單塊GPU實現4K每秒30幀,實時視頻摳圖再升級毛發細節到位
實時運行、使用單塊英偉達 RTX 2080 TI GPU 即可以實現 HD 60fps 和 4K 30fps 的速度,那個「讓整個世界都變成你的綠幕」的摳圖方法 Background Matting 發布了 2.0 版本,為用戶提供了更自然更快速的實時背景替換效果。
背景替換是電影特效中的關鍵一環,在 Zoom、Google Meet 和 Microsoft Teams 等視頻會議工具中得到廣泛應用。除了增加娛樂效果之外,背景替換可以增強隱私保護,特別是用戶不愿在視頻會議中向他人分享自身位置以及環境等細節時。而這面臨著一項關鍵挑戰:視頻會議工具的用戶通常無法獲得電影特效背景替換所使用的綠幕或其他物理條件。
為了使用戶更方便地替換背景,研究人員陸續開發了一系列摳圖方法。今年 4 月份,華盛頓大學研究者提出了 background matting 方法,不在綠幕前拍攝也能完美轉換視頻背景,讓整個世界都變成你的綠幕。但是,這項研究無法實現實時運行,只能以低幀率處理低分辨率下(512×512)的背景替換,有很多需要改進的地方。
八個月過去,這些研究者推出了 background matting 2.0 版本,并表示這是一種完全自動化、實時運行的高分辨率摳圖方法,分別以 30fps 的幀率在 4k(3840×2160)和 60fps 的幀率在 HD(1920×1080)圖像上實現 SOTA 結果。
先來看一些效果展示場景:
非常自然流暢的背景替換。
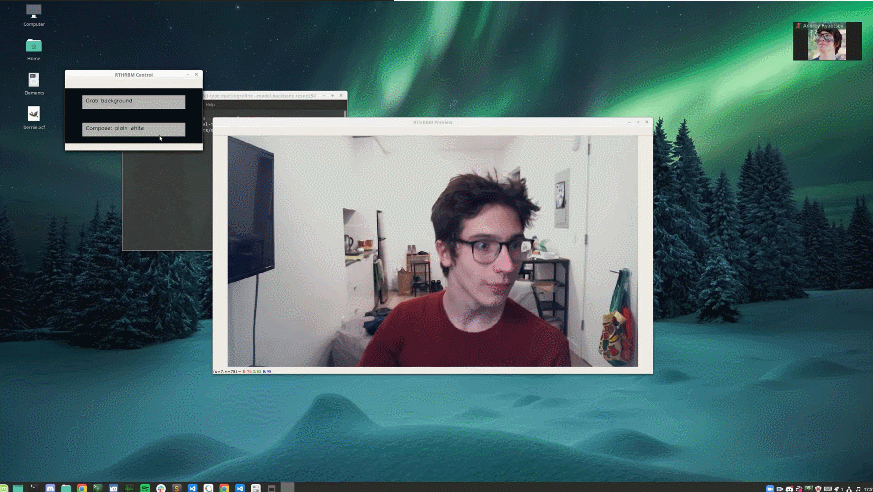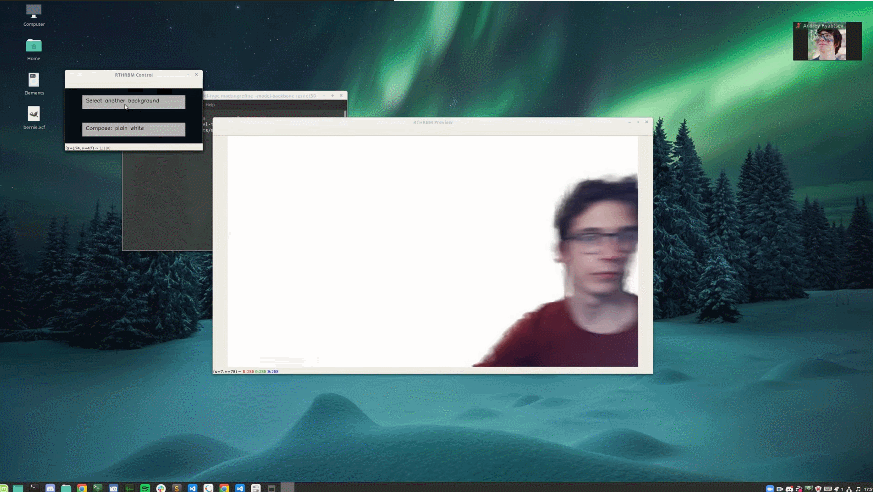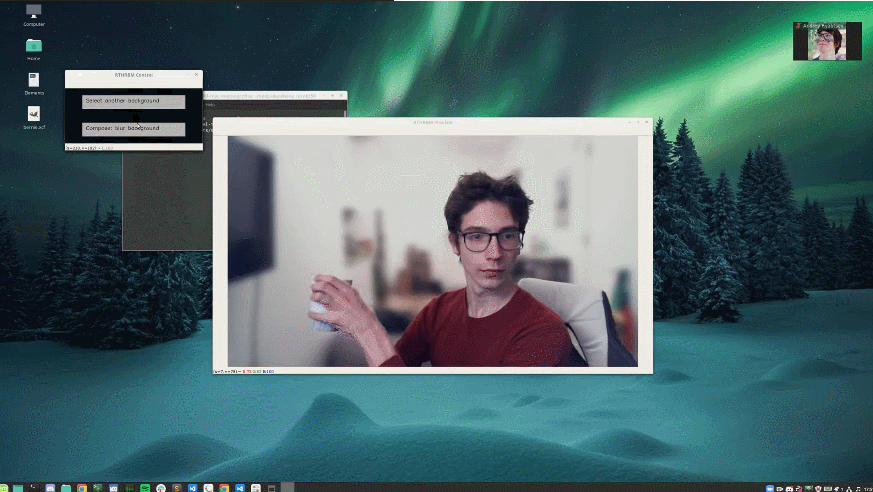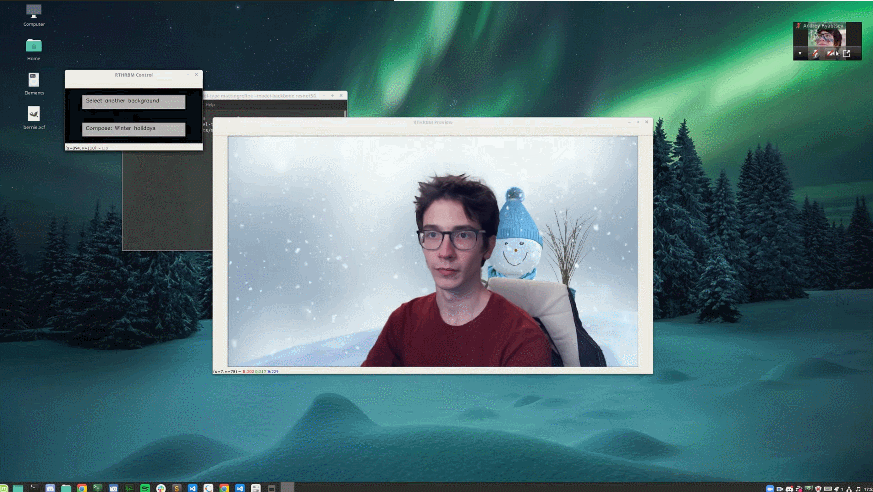
這位小哥將自己亂糟糟的房間背景替換成了下雪場景。
不過該方法也有「翻車」的時候,在下圖替換背景中都出現了明顯的銳化陰影(sharp shadow)。

Background Matting 2.0 版本有哪些改進?
Background Matting 2.0 相較 1.0 版本有哪些技術改進呢?我們都知道,設計一個對高分辨率人物視頻進行實時摳圖的神經網絡極具挑戰性,特別是頭發等細粒度細節特別重要的情況。1.0 版本只能以 8fps 的幀率實現 512×512 分辨率下的背景替換。若要在 4K 和 HD 這樣的大分辨率圖像上訓練深度網絡,則運行會非常慢,需要的內存也很大。此外,它還需要大量具備高質量前景蒙版(alpha matte)的圖像以實現泛化,然而公開可用的數據集也很有限。
收集具有大量手動制作前景蒙版的高質量數據集難度很大,因此該研究想要通過一系列具有不同特性的數據集來訓練網絡。為此,他們創建了兩個數據集 VideoMatte240K 和 PhotoMatte13K/85,二者均包含高分辨率前景蒙版以及利用色度鍵軟件提取的前景層。研究者首先在這些包含顯著多樣化人體姿勢的較大型前景蒙版數據集上訓練網絡以學習魯棒性先驗,然后在手動制作的公開可用數據集上繼續訓練以學習細粒度細節。
此外,為了設計出能夠實時處理高分辨率圖像的網絡,研究者觀察發現圖像中需要細粒度細化的區域相對很少。所以他們提出了一個 base 網絡,用來預測低分辨率下的前景蒙版和前景層,并得到誤差預測圖(以確定哪些圖像區域需要高分辨率細化)。然后 refinement 網絡以低分辨率結果和原始圖像作為輸入,在選定區域生成高分辨率輸出。
結果表明,Background Matting 2.0 版本在具有挑戰性的真實視頻和人物圖像場景中取得了 SOTA 的實時背景摳圖結果。研究者還將公布 VideoMatte240K 和 PhotoMatte85 數據集以及模型實現代碼。
- 論文地址:https://arxiv.org/pdf/2012.07810.pdf
- 項目主頁:https://grail.cs.washington.edu/projects/background-matting-v2/
數據集
該研究使用了多個數據集,包括研究人員創建的新型數據集和公共數據集。
公共數據集
Adobe Image Matting(AIM)數據集提供了 269 個人類訓練樣本和 11 個測試樣本,平均分辨率約為 1000×1000。該研究還使用了 Distinctions646 數據集的 humans-only 子集,包含 362 個訓練樣本和 11 個測試樣本,平均分辨率約為 1700×2000。這些數據集中蒙版均為手動創建,因此質量較高。但訓練樣本數量較少,無法學習多樣化的人類姿勢和高分辨率圖像的精細細節,于是研究人員創建了兩個新的數據集。
新型數據集 VideoMatte240K 和 PhotoMatte13K/85
VideoMatte240K 數據集:研究者收集了 484 個高分辨率綠幕視頻(其中 384 個視頻為 4K 分辨率,100 個 HD 分辨率),并使用色度鍵工具 Adobe After Effects 生成 240709 個不同的前景蒙版和前景幀。
PhotoMatte13K/85 數據集:研究人員收集了 13665 張圖像,這些圖像是用演播室質量的照明和相機在綠幕前拍攝的,并通過帶有手動調整和誤差修復的色度鍵算法提取蒙版。
下圖展示了這兩個數據集中的樣本示例:

方法
給定圖像 I 和捕獲背景 B,該研究提出的方法能夠預測前景蒙版 α 和前景 F。
具體而言,該方法通過 I'= αF + (1−α)B' 基于新背景進行合成(B' 為新背景)。該方法沒有直接求解前景,而是求解前景殘差 F^R = F − I。然后通過向輸入圖像 I 添加 F^R 來恢復 F:F = max(min(F^R + I, 1), 0)。研究人員發現該公式可以改善學習效果,并允許通過上采樣將低分辨率前景殘差應用到高分辨率輸入圖像上。
使用深層網絡會直接導致大量計算和內存消耗,因此高分辨率圖像摳圖極具挑戰性。如圖 4 所示,人類蒙版通常非常稀疏,其中大塊像素區域屬于背景(α=0)或前景(α=1),只有少數區域包含較精細的細節(如頭發、眼鏡、人體輪廓)。因此該研究沒有設計在高分辨率圖像上直接運行的網絡,而是提出了兩個網絡:一個基于較低分辨率圖像運行,另一個基于先前網絡的誤差預測圖選擇圖像塊(patch),僅在這些圖像塊上以原始分辨率運行。

該架構包含 base 網絡 G_base 和 refinement 網絡 G_refine。
給出原始圖像 I 和捕捉背景圖 B,該方法首先使用因子 c 對圖像 I 和 B 執行下采樣,得到 I_c 和 B_c。然后 base 網絡 G_base 以 I_c 和 B_c 為輸入,預測粗粒度前景蒙版 α_c、前景殘差 F^R_c、誤差預測圖 E_c 和隱藏特征 H_c。緊接著 refinement 網絡 G_refine 使用 H_c、I 和 B 在預測誤差 E_c 較大的區域中細化 α_c 和 F^R_c,得到原始分辨率的蒙版 α 和前景殘差 F^R。
該模型為全卷積模型,可以處理任意大小和長寬比的圖像。
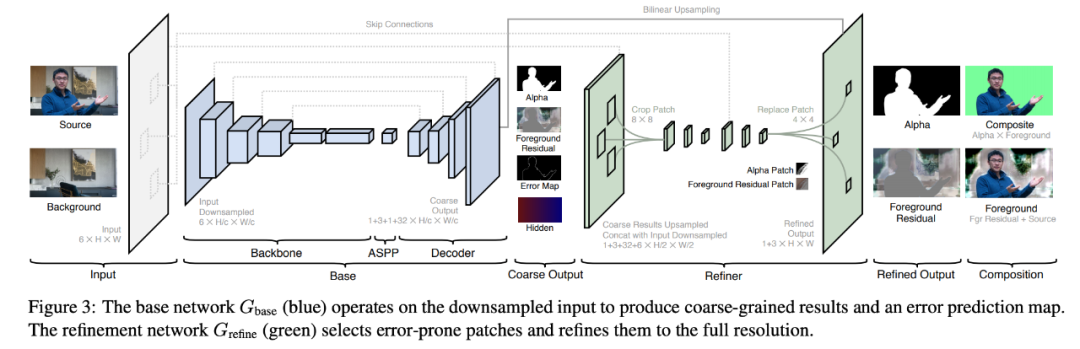
架構圖。
base 網絡
該方法的 base 網絡是一個受 DeepLabV3 和 DeepLabV3+ 啟發的全卷積編碼器 - 解碼器網絡,包含三個主要模塊:骨干網絡、ASPP 和解碼器。
研究者采用 ResNet-50 作為編碼器骨干網絡,它可以被替換為 ResNet-101 和 MobileNetV2 以實現速度和質量之間的權衡。
和 DeepLabV3 方法一樣,該方法在骨干網絡之后采用了 ASPP(空洞空間金字塔池化)模塊,該模塊包含多個空洞卷積濾波器,擴張率分別為為 3、6、9。
解碼器網絡在每一步均使用了雙線性上采樣,結合來自骨干網絡的殘差連接(skip connection),并使用 3×3 卷積、批歸一化和 ReLU 激活函數(最后一層除外)。解碼器網絡輸出粗粒度的前景蒙版 α_c、前景殘差 F^R_c、誤差預測圖 E_c 和 32 通道的隱藏特征 H_c。H_c 包含的全局語境將用于 refinement 網絡中。
refinement 網絡
refinement 網絡的目標是減少冗余計算并恢復高分辨率的摳圖細節。base 網絡在整個圖像上運行,而 refinement 網絡僅在基于誤差預測圖 E_c 選擇的圖像塊上運行。refinement 網絡包括兩個階段:先以原始分辨率的 1/2 進行細化,再用全分辨率細化。在推斷過程中,該方法細化 k 個圖像塊,k 可以提前設置,也可以基于權衡圖像質量和計算時間的閾值進行設置。
實驗
該研究將這一方法與基于 trimap 的兩種方法 Deep Image Matting、FBA Matting (FBA) 和基于背景圖像的方法 Background Matting (BGM) 進行對比。
在合成數據集上的評估結果
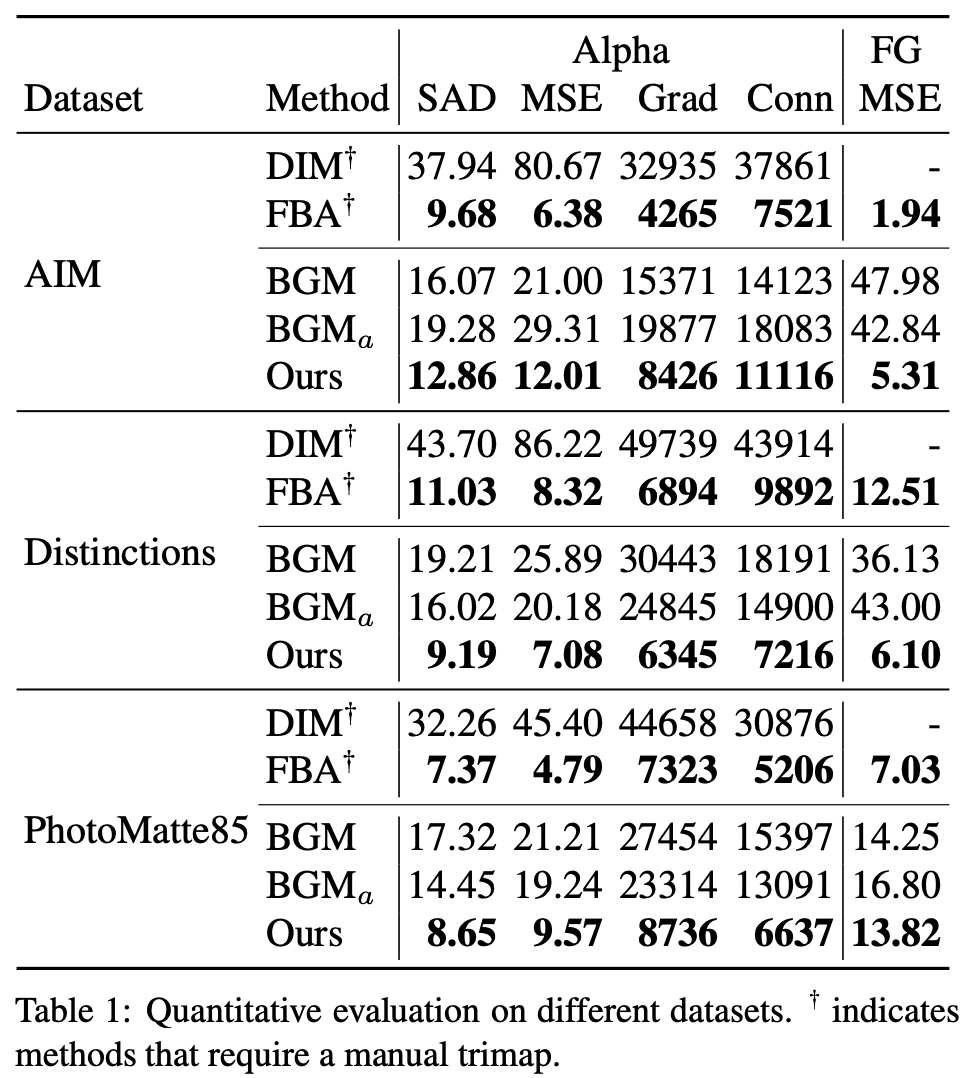
下表 1 展示了這些方法在不同數據集上的量化評估結果。從中可以看出,該研究提出的方法在所有數據集上均優于基于背景的 BGM 方法,但略遜于當前最優的 trimap 方法 FBA,FBA 需要人工精心標注的 trimap 且速度比該研究提出的方法慢。
在現實數據上的評估結果
該研究還對比了這些方法在真實數據上的性能。從下圖中可以看出,該研究方法的生成結果在頭發和邊緣方面更加清晰和詳細。

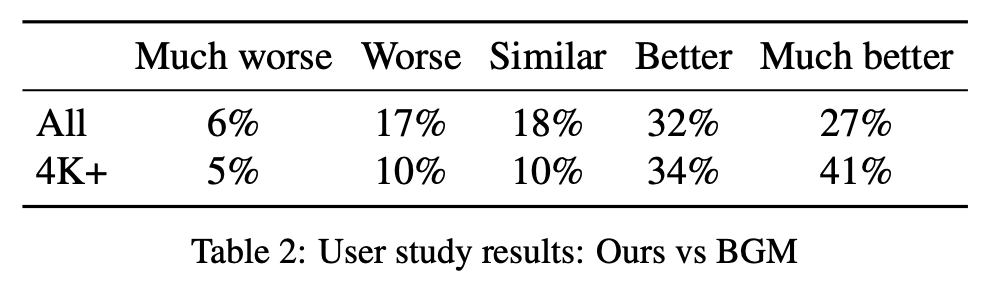
該研究邀請 40 位參與者評估該方法與 BGM 的生成效果,結果參見下表 2。從中可以看出該方法較 BGM 有顯著提升。59% 的參與者認為該算法更好,而認為 BGM 更好的參與者比例僅為 23%。在 4K 及更高分辨率的樣本中,認為該方法更好的參與者比例更是高達 75%。
性能對比
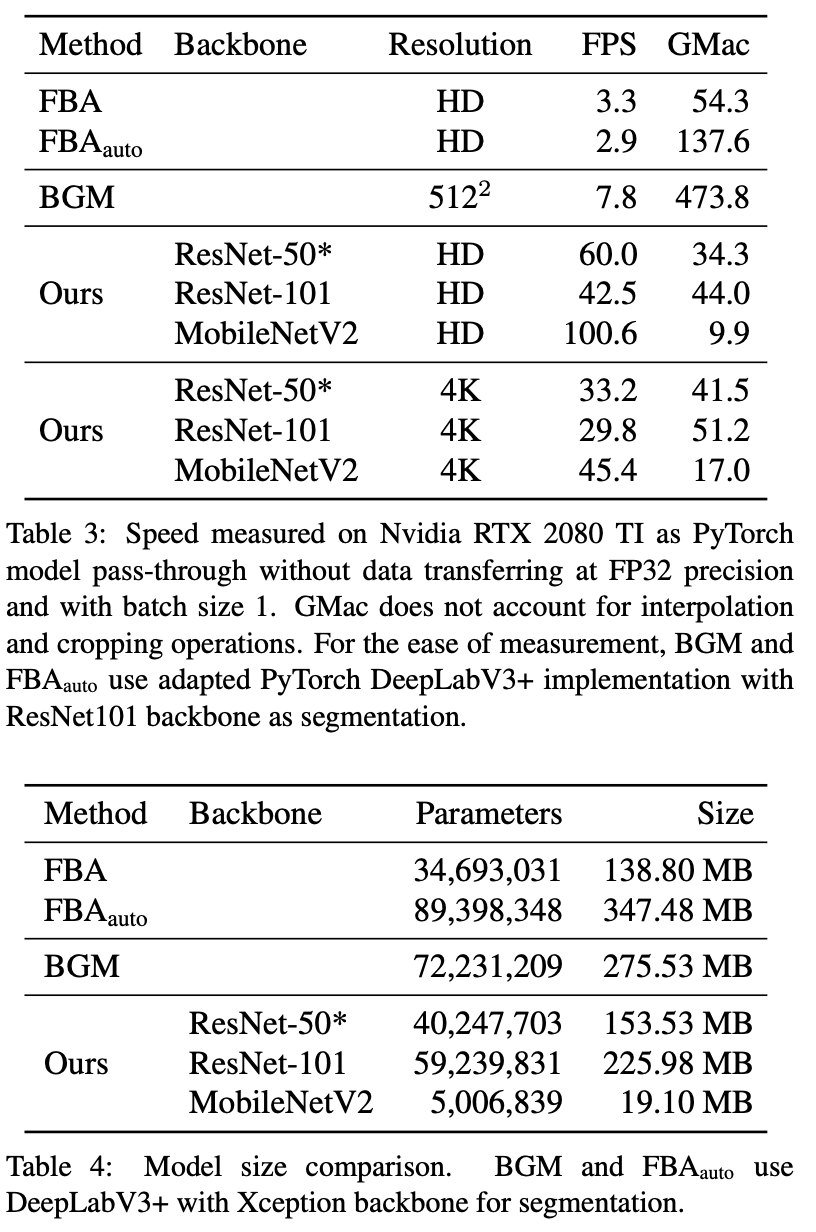
下表 3 和表 4 表明該方法比 BGM 小但速度更快。
該方法的參數量僅為 BGM 的 55.7% 。但它在批大小為 1 的情況下,使用一塊英偉達 RTX 2080 TI GPU 就能夠實現 HD 60fps 和 4K 30fps 的速度,可用于很多實時應用。相比之下,BGM 只能以 7.8fps 的速度處理 512×512 分辨率圖像。
將該方法的骨干網絡換成 MobileNetV2 后,其性能得到了進一步提升,實現了 HD 100fps 和 4K 45fps。
實際使用
研究人員將此方法應用到了 Zoom 視頻會議和摳圖這兩種場景中。
在 Zoom 實現中,研究人員構建了攔截攝像頭輸入的 Zoom 插件,收集一張無人的背景圖,然后執行實時視頻摳圖和合成,在 Zoom 會議中展示結果。研究人員使用 720p 攝像頭在 Linux 中進行了測試,實際效果很好。
此外,研究人員對比了該方法和綠幕色度摳圖的效果,發現在光照不均勻的環境下,該方法的效果勝過專為綠幕設計的方法,如下圖所示: