源:DataSchool。
4. 避免通過索引訪問臨時表
根據MySQL的官方文檔,創建臨時表的一個條件是:對語句中包含的ORDER BY子句和不同的GROUP BY子句進行評估。然而,您可以通過使用“索引訪問(index access)”,避免使用ORDER BY子句來創建臨時表。使用這種索引的一個先決條件是:所有GROUP BY列都必須從相同的索引處引用不同的屬性。而且,該索引必須按照順序存儲它們的鍵。
目前,我們可以在MySQL中使用兩種類型的索引訪問:松索引掃描(Loose Index Scan )和緊索引掃描(Tight Index Scan)。其中,松索引掃描只考慮索引鍵的一小部分,而并不能滿足查詢中的每一個WHERE條件。如果WHERE子句中包含了范圍謂詞,那么松索引掃描會首先在每一組中,查找滿足范圍條件的第一個鍵,然后再去讀取最小數量的鍵。
當然,一些為數據表預定的條件可以直接使用松索引掃描。當松索引掃描適合某個查詢時,EXPLAIN的輸出會展示那些在額外列(Extra column)中,為group-by使用的索引。
下面的查詢示例就是使用了松索引掃描訪問:

查詢列表示例:在表t1 (c1,c2,c3,c4)上的idx (c1,c2,c3)。來源:MySQL。
如果目標數據表的條件不支持使用松索引掃描,您可以選用緊索引掃描方式。當然,根據實際查詢的需求,您也可以在此基礎上,選用完整的、或一定范圍的緊索引掃描。
此類索引訪問的基礎是:當一定范圍條件的所有鍵被發現后,數據庫將不會針對GROUP BY子句,生成一個臨時的數據表,來滿足該查詢。
如下查詢示例雖然不適合使用松索引掃描,但是我們可以采用緊索引掃描的方式:

查詢列表示例:在表t1 (c1,c2,c3,c4)上的idx (c1,c2,c3)。來源:MySQL。
5. 避免編碼循環
一個SQL查詢如果需要被運行多次,那么該系統不但低效,而且可能會導致不必要的性能問題。而對于大型數據集而言,此類問題會迅速積累,讓系統最終不堪重負。目前,業界有多種不錯的解決方案。從本質上說,這些方法都會要將查詢移出循環,以確保只執行一次。
如下示例展示了,如何使用JOIN和GROUP BY從多個表中選擇數據,并使數據庫通過單個查詢來執行計數。此方法對于多個查詢(包括COUNT和MAX子句)來說,特別有效。
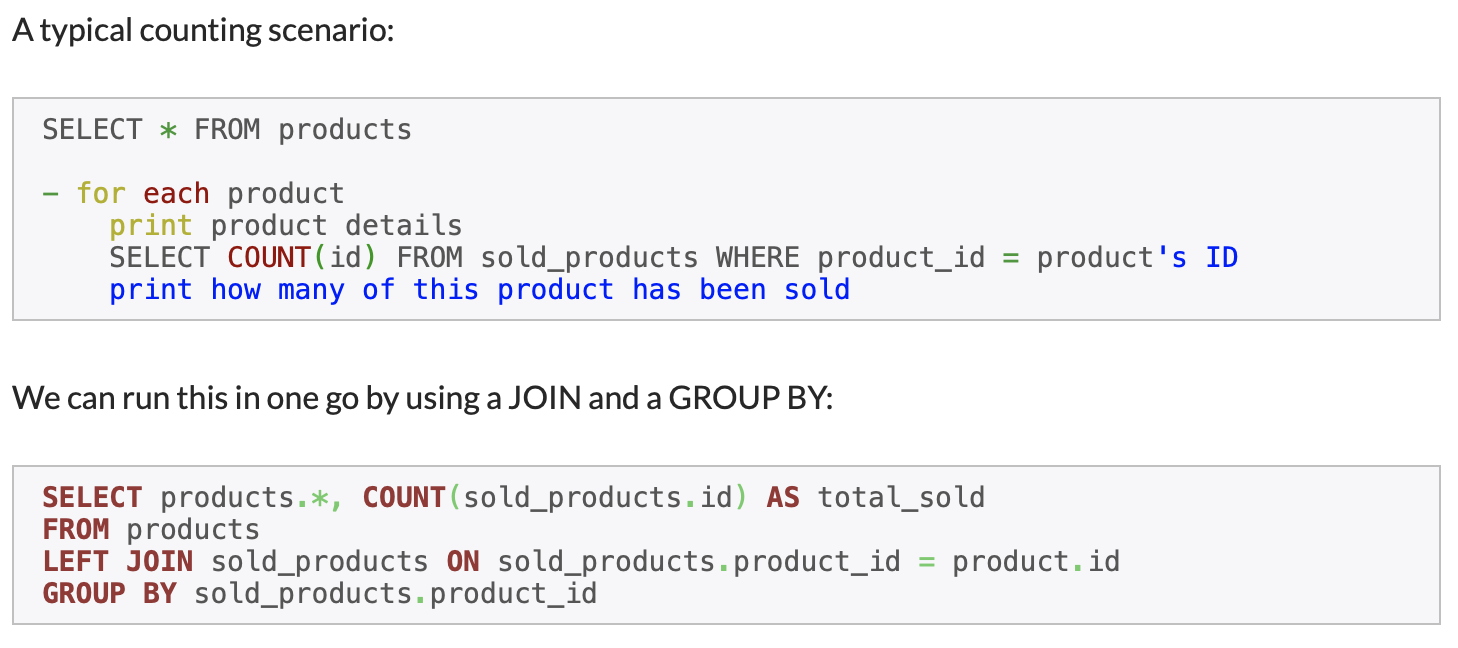
使用Join和Group By。來源:CodeUtopia。
當然,您還可以采用子選擇,即:在SELECT子句中嵌套使用SELECT子句。由于此類查詢的執行過程需要較少的資源,因此它對于合并查詢非常實用。
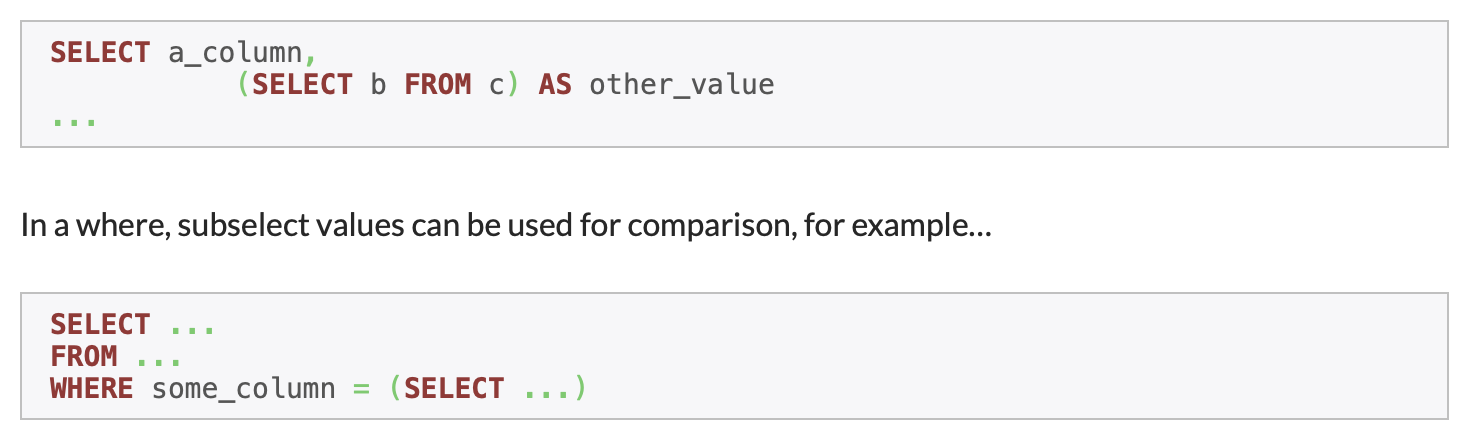
子選擇的示例。來源:CodeUtopia。
6. 擺脫相關子查詢
從本質上說,相關子查詢(Correlated subqueries)就是一種編碼循環。也就是說,子查詢通過逐行運行,直至滿足父語句為止。當輸出主要依賴于多部分的答案驗證(multi-part answer validation)時,該處理方法十分有效。
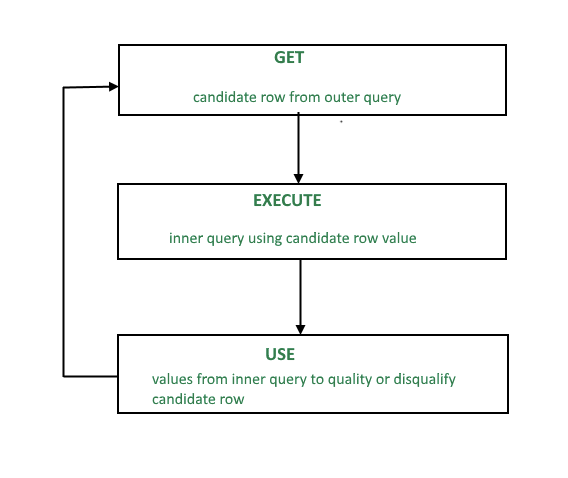
關聯子查詢流程圖。來源:GeeksforGeeks。
您可以通過使用JOIN子句來避免相關子查詢,進而提高查詢的運行效率。實際上,該方法替換了WHERE,并消除了前端請求分別為每一行執行子查詢的必要性。下圖展示了該方法的工作過程:
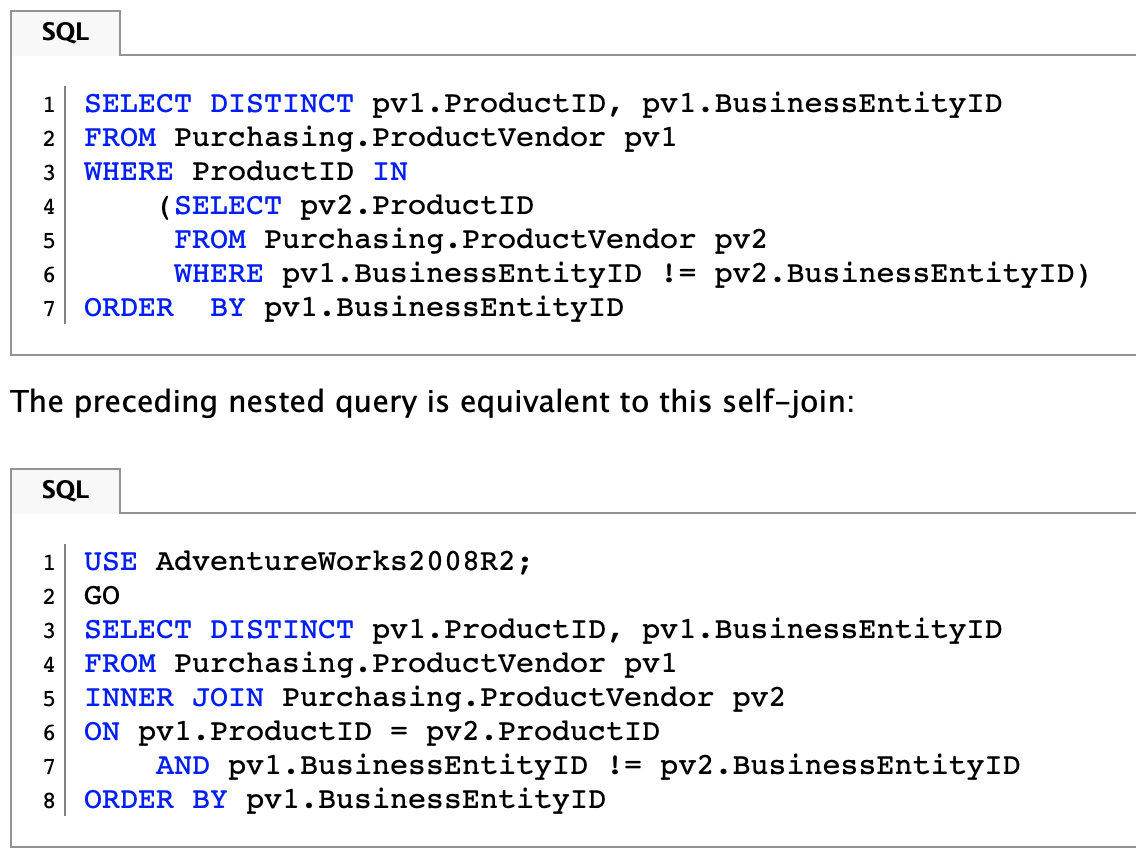
Example of JOIN子句示例。來源:Ubitsoft。
7. 避免*式查詢
每個查詢的最終目標都是為了高效地檢索到相關數據。但是,在創建查詢時,如果采用的是SELECT *子句,則通常會導致檢索各種并不相關的大量數據。如果目標數據集的體量較小,此類影響并不明顯;而在處理大型數據集時,該影響則會非常巨大。因此,為了優化查詢速度,并減少系統資源的消耗,我們應盡量減少查詢的數據量。通常,您可以使用如下代碼段中的LIMIT子句,來限制查詢結果的輸出。當然,如果確實需要檢索并查詢整個數據集,您仍然可以使用SELECT *的方式。

LIMIT子句的示例。來源:TechontheNet
小結
對Web開發人員來說,優化數據庫并不簡單,而且往往無法一蹴而就。不過,通過反復的試驗與調試,相信您一定能夠通過上述給出的七項技巧,提高目標數據庫的性能和查詢效率。當然,值得注意的是:在采取任何調優之前,請您做好數據庫的備份工作,以便按需恢復到先前的狀態。
原文標題:7 Database Optimization Hacks for Web Developers,作者:Kristina Tuvikene
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】





















