帶你從不同角度了解強化學習算法的分類
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)。
本文將介紹強化學習算法的分類法,從多種不同角度學習幾種分類法。話不多說,大家深呼吸,一起來學習RL算法的分類吧!
無模型(Model-Free)VS基于模型(Model-Based)
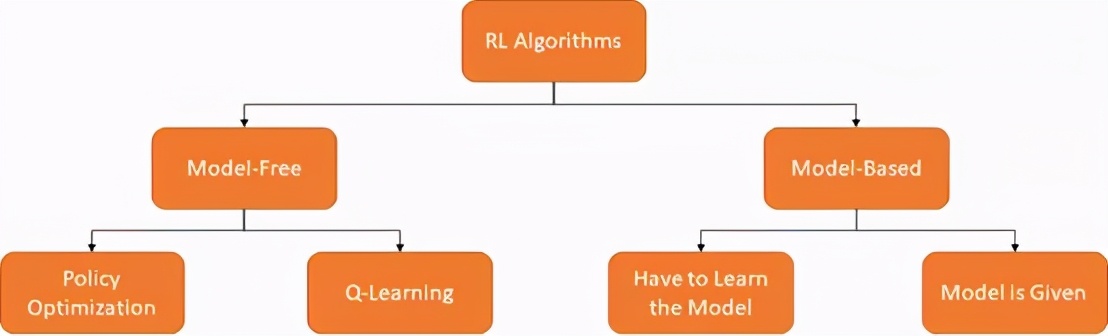
無模型VS模型分類法 [圖源:作者,OpenAISpinning Up再創作]
RL算法的一種分類方法是詢問代理是否能訪問環境模型。換言之,詢問環境會否響應代理的行為。基于這個觀點有兩個RL算法的分支:無模型和基于模型。
- 模型RL算法根據環境的學習模型來選擇最佳策略。
- 無模型RL算法通過代理反復測試選擇最佳策略。
兩種算法都各有優缺點,如下表所示:

基于價值VS 基于政策
RL算法的另一種分類方法是考慮算法優化了價值函數還是策略。在深入了解之前,我們先了解策略和價值功能。
(1) 策略
策略π是從狀態s到動作a的映射,其中π(a | s)是在狀態s時采取動作a的概率。策略可以是確定的,也可以是隨機的。
假設我們在玩剪刀石頭布這個非常簡單的游戲,兩個人通過同時執行三個動作(石頭/剪刀/布)中的一個來比輸贏。規則很簡單:
- 剪刀克布
- 石頭克剪刀
- 布克石頭
把策略看作是迭代的剪刀石頭布
- 確定性策略容易被利用-如果我意識到你出“石頭”較多,那么我可以利用這一點,獲得更大贏面。
- 統一的隨機策略(uniform random policy)最佳—如果你的選擇完全隨機,那我就不知道該采取什么行動才能取勝。
(2) 價值函數
價值函數是根據對未來回報(返回值)的預測來衡量狀態良好程度的函數。返回值(Gt)基本等于“折扣”回報的總和(自t時起)。
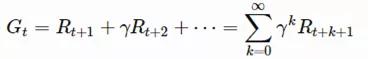
γ ∈ [0,1]是折扣因數。折扣因數旨在抵扣未來的回報,有以下幾個原因:
- 方便數學計算
- 打破狀態變化圖中的無限循環
- 未來回報的高度不確定性(比如股價變化)
- 未來回報不能立時受益(比如人們更愿意當下享樂而非十年后)
了解了返回值的概念后,接下來定義價值函數的數學形式吧!
價值函數的數學形式有二:
狀態-動作價值函數(Q值)是t時狀態動作組合下的期望返回值:
Q值和價值函數之間的區別是動作優勢函數(通常稱為A值):
現在知道了什么是價值函數和動作-狀態價值函數。接下來學習有關RL算法另一個分支的更多信息,該分支主要關注算法優化的組件。
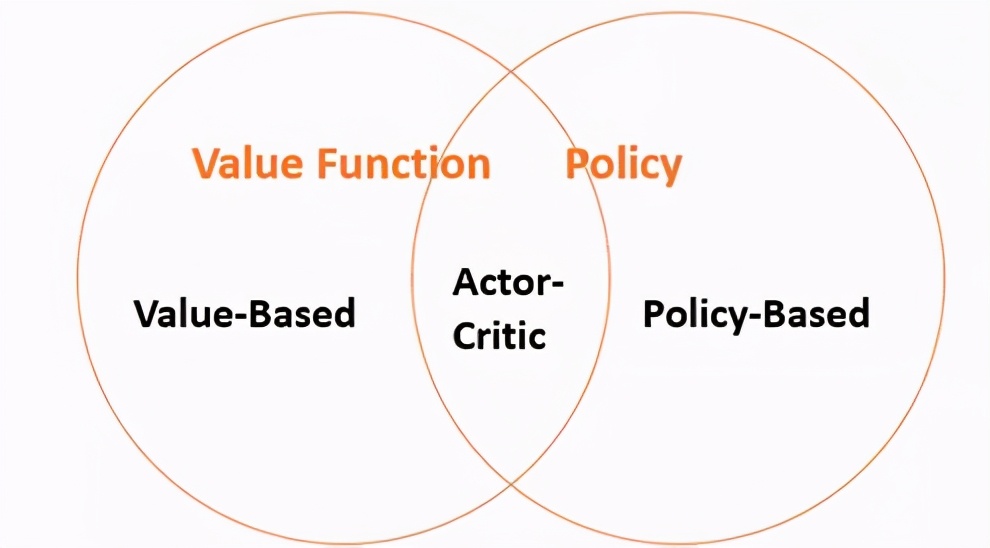
價值算法與策略算法[圖源:作者,David Silver RL課程再創作]
- 價值RL旨在學習價值/行動-價值函數,以生成最佳策略(即,隱式生成最佳策略);
- 策略RL旨在使用參數化函數直接學習策略。
- Actor-Critic RL旨在學習價值函數和策略。
下表列出了價值和策略算法的優缺點。

- 價值算法必須選擇使動作-狀態價值函數最大的動作,如果動作空間非常高維或連續,成本就會很高,而策略算法是通過直接調整策略的參數來運行的,不需要進行最大化計算。
- 如果操作不當 (收斂性質差/不穩定),價值算法會出現一系列問題,而策略算法更穩定,收斂性質更好,因為它們只對策略梯度進行很少的增量更改。
- 策略算法既可以學習確定性策略,也可以學習隨機策略,而價值算法只能學習確定性策略。
- 與價值算法相比,原本的策略算法速度更慢,方差更大。價值算法試圖選擇使動作-狀態價值函數最大化的動作,這將優化策略 (運算更快、方差更小),策略算法只需幾步,并且更新順暢、穩定,但同時效率較低,有時會導致方差變大。
- 策略算法通常收斂于局部最優而不是全局最優。
策略和非策略算法
還有一種RL算法分類方法是基于策略來源分類。
可以說策略算法是“邊做邊學”。也就是說該算法試著從π采樣的經驗中了解策略π。而非策略算法是通過“監視”的方式來工作。換句話說,該算法試圖從μ采樣的經驗中了解策略π。例如,機器人通過觀察人類的行為來學習如何操作。