前端進(jìn)階: 總結(jié)幾個(gè)常用的JS搜索算法和性能對(duì)比
前言
今天讓我們來繼續(xù)聊一聊js算法,通過接下來的講解,我們可以了解到搜索算法的基本實(shí)現(xiàn)以及各種實(shí)現(xiàn)方法的性能,進(jìn)而發(fā)現(xiàn)for循環(huán),forEach,While的性能差異,我們還會(huì)了解到如何通過web worker做算法分片,極大的提高算法的性能。
同時(shí)我還會(huì)簡單介紹一下經(jīng)典的二分算法,哈希表查找算法,但這些不是本章的重點(diǎn),之后我會(huì)推出相應(yīng)的文章詳細(xì)介紹這些高級(jí)算法,感興趣的朋友可以關(guān)注我的專欄,或一起探討。
對(duì)于算法性能,我們還是會(huì)采用上一章《前端算法系列》如何讓前端代碼速度提高60倍中的getFnRunTime函數(shù),大家感興趣的可以查看學(xué)習(xí),這里我就不做過多說明。
在上一章《前端算法系列》如何讓前端代碼速度提高60倍我們模擬了19000條數(shù)據(jù),這章中為了讓效果更明顯,我將偽造170萬條數(shù)據(jù)來測試,不過相信我,對(duì)js來說這不算啥。。。
1.for循環(huán)搜索
- 基本思路:通過for循環(huán)遍歷數(shù)組,找出要搜索的值在數(shù)組中的索引,并將其推進(jìn)新數(shù)組
代碼實(shí)現(xiàn)如下:
- const getFnRunTime = require('./getRuntime');
- /**
- * 普通算法-for循環(huán)版
- * @param {*} arr
- * 耗時(shí):7-9ms
- */
- function searchBy(arr, value) {
- let result = [];
- for(let i = 0, len = arr.length; i < len; i++) {
- if(arr[i] === value) {
- result.push(i);
- }
- }
- return result
- }
- getFnRunTime(searchBy, 6)
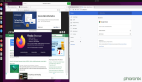
測試n次穩(wěn)定后的結(jié)果如圖:

2.forEach循環(huán)
基本思路和for循環(huán)類似:
- /**
- * 普通算法-forEach循環(huán)版
- * @param {*} arr
- * 耗時(shí):21-24ms
- */
- function searchByForEach(arr, value) {
- let result = [];
- arr.forEach((item,i) => {
- if(item === value) {
- result.push(i);
- }
- })
- return result
- }
耗時(shí)21-24毫秒,可見性能不如for循環(huán)(先暫且這么說哈,本質(zhì)也是如此)。
3.while循環(huán)
代碼如下:
- /**
- * 普通算法-while循環(huán)版
- * @param {*} arr
- * 耗時(shí):11ms
- */
- function searchByWhile(arr, value) {
- let i = arr.length,
- result = [];
- while(i) {
- if(arr[i] === value) {
- result.push(i);
- }
- i--;
- }
- return result
- }
可見while和for循環(huán)性能差不多,都很優(yōu)秀,但也不是說forEach性能就不好,就不使用了。foreach相對(duì)于for循環(huán),代碼減少了,但是foreach依賴IEnumerable。在運(yùn)行時(shí)效率低于for循環(huán)。但是在處理不確定循環(huán)次數(shù)的循環(huán),或者循環(huán)次數(shù)需要計(jì)算的情況下,使用foreach比較方便。而且foreach的代碼經(jīng)過編譯系統(tǒng)的代碼優(yōu)化后,和for循環(huán)的循環(huán)類似。
4.二分法搜索
二分法搜索更多的應(yīng)用場景在數(shù)組中值唯一并且有序的數(shù)組中,這里就不比較它和for/while/forEach的性能了。
- 基本思路:從序列的中間位置開始比較,如果當(dāng)前位置值等于要搜索的值,則查找成功;若要搜索的值小于當(dāng)前位置值,則在數(shù)列的前半段中查找;若要搜索的值大于當(dāng)前位置值則在數(shù)列的后半段中繼續(xù)查找,直到找到為止
代碼如下:
- /**
- * 二分算法
- * @param {*} arr
- * @param {*} value
- */
- function binarySearch(arr, value) {
- let min = 0;
- let max = arr.length - 1;
- while (min <= max) {
- const mid = Math.floor((min + max) / 2);
- if (arr[mid] === value) {
- return mid;
- } else if (arr[mid] > value) {
- max = mid - 1;
- } else {
- min = mid + 1;
- }
- }
- return 'Not Found';
- }
在數(shù)據(jù)量很大的場景下,二分法效率很高,但不穩(wěn)定,這也是其在大數(shù)據(jù)查詢下的一點(diǎn)小小的劣勢。
5.哈希表查找
- 哈希表查找又叫散列表查找,通過查找關(guān)鍵字不需要比較就可以獲得需要記錄的存儲(chǔ)位置,它是通過在記錄的存儲(chǔ)位置和它的關(guān)鍵字之間建立一個(gè)確定的對(duì)應(yīng)關(guān)系f,使得每個(gè)關(guān)鍵字key對(duì)應(yīng)一個(gè)存儲(chǔ)位置f(key)
哈希表查找的使用場景:
- 哈希表最適合的求解問題是查找與給定值相等的記錄
- 哈希查找不適合同樣的關(guān)鍵字對(duì)應(yīng)多條記錄的情況
- 不適合范圍查找,比如查找年齡18~22歲的同學(xué)
在這我先給出一個(gè)最簡版的hashTable,方便大家更容易的理解哈希散列:
- /**
- * 散列表
- * 以下方法會(huì)出現(xiàn)數(shù)據(jù)覆蓋的問題
- */
- function HashTable() {
- var table = [];
- // 散列函數(shù)
- var loseloseHashCode = function(key) {
- var hash = 0;
- for(var i=0; i<key.length; i++) {
- hash += key.charCodeAt(i);
- }
- return hash % 37
- };
- // put
- this.put = function(key, value) {
- var position = loseloseHashCode(key);
- table[position] = value;
- }
- // get
- this.get = function(key) {
- return table[loseloseHashCode(key)]
- }
- // remove
- this.remove = function(key) {
- table[loseloseHashCode(key)] = undefined;
- }
- }
該方法可能會(huì)出現(xiàn)數(shù)據(jù)沖突的問題,不過也有解決方案,由于這里涉及的知識(shí)點(diǎn)比較多,后期我會(huì)專門推出一篇文章來介紹:
- 開放定址法
- 二次探測法
- 隨機(jī)探測法
使用web worker優(yōu)化
通過以上的方法,我們已經(jīng)知道各種算法的性能和應(yīng)用場景了,我們?cè)谑褂盟惴〞r(shí),還可以通過web worker來優(yōu)化,讓程序并行處理,比如將一個(gè)大塊數(shù)組拆分成多塊,讓web worker線程幫我們?nèi)ヌ幚碛?jì)算結(jié)果,最后將結(jié)果合并,通過worker的事件機(jī)制傳給瀏覽器,效果十分顯著。
總結(jié)
- 對(duì)于復(fù)雜數(shù)組查詢,for/while性能高于forEach等數(shù)組方法
- 二分查找法的O(logn)是一種十分高效的算法。不過它的缺陷也很明顯:必須有序,我們很難保證我們的數(shù)組都是有序的。當(dāng)然可以在構(gòu)建數(shù)組的時(shí)候進(jìn)行排序,可是又落到了第二個(gè)瓶頸上:它必須是數(shù)組。數(shù)組讀取效率是O(1),可是它的插入和刪除某個(gè)元素的效率卻是O(n)。因而導(dǎo)致構(gòu)建有序數(shù)組的時(shí)候會(huì)降低效率。
- 哈希表查找的基本用法及使用場景。
- 條件允許的話,我們可以用web worker來優(yōu)化算法,讓其在后臺(tái)并行執(zhí)行。
好啦,這篇文章雖然比較簡單,但十分重要,希望大家對(duì)搜索算法有更加直觀的認(rèn)識(shí),也希望大家有更好的方法,一起探討交流。