MySQL查詢性能優化前,必須先掌握MySQL索引理論
數據庫索引在平時的工作是必備的,怎么建好索引,怎么使用索引,可以提高數據的查詢效率。而且在面試過程,數據庫的索引也是必問的知識點,比如:
索引底層結構選型,那為什么選擇B+樹?
不同存儲引擎的索引的體現形式有哪些?
索引的類型
- 組合索引存儲方式
- 查詢方式
- 最左前綴匹配原則
覆蓋索引是什么?
看著這些,能說出多少,理解多少呢?因此我們需要去探究其內在原理。

那索引是什么?
索引的目的為了加速檢索數據而設計的一種分散存儲(索引常常很大,屬于硬盤級的東西,所以是分散存儲)的數據結構,其原理以空間換時間。
快速檢索的實現的本質是數據結構,通過不同數據結構的選擇,實現各種數據快速檢索,索引有哈希索引和B+樹索引。
索引底層結構選型,那為什么選擇B+樹?
數據庫索引底層選型歸根到底就是為提高檢索效率,那么就需要考慮幾個問題:
- 算法時間復雜度
- 是否存在排序
- 磁盤IO與預讀
NOTE: 考慮到磁盤IO是非常高昂的操作,計算機操作系統做了一些優化,當一次IO時,不光把當前磁盤地址的數據,而是把相鄰的數據也都讀取到內存緩沖區內,因為局部預讀性原理告訴我們,當計算機訪問一個地址的數據的時候,與其相鄰的數據也會很快被訪問到。每一次IO讀取的數據我們稱之為一頁(page)。
哈希表( Hash Table,散列表 )
哈希表是根據鍵(Key)而直接訪問在內存存儲位置的數據結構。
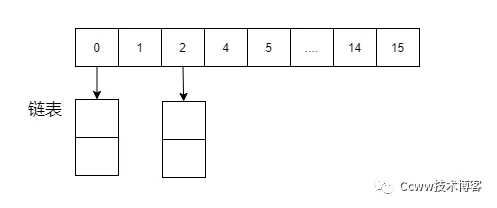
通過計算一個關于鍵值的函數,將所需查詢的數據映射到表中一個位置來訪問記錄,這加快了查找速度。雖然查詢時間復雜度為O(1),但存在著碰撞問題,最壞情況會導致時間復雜急劇增加;
而且哈希表其只適合精準key(等于)檢索,不適合范圍式檢索,范圍檢索就需要一次把所有數據找出來加載到內存,沒有效率,因此不適合Mysql的底層索引的數據結構。
普通的二叉查找樹
為了優化高效范圍查詢,且時間復雜度小,引入二叉查找樹
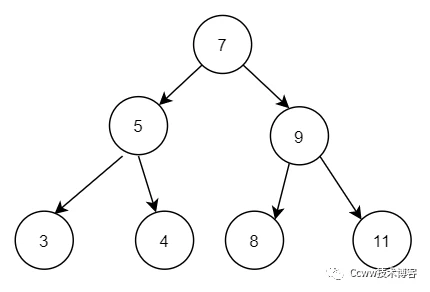
二叉查找樹的時間復雜度是 O(lgn),由于數據已排序好了,所以范圍查詢是可以高效查詢,
但會存在的問題:左右子節點的深度可能相差很大,最極端的情況只有左子樹或者右子樹,此時查找的效率為O(n),檢索性能急劇下降,因此也不適合Mysql的底層索引的數據結構。
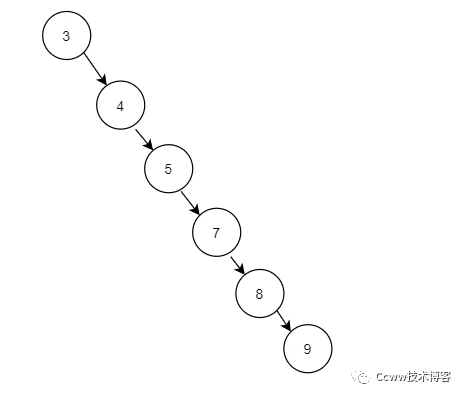
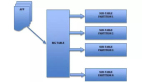
平衡二叉樹(AVL樹)
為了優化二叉樹左右子樹深度相差太大的問題,我們引入了平衡二叉樹,即左右子節點的深度差不超過1,平衡二叉樹看來好像適合,實現了:
- 范圍查找、數據排序
- 查詢性能良好O(logn)
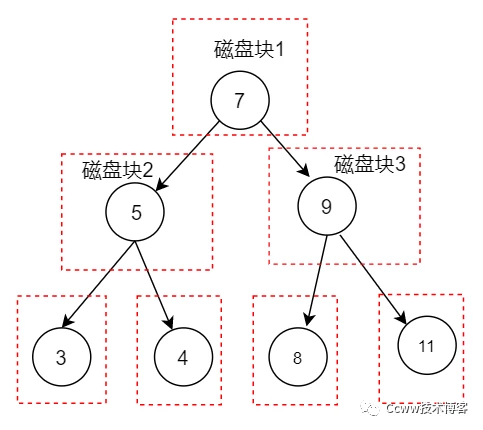
NOTE:上圖中一個磁盤塊,代表硬盤上的一個存儲位置
但是我們還有一個最重要因素需要考慮,磁盤IO與預讀,且數據庫查詢數據的瓶頸在于磁盤 IO,使用平衡二叉樹根據索引進行查找時,每讀一個磁盤塊就進行一次IO,這樣沒有實現計算機的預讀能力,導致檢索效率下降,總結出平衡二叉樹作為索引的問題
- 太深了(即它只有二條路),深度越大進行的IO操作也就越多
- 太小了,每一次IO才查詢磁盤塊這么一點數據,太浪費IO了。操作系統規定一次IO最小4K,Mysql一次IO 16K,而圖上的磁盤塊能明顯達不到4K
B+樹
為了優化磁盤IO和預讀,減少IO操作,條路太少了,那么換成多條路,那么會想到使用B樹和B+樹,但B樹每個節點限制最多存儲兩個 key,也會造成IO操作過于頻繁,因此優化思路為:盡可能在一次磁盤 IO 中多讀一點數據到內存,那么B+樹也該出場:
- B+樹一個節點能存很多索引,且只有B+樹葉子節點存儲數據
- 相鄰節點之間有一些前驅后繼關系
- 葉子節點是順序排列的
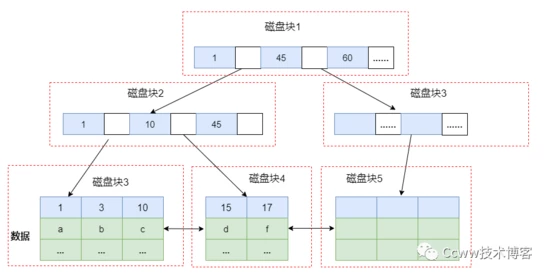
相對于B樹,B+樹的優勢有:
- B+樹掃庫掃表的能力更強
- B樹的數據是存放在每一個節點中的,節點所在的物理地址又是隨機的,所以掃表的話,進行的是隨機IO
- B+樹的數據是存放在葉子節點的,且在一個葉子節點中的數據是連續的,所以掃表的話,進行的相對的順序IO
- B+樹的磁盤讀寫能力更強,枝節點不保存數據,而保存更多的關鍵字。一次IO就能讀出更多的關鍵字
- B+樹的排序能力更強,B+樹的葉子節點存儲的數據是已經排好序的
索引的體現形式
索引在不同的存儲引擎中體現形式步一樣, 最常見的是:
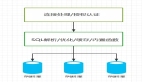
- Innodb 引擎中體現為聚集索引方式 (索引和數據是存放在同一個文件的)
- Myisam引擎中體現為非聚集索引方式 (索引和數據是存放在兩個文件中的)
聚集索引方式(InnoDB存儲引擎)
InnoDB存儲引擎中,索引和數據是存放在同一個文件的,屬于聚集索引 。而且InnoDB會自動建立好主鍵 ID 索引樹, 因此建表時要求必須指定主鍵的原因。
其中,主鍵索引(聚集索引)的葉子節點記錄了數據,而不是數據的物理地址。輔助索引的葉子節點存放的是主鍵key。所以當利用輔助索引查找數據時,實際上查了兩遍索引(輔助索引和主鍵索引):
- 先查詢輔助索引樹找出主鍵
- 然后在主鍵索引樹中根據主鍵查詢數據
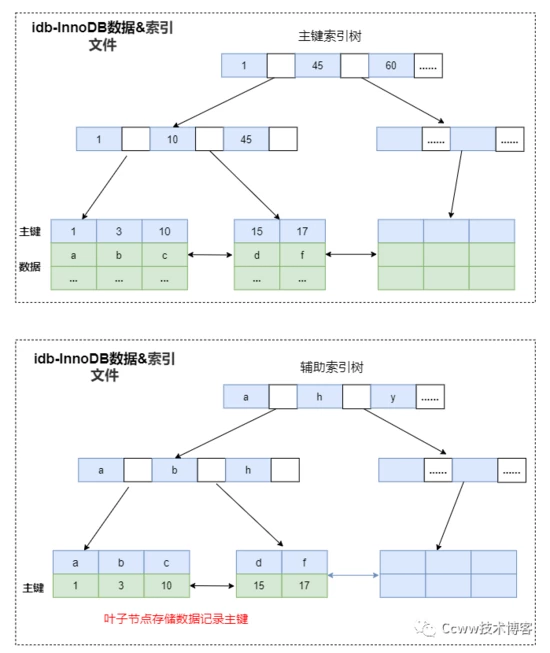
非聚集索引方式(Myisam存儲引擎)
Myisam存儲引擎中,索引和數據是存放在兩個文件中的,屬于非聚集索引 。不管是主鍵索引還是輔助索引,其葉子節點都是記錄了數據的物理地址。
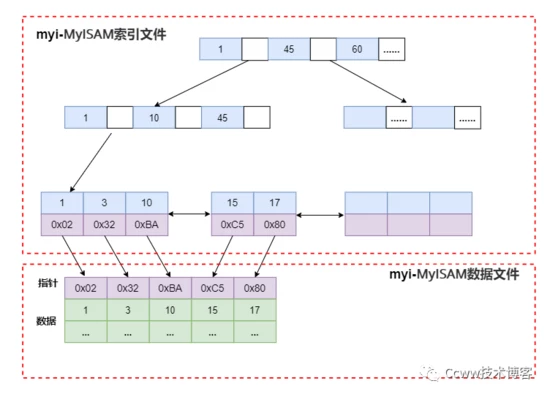
MySQL的索引類型
MySQL索引可以分為:
- 普通索引(index): 加速查找
唯一索引:
- 主鍵索引:primary key :加速查找+約束(不為空且唯一)
- 唯一索引:unique:加速查找+約束 (唯一)
聯合索引:
- primary key(id,name):聯合主鍵索引
- unique(id,name):聯合唯一索引
- index(id,name):聯合普通索引
全文索引full text :用于搜索很長一篇文章的時候,效果最好。
其中,主要理解一下聯合索引的問題,存儲結構,查詢方式。
聯合索引
聯合索引,多個列組成的索引叫做聯合索引,單列索引是特殊的聯合索引。其存儲結構如下:
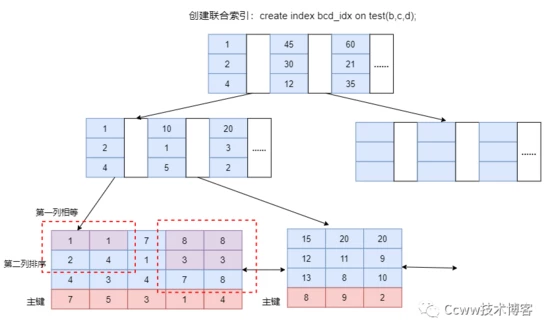
對于聯合索引來說其存儲結構只不過比單值索引多了幾列,組合索引列數據都記錄在索引樹上,(不同的組合索引,B+樹也是不同的),且存儲引擎會首先根據第一個索引列排序后,其他列再依次將相等值的進行排序。
NOTE:葉節點第一排,按順序排序好,第二列,會基于第一列排序好的,將第一列相等的再下一列再排序,依次類推。
聯合索引查詢方式,存儲引擎首先從根節點(一般常駐內存)開始查找,然后再依次在其他列中查詢,直到找到該索引下的data元素即ID值,再從主鍵索引樹上找到最終數據。
而且聯合索引其選擇的原則:
- 最左前綴匹配原則(經常使用的列優先)
- 離散度高的列優先
- 寬度小的列優先
最左前綴匹配原則
最左前綴匹配原則和聯合索引的索引構建方式及存儲結構是有關系的。根據上述理解分析,可以得出聯合索引只能從多列索引的第一列開始查找索引才會生效,比如:
- 假設表user上有個聯合索引(a,b,c),那么 select * from user where b = 1 and c = 2將不會命中索引
- 原因是聯合索引的是存儲引擎先按第一個字段排序,再按第二個字段排序,依次排序。
離散度
當索引中的一列離散度過低時,優化器可能直接不走索引,離散度計算方法:
- 離散度 = 列中不重復的數據量 / 這一列的總數據量
覆蓋索引
如果一個索引包含(或覆蓋)所有需要查詢的字段的值,稱為覆蓋索,即只需掃描索引而無須回表查詢 。覆蓋索引可減少數據庫IO,將隨機IO變為順序IO,可提高查詢性能。
對于InnoDB輔助索引在葉子節點中保存了行的主鍵值,所以如果輔助索引(包括聯合索引)能夠覆蓋查詢,則可以避免對主鍵索引的二次查詢。比如:
- --創建聯合索引
- create index name_phone_idx on user(name,phoneNum);
- --此時是覆蓋索引,原因是根據name來查,命中索引name_phone_idx,
- --其關鍵字為name,phoneNum,本身就已經包含了查詢的列。
- select name,phoneNum where name = "張三";
- --如果id為主鍵的話,此時也稱作覆蓋索引,原因:輔助索引的葉子節點存的就是主鍵
- select id,name,phoneNum where name = "張三";
總結
MySQL的索引有很多知識點要掌握,已學習了索引的底層存儲結構,不同存儲引擎中的索引體現,以及索引類型的基礎原理知識分析,可以為后續的數據庫優化提供理論知識的支撐,也會更好的理解優化方案。